 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Meanflow Training Curriculum
Apr 10, 2026Flow-based image generative models exhibit stable training and produce high quality samples when using multi-step sampling procedures. One-step generative models can produce high quality image samples but can be difficult to optimize as they often exhibit unstable training dynamics. Meanflow models exhibit excellent few-step sampling performance and tantalizing one-step sampling performance. Notably, MeanFlow models that achieve this have required extremely large training budgets. We significantly decrease the amount of computation and data budget it takes to train Meanflow models by noting and exploiting a particular discretization of the Meanflow objective that yields a consistency property which we formulate into a ``Discrete Meanflow'' (DMF) Training Curriculum. Initialized with a pretrained Flow Model, DMF curriculum reaches one-step FID 3.36 on CIFAR-10 in only 2000 epochs. We anticipate that faster training curriculums of Meanflow models, specifically those fine-tuned from existing Flow Models, drives efficient training methods of future one-step examples.
Post-Hoc Guidance for Consistency Models by Joint Flow Distribution Learning
Apr 10, 2026Classifier-free Guidance (CFG) lets practitioners trade-off fidelity against diversity in Diffusion Models (DMs). The practicality of CFG is however hindered by DMs sampling cost. On the other hand, Consistency Models (CMs) generate images in one or a few steps, but existing guidance methods require knowledge distillation from a separate DM teacher, limiting CFG to Consistency Distillation (CD) methods. We propose Joint Flow Distribution Learning (JFDL), a lightweight alignment method enabling guidance in a pre-trained CM. With a pre-trained CM as an ordinary differential equation (ODE) solver, we verify with normality tests that the variance-exploding noise implied by the velocity fields from unconditional and conditional distributions is Gaussian. In practice, JFDL equips CMs with the familiar adjustable guidance knob, yielding guided images with similar characteristics to CFG. Applied to an original Consistency Trained (CT) CM that could only do conditional sampling, JFDL unlocks guided generation and reduces FID on both CIFAR-10 and ImageNet 64x64 datasets. This is the first time that CMs are able to receive effective guidance post-hoc without a DM teacher, thus, bridging a key gap in current methods for CMs.
Beyond and Free from Diffusion: Invertible Guided Consistency Training
Feb 08, 2025
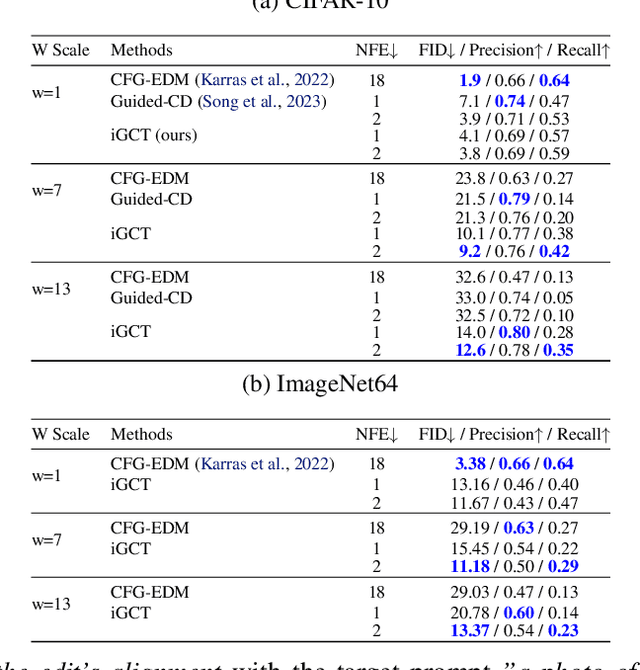

Guidance in image generation steers models towards higher-quality or more targeted outputs, typically achieved in Diffusion Models (DMs) via Classifier-free Guidance (CFG). However, recent Consistency Models (CMs), which offer fewer function evaluations, rely on distilling CFG knowledge from pretrained DMs to achieve guidance, making them costly and inflexible. In this work, we propose invertible Guided Consistency Training (iGCT), a novel training framework for guided CMs that is entirely data-driven. iGCT, as a pioneering work, contributes to fast and guided image generation and editing without requiring the training and distillation of DMs, greatly reducing the overall compute requirements. iGCT addresses the saturation artifacts seen in CFG under high guidance scales. Our extensive experiments on CIFAR-10 and ImageNet64 show that iGCT significantly improves FID and precision compared to CFG. At a guidance of 13, iGCT improves precision to 0.8, while DM's drops to 0.47. Our work takes the first step toward enabling guidance and inversion for CMs without relying on DMs.
Self-Correcting Self-Consuming Loops for Generative Model Training
Feb 11, 2024



As synthetic data becomes higher quality and proliferates on the internet, machine learning models are increasingly trained on a mix of human- and machine-generated data. Despite the successful stories of using synthetic data for representation learning, using synthetic data for generative model training creates "self-consuming loops" which may lead to training instability or even collapse, unless certain conditions are met. Our paper aims to stabilize self-consuming generative model training. Our theoretical results demonstrate that by introducing an idealized correction function, which maps a data point to be more likely under the true data distribution, self-consuming loops can be made exponentially more stable. We then propose self-correction functions, which rely on expert knowledge (e.g. the laws of physics programmed in a simulator), and aim to approximate the idealized corrector automatically and at scale. We empirically validate the effectiveness of self-correcting self-consuming loops on the challenging human motion synthesis task, and observe that it successfully avoids model collapse, even when the ratio of synthetic data to real data is as high as 100%.