 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEGS-POMDP: Language and Gesture-Guided Object Search in Partially Observable Environments
Mar 05, 2026To assist humans in open-world environments, robots must interpret ambiguous instructions to locate desired objects. Foundation model-based approaches excel at multimodal grounding, but they lack a principled mechanism for modeling uncertainty in long-horizon tasks. In contrast, Partially Observable Markov Decision Processes (POMDPs) provide a systematic framework for planning under uncertainty but are often limited in supported modalities and rely on restrictive environment assumptions. We introduce LanguagE and Gesture-Guided Object Search in Partially Observable Environments (LEGS-POMDP), a modular POMDP system that integrates language, gesture, and visual observations for open-world object search. Unlike prior work, LEGS-POMDP explicitly models two sources of partial observability: uncertainty over the target object's identity and its spatial location. In simulation, multimodal fusion significantly outperforms unimodal baselines, achieving an average success rate of 89\% across challenging environments and object categories. Finally, we demonstrate the full system on a quadruped mobile manipulator, where real-world experiments qualitatively validate robust multimodal perception and uncertainty reduction under ambiguous instructions.
LaNMP: A Language-Conditioned Mobile Manipulation Benchmark for Autonomous Robots
Nov 28, 2024


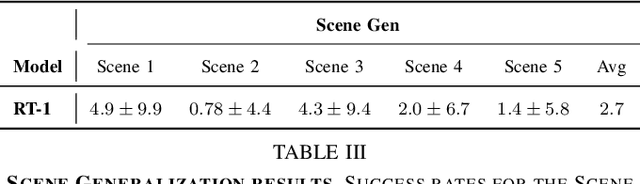
As robots that follow natural language become more capable and prevalent, we need a benchmark to holistically develop and evaluate their ability to solve long-horizon mobile manipulation tasks in large, diverse environments. To tackle this challenge, robots must use visual and language understanding, navigation, and manipulation capabilities. Existing datasets do not integrate all these aspects, restricting their efficacy as benchmarks. To address this gap, we present the Language, Navigation, Manipulation, Perception (LaNMP, pronounced Lamp) dataset and demonstrate the benefits of integrating these four capabilities and various modalities. LaNMP comprises 574 trajectories across eight simulated and real-world environments for long-horizon room-to-room pick-and-place tasks specified by natural language. Every trajectory consists of over 20 attributes, including RGB-D images, segmentations, and the poses of the robot body, end-effector, and grasped objects. We fine-tuned and tested two models in simulation, and evaluated a third on a physical robot, to demonstrate the benchmark's applicability in development and evaluation, as well as making models more sample efficient. The models performed suboptimally compared to humans; however, showed promise in increasing model sample efficiency, indicating significant room for developing more sample efficient multimodal mobile manipulation models using our benchmark.
SIFToM: Robust Spoken Instruction Following through Theory of Mind
Sep 17, 2024



Spoken language instructions are ubiquitous in agent collaboration. However, in human-robot collaboration, recognition accuracy for human speech is often influenced by various speech and environmental factors, such as background noise, the speaker's accents, and mispronunciation. When faced with noisy or unfamiliar auditory inputs, humans use context and prior knowledge to disambiguate the stimulus and take pragmatic actions, a process referred to as top-down processing in cognitive science. We present a cognitively inspired model, Speech Instruction Following through Theory of Mind (SIFToM), to enable robots to pragmatically follow human instructions under diverse speech conditions by inferring the human's goal and joint plan as prior for speech perception and understanding. We test SIFToM in simulated home experiments (VirtualHome 2). Results show that the SIFToM model outperforms state-of-the-art speech and language models, approaching human-level accuracy on challenging speech instruction following tasks. We then demonstrate its ability at the task planning level on a mobile manipulator for breakfast preparation tasks.
Open-vocabulary Pick and Place via Patch-level Semantic Maps
Jun 21, 2024Controlling robots through natural language instructions in open-vocabulary scenarios is pivotal for enhancing human-robot collaboration and complex robot behavior synthesis. However, achieving this capability poses significant challenges due to the need for a system that can generalize from limited data to a wide range of tasks and environments. Existing methods rely on large, costly datasets and struggle with generalization. This paper introduces Grounded Equivariant Manipulation (GEM), a novel approach that leverages the generative capabilities of pre-trained vision-language models and geometric symmetries to facilitate few-shot and zero-shot learning for open-vocabulary robot manipulation tasks. Our experiments demonstrate GEM's high sample efficiency and superior generalization across diverse pick-and-place tasks in both simulation and real-world experiments, showcasing its ability to adapt to novel instructions and unseen objects with minimal data requirements. GEM advances a significant step forward in the domain of language-conditioned robot control, bridging the gap between semantic understanding and action generation in robotic systems.
A Survey of Robotic Language Grounding: Tradeoffs Between Symbols and Embeddings
May 21, 2024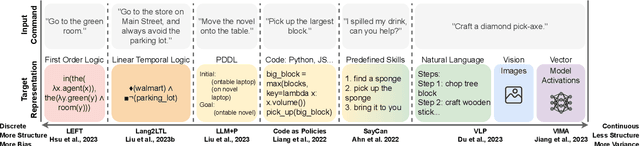

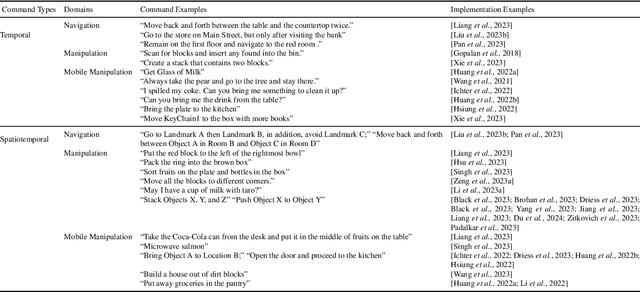
With large language models, robots can understand language more flexibly and more capable than ever before. This survey reviews recent literature and situates it into a spectrum with two poles: 1) mapping between language and some manually defined formal representation of meaning, and 2) mapping between language and high-dimensional vector spaces that translate directly to low-level robot policy. Using a formal representation allows the meaning of the language to be precisely represented, limits the size of the learning problem, and leads to a framework for interpretability and formal safety guarantees. Methods that embed language and perceptual data into high-dimensional spaces avoid this manually specified symbolic structure and thus have the potential to be more general when fed enough data but require more data and computing to train. We discuss the benefits and tradeoffs of each approach and finish by providing directions for future work that achieves the best of both worlds.
Lang2LTL: Translating Natural Language Commands to Temporal Robot Task Specification
Feb 22, 2023


Natural language provides a powerful modality to program robots to perform temporal tasks. Linear temporal logic (LTL) provides unambiguous semantics for formal descriptions of temporal tasks. However, existing approaches cannot accurately and robustly translate English sentences to their equivalent LTL formulas in unseen environments. To address this problem, we propose Lang2LTL, a novel modular system that leverages pretrained large language models to first extract referring expressions from a natural language command, then ground the expressions to real-world landmarks and objects, and finally translate the command into an LTL task specification for the robot. It enables any robotic system to interpret natural language navigation commands without additional training, provided that it tracks its position and has a semantic map with landmarks labeled with free-form text. We demonstrate the state-of-the-art ability to generalize to multi-scale navigation domains such as OpenStreetMap (OSM) and CleanUp World (a simulated household environment). Lang2LTL achieves an average accuracy of 88.4% in translating challenging LTL formulas in 22 unseen OSM environments as evaluated on a new corpus of over 10,000 commands, 22 times better than the previous SoTA. Without modification, the best performing Lang2LTL model on the OSM dataset can translate commands in CleanUp World with 82.8% accuracy. As a part of our proposed comprehensive evaluation procedures, we collected a new labeled dataset of English commands representing 2,125 unique LTL formulas, the largest ever dataset of natural language commands to LTL specifications for robotic tasks with the most diverse LTL formulas, 40 times more than previous largest dataset. Finally, we integrated Lang2LTL with a planner to command a quadruped mobile robot to perform multi-step navigational tasks in an analog real-world environment created in the lab.
Skill Transfer for Temporally-Extended Task Specifications
Jun 10, 2022
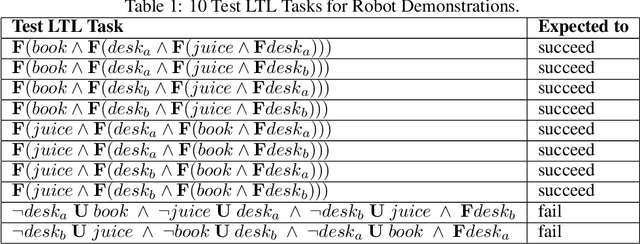
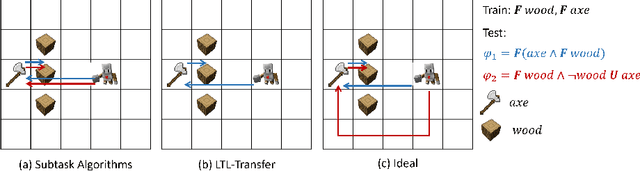
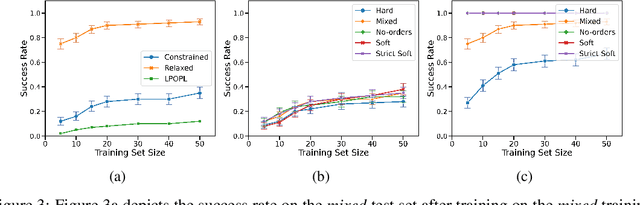
Deploying robots in real-world domains, such as households and flexible manufacturing lines, requires the robots to be taskable on demand. Linear temporal logic (LTL) is a widely-used specification language with a compositional grammar that naturally induces commonalities across tasks. However, the majority of prior research on reinforcement learning with LTL specifications treats every new formula independently. We propose LTL-Transfer, a novel algorithm that enables subpolicy reuse across tasks by segmenting policies for training tasks into portable transition-centric skills capable of satisfying a wide array of unseen LTL specifications while respecting safety-critical constraints. Our experiments in a Minecraft-inspired domain demonstrate the capability of LTL-Transfer to satisfy over 90% of 500 unseen tasks while training on only 50 task specifications and never violating a safety constraint. We also deployed LTL-Transfer on a quadruped mobile manipulator in a household environment to show its ability to transfer to many fetch and delivery tasks in a zero-shot fashion.
Minority Reports Defense: Defending Against Adversarial Patches
Apr 28, 2020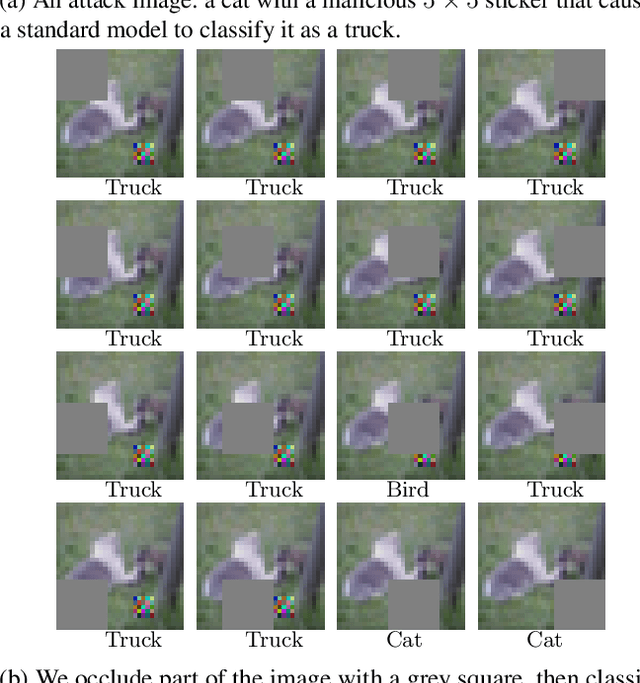
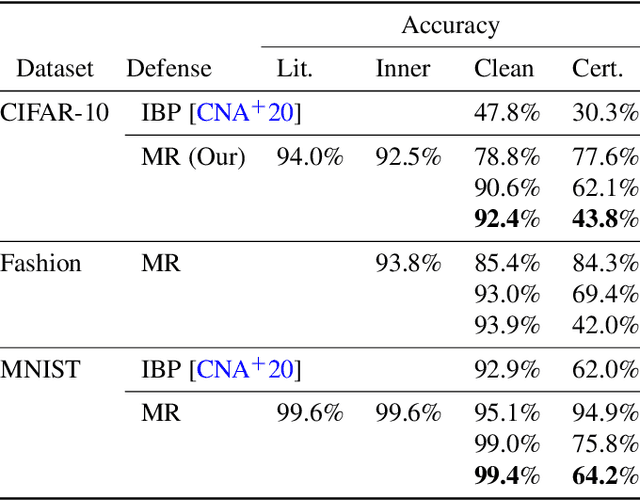
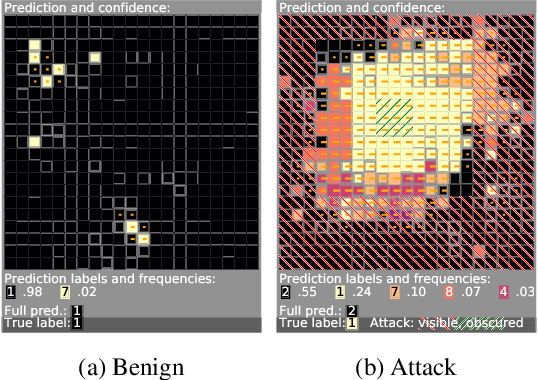
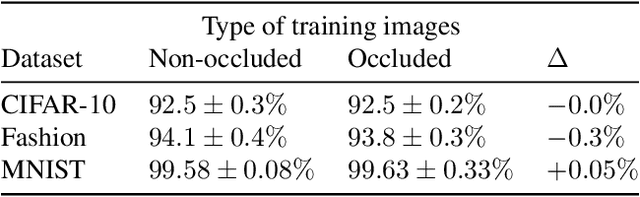
Deep learning image classification is vulnerable to adversarial attack, even if the attacker changes just a small patch of the image. We propose a defense against patch attacks based on partially occluding the image around each candidate patch location, so that a few occlusions each completely hide the patch. We demonstrate on CIFAR-10, Fashion MNIST, and MNIST that our defense provides certified security against patch attacks of a certain size.