 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpertGen: Scalable Sim-to-Real Expert Policy Learning from Imperfect Behavior Priors
Mar 16, 2026Learning generalizable and robust behavior cloning policies requires large volumes of high-quality robotics data. While human demonstrations (e.g., through teleoperation) serve as the standard source for expert behaviors, acquiring such data at scale in the real world is prohibitively expensive. This paper introduces ExpertGen, a framework that automates expert policy learning in simulation to enable scalable sim-to-real transfer. ExpertGen first initializes a behavior prior using a diffusion policy trained on imperfect demonstrations, which may be synthesized by large language models or provided by humans. Reinforcement learning is then used to steer this prior toward high task success by optimizing the diffusion model's initial noise while keep original policy frozen. By keeping the pretrained diffusion policy frozen, ExpertGen regularizes exploration to remain within safe, human-like behavior manifolds, while also enabling effective learning with only sparse rewards. Empirical evaluations on challenging manipulation benchmarks demonstrate that ExpertGen reliably produces high-quality expert policies with no reward engineering. On industrial assembly tasks, ExpertGen achieves a 90.5% overall success rate, while on long-horizon manipulation tasks it attains 85% overall success, outperforming all baseline methods. The resulting policies exhibit dexterous control and remain robust across diverse initial configurations and failure states. To validate sim-to-real transfer, the learned state-based expert policies are further distilled into visuomotor policies via DAgger and successfully deployed on real robotic hardware.
You've Got a Golden Ticket: Improving Generative Robot Policies With A Single Noise Vector
Mar 16, 2026What happens when a pretrained generative robot policy is provided a constant initial noise as input, rather than repeatedly sampling it from a Gaussian? We demonstrate that the performance of a pretrained, frozen diffusion or flow matching policy can be improved with respect to a downstream reward by swapping the sampling of initial noise from the prior distribution (typically isotropic Gaussian) with a well-chosen, constant initial noise input -- a golden ticket. We propose a search method to find golden tickets using Monte-Carlo policy evaluation that keeps the pretrained policy frozen, does not train any new networks, and is applicable to all diffusion/flow matching policies (and therefore many VLAs). Our approach to policy improvement makes no assumptions beyond being able to inject initial noise into the policy and calculate (sparse) task rewards of episode rollouts, making it deployable with no additional infrastructure or models. Our method improves the performance of policies in 38 out of 43 tasks across simulated and real-world robot manipulation benchmarks, with relative improvements in success rate by up to 58% for some simulated tasks, and 60% within 50 search episodes for real-world tasks. We also show unique benefits of golden tickets for multi-task settings: the diversity of behaviors from different tickets naturally defines a Pareto frontier for balancing different objectives (e.g., speed, success rates); in VLAs, we find that a golden ticket optimized for one task can also boost performance in other related tasks. We release a codebase with pretrained policies and golden tickets for simulation benchmarks using VLAs, diffusion policies, and flow matching policies.
Show, Don't Tell: Detecting Novel Objects by Watching Human Videos
Mar 13, 2026How can a robot quickly identify and recognize new objects shown to it during a human demonstration? Existing closed-set object detectors frequently fail at this because the objects are out-of-distribution. While open-set detectors (e.g., VLMs) sometimes succeed, they often require expensive and tedious human-in-the-loop prompt engineering to uniquely recognize novel object instances. In this paper, we present a self-supervised system that eliminates the need for tedious language descriptions and expensive prompt engineering by training a bespoke object detector on an automatically created dataset, supervised by the human demonstration itself. In our approach, "Show, Don't Tell," we show the detector the specific objects of interest during the demonstration, rather than telling the detector about these objects via complex language descriptions. By bypassing language altogether, this paradigm enables us to quickly train bespoke detectors tailored to the relevant objects observed in human task demonstrations. We develop an integrated on-robot system to deploy our "Show, Don't Tell" paradigm of automatic dataset creation and novel object-detection on a real-world robot. Empirical results demonstrate that our pipeline significantly outperforms state-of-the-art detection and recognition methods for manipulated objects, leading to improved task completion for the robot.
Verifiably Following Complex Robot Instructions with Foundation Models
Feb 18, 2024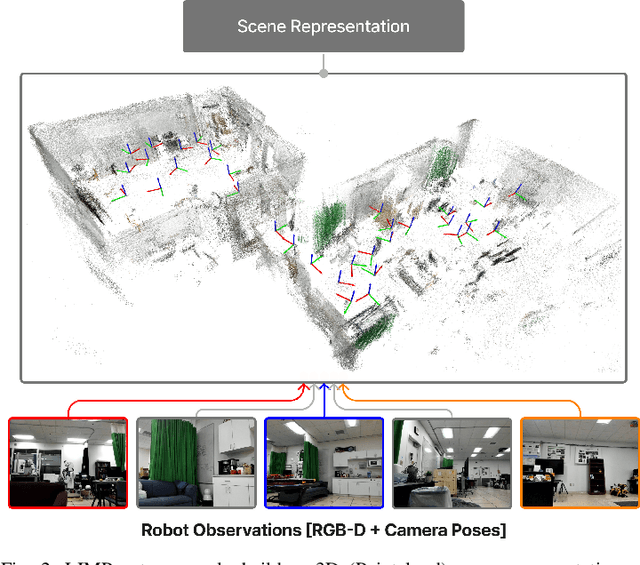
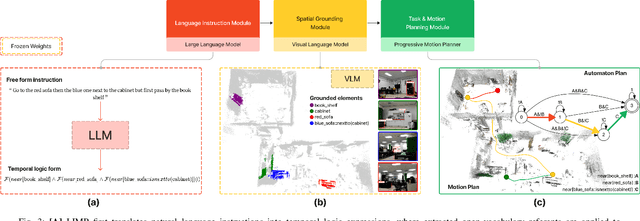


Enabling robots to follow complex natural language instructions is an important yet challenging problem. People want to flexibly express constraints, refer to arbitrary landmarks and verify behavior when instructing robots. Conversely, robots must disambiguate human instructions into specifications and ground instruction referents in the real world. We propose Language Instruction grounding for Motion Planning (LIMP), a system that leverages foundation models and temporal logics to generate instruction-conditioned semantic maps that enable robots to verifiably follow expressive and long-horizon instructions with open vocabulary referents and complex spatiotemporal constraints. In contrast to prior methods for using foundation models in robot task execution, LIMP constructs an explainable instruction representation that reveals the robot's alignment with an instructor's intended motives and affords the synthesis of robot behaviors that are correct-by-construction. We demonstrate LIMP in three real-world environments, across a set of 35 complex spatiotemporal instructions, showing the generality of our approach and the ease of deployment in novel unstructured domains. In our experiments, LIMP can spatially ground open-vocabulary referents and synthesize constraint-satisfying plans in 90% of object-goal navigation and 71% of mobile manipulation instructions. See supplementary videos at https://robotlimp.github.io
Language-Conditioned Observation Models for Visual Object Search
Sep 13, 2023



Object search is a challenging task because when given complex language descriptions (e.g., "find the white cup on the table"), the robot must move its camera through the environment and recognize the described object. Previous works map language descriptions to a set of fixed object detectors with predetermined noise models, but these approaches are challenging to scale because new detectors need to be made for each object. In this work, we bridge the gap in realistic object search by posing the search problem as a partially observable Markov decision process (POMDP) where the object detector and visual sensor noise in the observation model is determined by a single Deep Neural Network conditioned on complex language descriptions. We incorporate the neural network's outputs into our language-conditioned observation model (LCOM) to represent dynamically changing sensor noise. With an LCOM, any language description of an object can be used to generate an appropriate object detector and noise model, and training an LCOM only requires readily available supervised image-caption datasets. We empirically evaluate our method by comparing against a state-of-the-art object search algorithm in simulation, and demonstrate that planning with our observation model yields a significantly higher average task completion rate (from 0.46 to 0.66) and more efficient and quicker object search than with a fixed-noise model. We demonstrate our method on a Boston Dynamics Spot robot, enabling it to handle complex natural language object descriptions and efficiently find objects in a room-scale environment.
A Virtual Reality Teleoperation Interface for Industrial Robot Manipulators
May 18, 2023



We address the problem of teleoperating an industrial robot manipulator via a commercially available Virtual Reality (VR) interface. Previous works on VR teleoperation for robot manipulators focus primarily on collaborative or research robot platforms (whose dynamics and constraints differ from industrial robot arms), or only address tasks where the robot's dynamics are not as important (e.g: pick and place tasks). We investigate the usage of commercially available VR interfaces for effectively teleoeprating industrial robot manipulators in a variety of contact-rich manipulation tasks. We find that applying standard practices for VR control of robot arms is challenging for industrial platforms because torque and velocity control is not exposed, and position control is mediated through a black-box controller. To mitigate these problems, we propose a simplified filtering approach to process command signals to enable operators to effectively teleoperate industrial robot arms with VR interfaces in dexterous manipulation tasks. We hope our findings will help robot practitioners implement and setup effective VR teleoperation interfaces for robot manipulators. The proposed method is demonstrated on a variety of contact-rich manipulation tasks which can also involve very precise movement of the robot during execution (videos can be found at https://www.youtube.com/watch?v=OhkCB9mOaBc)
Planning with Large Language Models via Corrective Re-prompting
Nov 17, 2022
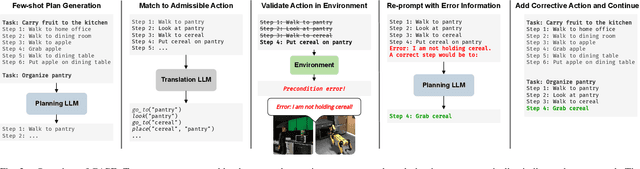
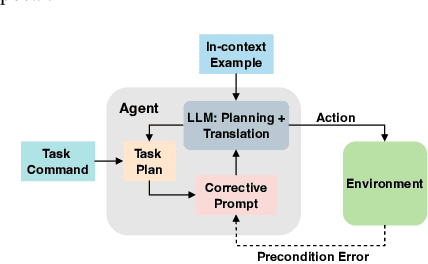
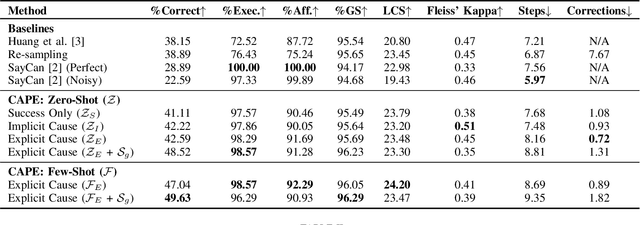
Extracting the common sense knowledge present in Large Language Models (LLMs) offers a path to designing intelligent, embodied agents. Related works have queried LLMs with a wide-range of contextual information, such as goals, sensor observations and scene descriptions, to generate high-level action plans for specific tasks; however these approaches often involve human intervention or additional machinery to enable sensor-motor interactions. In this work, we propose a prompting-based strategy for extracting executable plans from an LLM, which leverages a novel and readily-accessible source of information: precondition errors. Our approach assumes that actions are only afforded execution in certain contexts, i.e., implicit preconditions must be met for an action to execute (e.g., a door must be unlocked to open it), and that the embodied agent has the ability to determine if the action is/is not executable in the current context (e.g., detect if a precondition error is present). When an agent is unable to execute an action, our approach re-prompts the LLM with precondition error information to extract an executable corrective action to achieve the intended goal in the current context. We evaluate our approach in the VirtualHome simulation environment on 88 different tasks and 7 scenes. We evaluate different prompt templates and compare to methods that naively re-sample actions from the LLM. Our approach, using precondition errors, improves executability and semantic correctness of plans, while also reducing the number of re-prompts required when querying actions.
Structural Biases for Improving Transformers on Translation into Morphologically Rich Languages
Aug 11, 2022
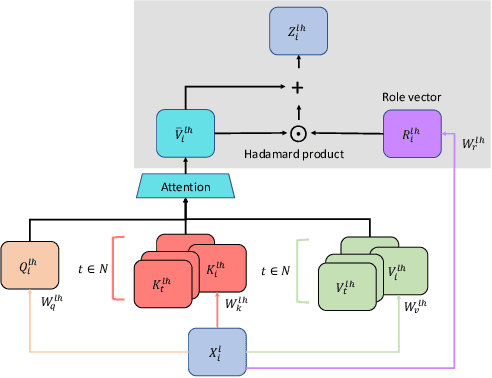

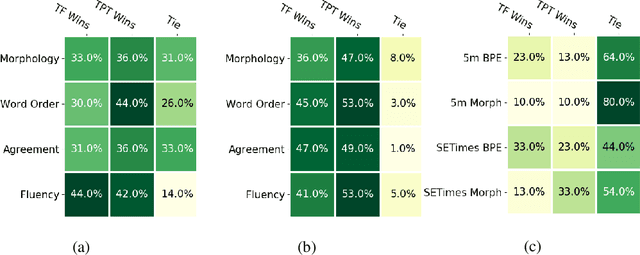
Machine translation has seen rapid progress with the advent of Transformer-based models. These models have no explicit linguistic structure built into them, yet they may still implicitly learn structured relationships by attending to relevant tokens. We hypothesize that this structural learning could be made more robust by explicitly endowing Transformers with a structural bias, and we investigate two methods for building in such a bias. One method, the TP-Transformer, augments the traditional Transformer architecture to include an additional component to represent structure. The second method imbues structure at the data level by segmenting the data with morphological tokenization. We test these methods on translating from English into morphologically rich languages, Turkish and Inuktitut, and consider both automatic metrics and human evaluations. We find that each of these two approaches allows the network to achieve better performance, but this improvement is dependent on the size of the dataset. In sum, structural encoding methods make Transformers more sample-efficient, enabling them to perform better from smaller amounts of data.
* Revised edition to 4th Workshop on Technologies for MT of Low Resource Languages
CHARM: A Hierarchical Deep Learning Model for Classification of Complex Human Activities Using Motion Sensors
Jul 16, 2022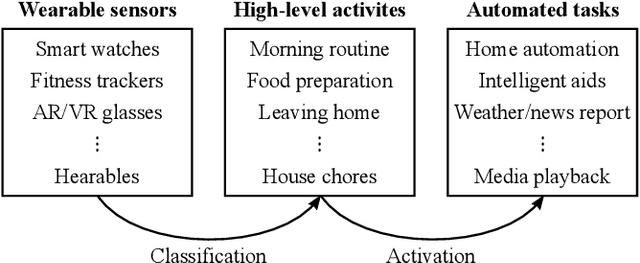

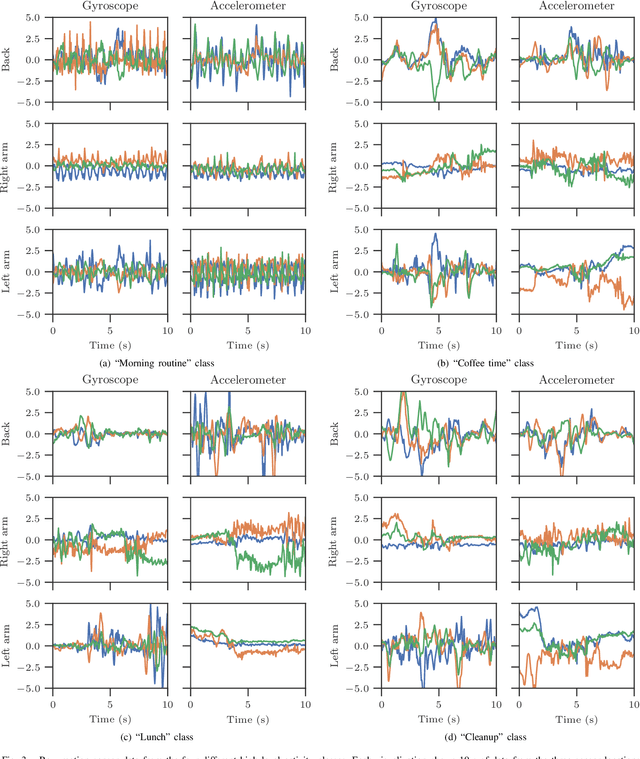
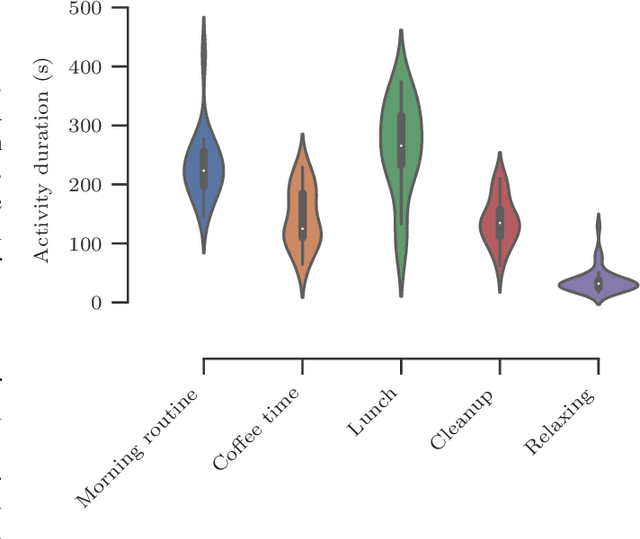
In this paper, we report a hierarchical deep learning model for classification of complex human activities using motion sensors. In contrast to traditional Human Activity Recognition (HAR) models used for event-based activity recognition, such as step counting, fall detection, and gesture identification, this new deep learning model, which we refer to as CHARM (Complex Human Activity Recognition Model), is aimed for recognition of high-level human activities that are composed of multiple different low-level activities in a non-deterministic sequence, such as meal preparation, house chores, and daily routines. CHARM not only quantitatively outperforms state-of-the-art supervised learning approaches for high-level activity recognition in terms of average accuracy and F1 scores, but also automatically learns to recognize low-level activities, such as manipulation gestures and locomotion modes, without any explicit labels for such activities. This opens new avenues for Human-Machine Interaction (HMI) modalities using wearable sensors, where the user can choose to associate an automated task with a high-level activity, such as controlling home automation (e.g., robotic vacuum cleaners, lights, and thermostats) or presenting contextually relevant information at the right time (e.g., reminders, status updates, and weather/news reports). In addition, the ability to learn low-level user activities when trained using only high-level activity labels may pave the way to semi-supervised learning of HAR tasks that are inherently difficult to label.
Skill Transfer for Temporally-Extended Task Specifications
Jun 10, 2022
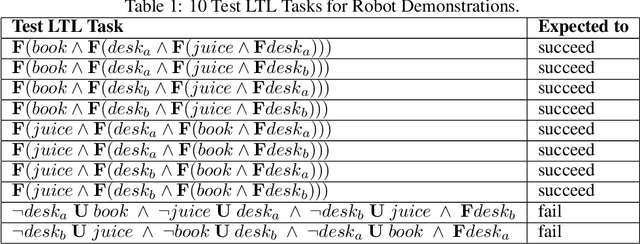
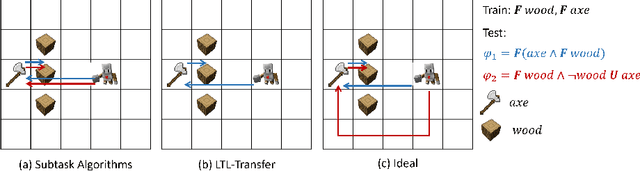
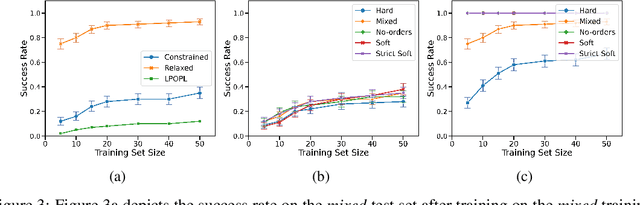
Deploying robots in real-world domains, such as households and flexible manufacturing lines, requires the robots to be taskable on demand. Linear temporal logic (LTL) is a widely-used specification language with a compositional grammar that naturally induces commonalities across tasks. However, the majority of prior research on reinforcement learning with LTL specifications treats every new formula independently. We propose LTL-Transfer, a novel algorithm that enables subpolicy reuse across tasks by segmenting policies for training tasks into portable transition-centric skills capable of satisfying a wide array of unseen LTL specifications while respecting safety-critical constraints. Our experiments in a Minecraft-inspired domain demonstrate the capability of LTL-Transfer to satisfy over 90% of 500 unseen tasks while training on only 50 task specifications and never violating a safety constraint. We also deployed LTL-Transfer on a quadruped mobile manipulator in a household environment to show its ability to transfer to many fetch and delivery tasks in a zero-shot fashion.