 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Generalization Across Distributional Shifts with Sparse Tree Operations
Dec 18, 2024Neural networks continue to struggle with compositional generalization, and this issue is exacerbated by a lack of massive pre-training. One successful approach for developing neural systems which exhibit human-like compositional generalization is \textit{hybrid} neurosymbolic techniques. However, these techniques run into the core issues that plague symbolic approaches to AI: scalability and flexibility. The reason for this failure is that at their core, hybrid neurosymbolic models perform symbolic computation and relegate the scalable and flexible neural computation to parameterizing a symbolic system. We investigate a \textit{unified} neurosymbolic system where transformations in the network can be interpreted simultaneously as both symbolic and neural computation. We extend a unified neurosymbolic architecture called the Differentiable Tree Machine in two central ways. First, we significantly increase the model's efficiency through the use of sparse vector representations of symbolic structures. Second, we enable its application beyond the restricted set of tree2tree problems to the more general class of seq2seq problems. The improved model retains its prior generalization capabilities and, since there is a fully neural path through the network, avoids the pitfalls of other neurosymbolic techniques that elevate symbolic computation over neural computation.
Differentiable Tree Operations Promote Compositional Generalization
Jun 01, 2023In the context of structure-to-structure transformation tasks, learning sequences of discrete symbolic operations poses significant challenges due to their non-differentiability. To facilitate the learning of these symbolic sequences, we introduce a differentiable tree interpreter that compiles high-level symbolic tree operations into subsymbolic matrix operations on tensors. We present a novel Differentiable Tree Machine (DTM) architecture that integrates our interpreter with an external memory and an agent that learns to sequentially select tree operations to execute the target transformation in an end-to-end manner. With respect to out-of-distribution compositional generalization on synthetic semantic parsing and language generation tasks, DTM achieves 100% while existing baselines such as Transformer, Tree Transformer, LSTM, and Tree2Tree LSTM achieve less than 30%. DTM remains highly interpretable in addition to its perfect performance.
Structural Biases for Improving Transformers on Translation into Morphologically Rich Languages
Aug 11, 2022

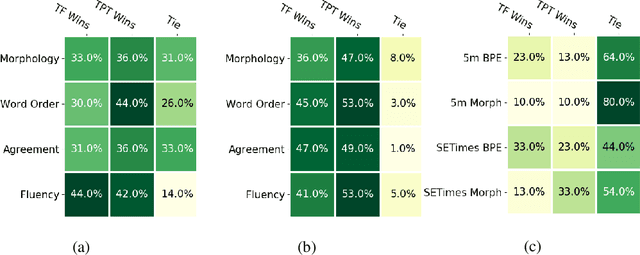
Machine translation has seen rapid progress with the advent of Transformer-based models. These models have no explicit linguistic structure built into them, yet they may still implicitly learn structured relationships by attending to relevant tokens. We hypothesize that this structural learning could be made more robust by explicitly endowing Transformers with a structural bias, and we investigate two methods for building in such a bias. One method, the TP-Transformer, augments the traditional Transformer architecture to include an additional component to represent structure. The second method imbues structure at the data level by segmenting the data with morphological tokenization. We test these methods on translating from English into morphologically rich languages, Turkish and Inuktitut, and consider both automatic metrics and human evaluations. We find that each of these two approaches allows the network to achieve better performance, but this improvement is dependent on the size of the dataset. In sum, structural encoding methods make Transformers more sample-efficient, enabling them to perform better from smaller amounts of data.
* Revised edition to 4th Workshop on Technologies for MT of Low Resource Languages
Enriching Transformers with Structured Tensor-Product Representations for Abstractive Summarization
Jun 02, 2021
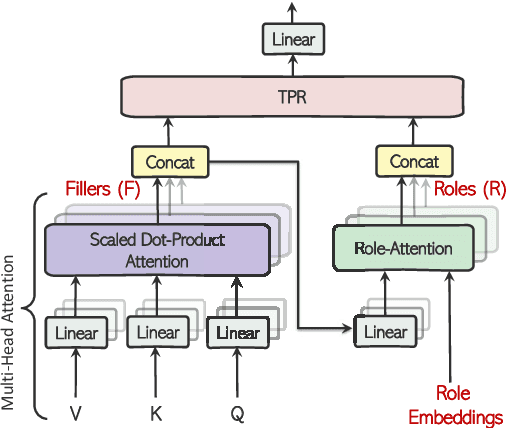
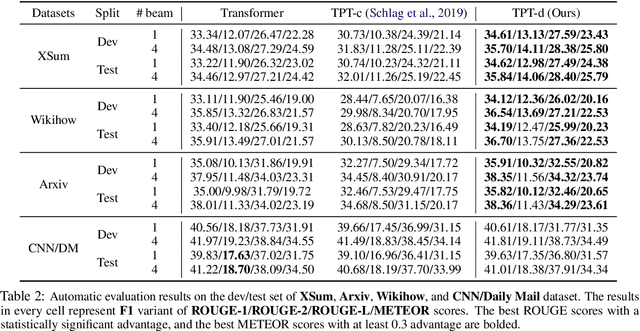
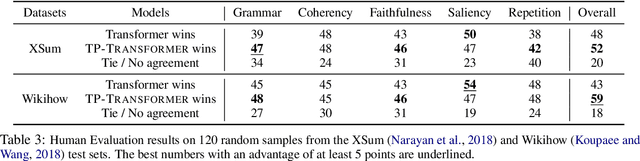
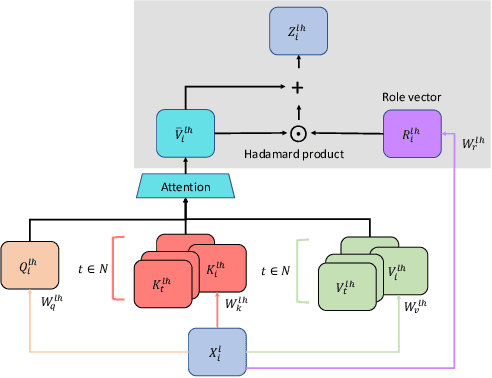
Abstractive summarization, the task of generating a concise summary of input documents, requires: (1) reasoning over the source document to determine the salient pieces of information scattered across the long document, and (2) composing a cohesive text by reconstructing these salient facts into a shorter summary that faithfully reflects the complex relations connecting these facts. In this paper, we adapt TP-TRANSFORMER (Schlag et al., 2019), an architecture that enriches the original Transformer (Vaswani et al., 2017) with the explicitly compositional Tensor Product Representation (TPR), for the task of abstractive summarization. The key feature of our model is a structural bias that we introduce by encoding two separate representations for each token to represent the syntactic structure (with role vectors) and semantic content (with filler vectors) separately. The model then binds the role and filler vectors into the TPR as the layer output. We argue that the structured intermediate representations enable the model to take better control of the contents (salient facts) and structures (the syntax that connects the facts) when generating the summary. Empirically, we show that our TP-TRANSFORMER outperforms the Transformer and the original TP-TRANSFORMER significantly on several abstractive summarization datasets based on both automatic and human evaluations. On several syntactic and semantic probing tasks, we demonstrate the emergent structural information in the role vectors and improved syntactic interpretability in the TPR layer outputs. Code and models are available at https://github.com/jiangycTarheel/TPT-Summ.
Discovering the Compositional Structure of Vector Representations with Role Learning Networks
Nov 17, 2019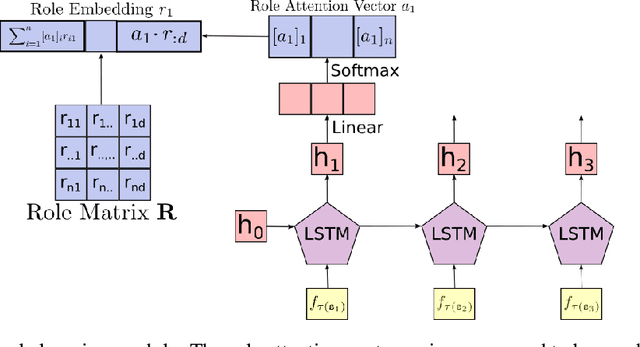



Neural networks are able to perform tasks that rely on compositional structure even though they lack obvious mechanisms for representing this structure. To analyze the internal representations that enable such success, we propose ROLE, a technique that detects whether these representations implicitly encode symbolic structure. ROLE learns to approximate the representations of a target encoder E by learning a symbolic constituent structure and an embedding of that structure into E's representational vector space. The constituents of the approximating symbol structure are defined by structural positions - roles - that can be filled by symbols. We show that when E is constructed to explicitly embed a particular type of structure (string or tree), ROLE successfully extracts the ground-truth roles defining that structure. We then analyze a GRU seq2seq network trained to perform a more complex compositional task (SCAN), where there is no ground truth role scheme available. For this model, ROLE successfully discovers an interpretable symbolic structure that the model implicitly uses to perform the SCAN task, providing a comprehensive account of the representations that drive the behavior of a frequently-used but hard-to-interpret type of model. We verify the causal importance of the discovered symbolic structure by showing that, when we systematically manipulate hidden embeddings based on this symbolic structure, the model's resulting output is changed in the way predicted by our analysis. Finally, we use ROLE to explore whether popular sentence embedding models are capturing compositional structure and find evidence that they are not; we conclude by suggesting how insights from ROLE can be used to impart new inductive biases to improve the compositional abilities of such models.
Learning Hierarchical Visual Representations in Deep Neural Networks Using Hierarchical Linguistic Labels
May 19, 2018
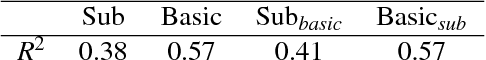


Modern convolutional neural networks (CNNs) are able to achieve human-level object classification accuracy on specific tasks, and currently outperform competing models in explaining complex human visual representations. However, the categorization problem is posed differently for these networks than for humans: the accuracy of these networks is evaluated by their ability to identify single labels assigned to each image. These labels often cut arbitrarily across natural psychological taxonomies (e.g., dogs are separated into breeds, but never jointly categorized as "dogs"), and bias the resulting representations. By contrast, it is common for children to hear both "dog" and "Dalmatian" to describe the same stimulus, helping to group perceptually disparate objects (e.g., breeds) into a common mental class. In this work, we train CNN classifiers with multiple labels for each image that correspond to different levels of abstraction, and use this framework to reproduce classic patterns that appear in human generalization behavior.