 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Flow Imaging in Layered Models With a High Speed of Sound Contrast Using Pulse-Echo Ultrasound and Photoacoustics
Dec 16, 2025In this study, we develop vector flow imaging techniques for multi-layered models with a high wavespeed contrast using photoacoustic and ultrasonic imaging. We use refraction-corrected delay-and-sum image reconstruction (RC-DAS), which enforces Snell's law to accurately calculate time delays within each layer. We compare RC-DAS against conventional delay-and-sum for vector flow imaging in benchtop phantoms made of transparent polymethyl methacrylate (PMMA) in a water bath. We study the flow beneath a PMMA layer using two phantoms, where the PMMA layer has different shapes and thicknesses. We image a slow-moving suspension of carbon microspheres (~4 mm/s) using interleaved photoacoustic and multi-angle plane wave ultrasound acquisitions measured with a 7.6 MHz linear ultrasound array. Photoacoustic waves are generated by a 1064 nm wavelength nanosecond-pulsed laser at 50 Hz, and multi-angle plane wave ultrasound data are acquired at 100 Hz for eleven steering angles between $\pm$10$^\circ$. RC-DAS improves the flow speed accuracy, reducing the mean absolute error by 0.41-0.63 mm/s compared to the expected flow profile. The error in direction estimates improves when we use RC-DAS, with the interdecile range reducing by up to 17$^\circ$. This work emphasises the importance of refraction correction for accurate flow measurements in layered media with photoacoustics and ultrasonic imaging. While both imaging modalities can quantify flow in these multi-layered models, the modality best suited for a specific application will depend on the imaging target and flow dynamics. These techniques show promise for biomedical applications such as intraosseous and transcranial blood flow quantification, and in nondestructive testing to monitor fluid motion.
Structural Biases for Improving Transformers on Translation into Morphologically Rich Languages
Aug 11, 2022

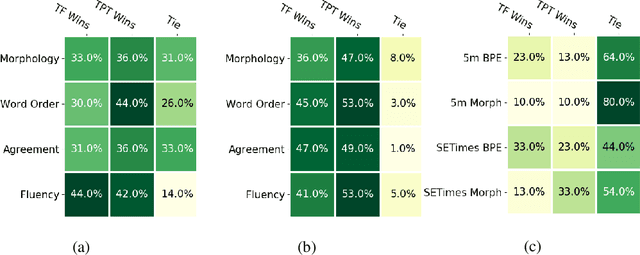
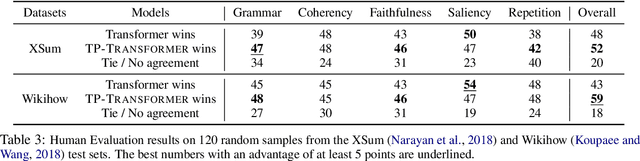
Machine translation has seen rapid progress with the advent of Transformer-based models. These models have no explicit linguistic structure built into them, yet they may still implicitly learn structured relationships by attending to relevant tokens. We hypothesize that this structural learning could be made more robust by explicitly endowing Transformers with a structural bias, and we investigate two methods for building in such a bias. One method, the TP-Transformer, augments the traditional Transformer architecture to include an additional component to represent structure. The second method imbues structure at the data level by segmenting the data with morphological tokenization. We test these methods on translating from English into morphologically rich languages, Turkish and Inuktitut, and consider both automatic metrics and human evaluations. We find that each of these two approaches allows the network to achieve better performance, but this improvement is dependent on the size of the dataset. In sum, structural encoding methods make Transformers more sample-efficient, enabling them to perform better from smaller amounts of data.
* Revised edition to 4th Workshop on Technologies for MT of Low Resource Languages
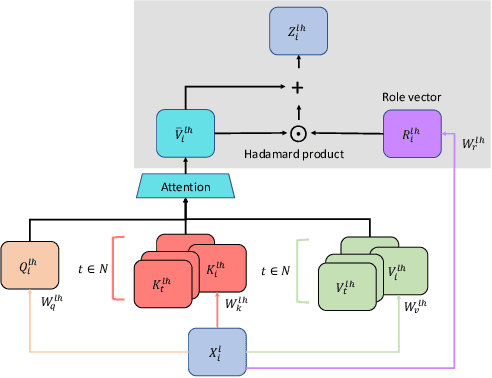
Enriching Transformers with Structured Tensor-Product Representations for Abstractive Summarization
Jun 02, 2021
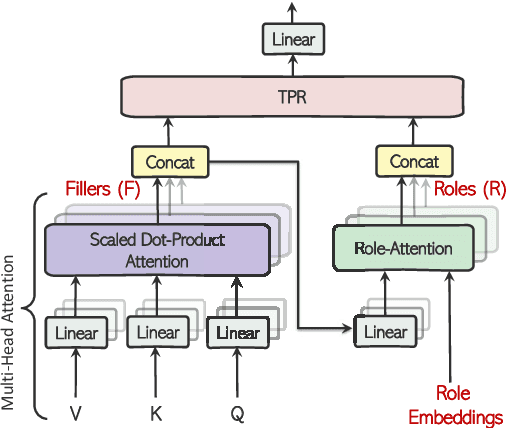
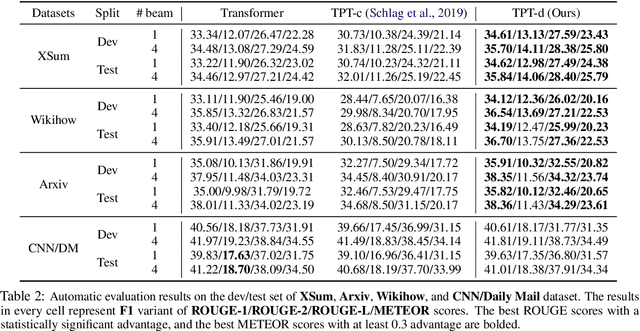
Abstractive summarization, the task of generating a concise summary of input documents, requires: (1) reasoning over the source document to determine the salient pieces of information scattered across the long document, and (2) composing a cohesive text by reconstructing these salient facts into a shorter summary that faithfully reflects the complex relations connecting these facts. In this paper, we adapt TP-TRANSFORMER (Schlag et al., 2019), an architecture that enriches the original Transformer (Vaswani et al., 2017) with the explicitly compositional Tensor Product Representation (TPR), for the task of abstractive summarization. The key feature of our model is a structural bias that we introduce by encoding two separate representations for each token to represent the syntactic structure (with role vectors) and semantic content (with filler vectors) separately. The model then binds the role and filler vectors into the TPR as the layer output. We argue that the structured intermediate representations enable the model to take better control of the contents (salient facts) and structures (the syntax that connects the facts) when generating the summary. Empirically, we show that our TP-TRANSFORMER outperforms the Transformer and the original TP-TRANSFORMER significantly on several abstractive summarization datasets based on both automatic and human evaluations. On several syntactic and semantic probing tasks, we demonstrate the emergent structural information in the role vectors and improved syntactic interpretability in the TPR layer outputs. Code and models are available at https://github.com/jiangycTarheel/TPT-Summ.
A multispeaker dataset of raw and reconstructed speech production real-time MRI video and 3D volumetric images
Feb 16, 2021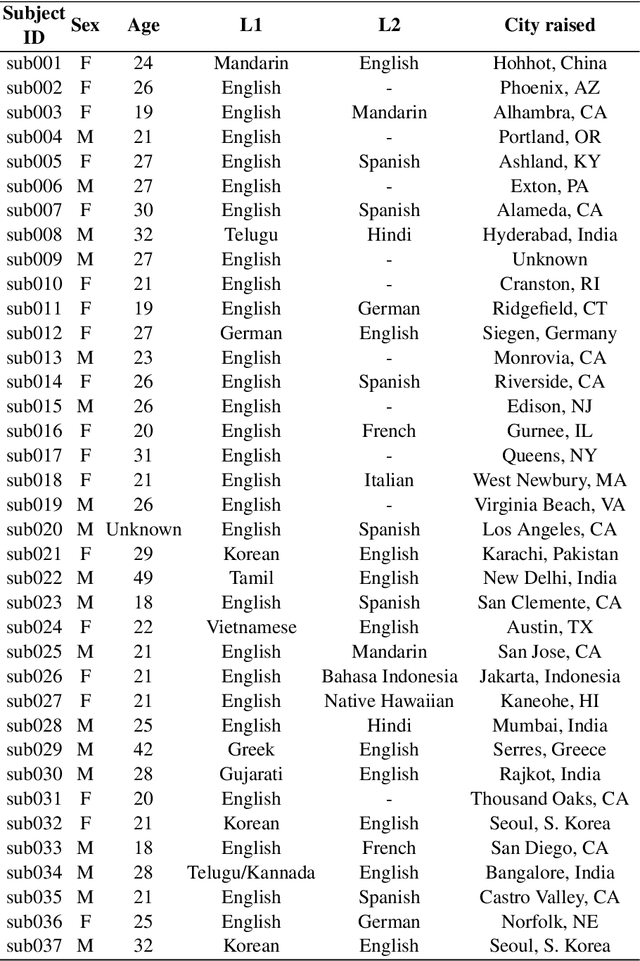
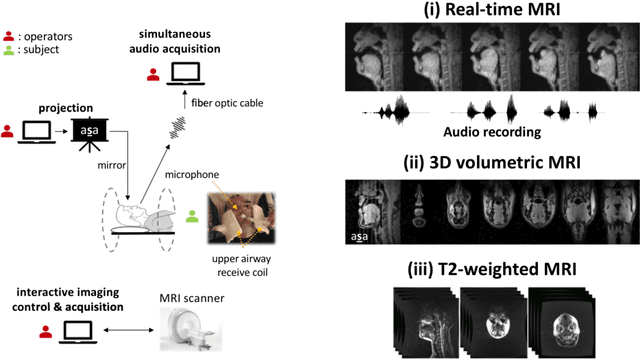
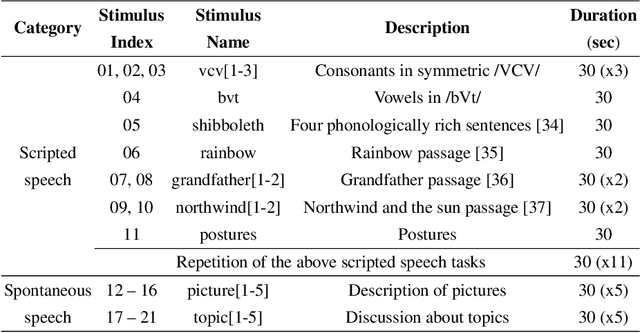
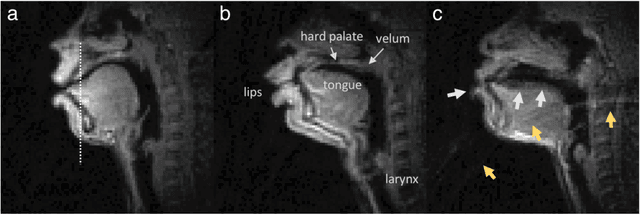
Real-time magnetic resonance imaging (RT-MRI) of human speech production is enabling significant advances in speech science, linguistics, bio-inspired speech technology development, and clinical applications. Easy access to RT-MRI is however limited, and comprehensive datasets with broad access are needed to catalyze research across numerous domains. The imaging of the rapidly moving articulators and dynamic airway shaping during speech demands high spatio-temporal resolution and robust reconstruction methods. Further, while reconstructed images have been published, to-date there is no open dataset providing raw multi-coil RT-MRI data from an optimized speech production experimental setup. Such datasets could enable new and improved methods for dynamic image reconstruction, artifact correction, feature extraction, and direct extraction of linguistically-relevant biomarkers. The present dataset offers a unique corpus of 2D sagittal-view RT-MRI videos along with synchronized audio for 75 subjects performing linguistically motivated speech tasks, alongside the corresponding first-ever public domain raw RT-MRI data. The dataset also includes 3D volumetric vocal tract MRI during sustained speech sounds and high-resolution static anatomical T2-weighted upper airway MRI for each subject.