 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabyLM Turns 4 and Goes Multilingual: Call for Papers for the 2026 BabyLM Workshop
Feb 24, 2026The goal of the BabyLM is to stimulate new research connections between cognitive modeling and language model pretraining. We invite contributions in this vein to the BabyLM Workshop, which will also include the 4th iteration of the BabyLM Challenge. As in previous years, the challenge features two ``standard'' tracks (Strict and Strict-Small), in which participants must train language models on under 100M or 10M words of data, respectively. This year, we move beyond our previous English-only pretraining datasets with a new Multilingual track, focusing on English, Dutch, and Chinese. For the workshop, we call for papers related to the overall theme of BabyLM, which includes training efficiency, small-scale training datasets, cognitive modeling, model evaluation, and architecture innovation.
Deconstructing sentence disambiguation by joint latent modeling of reading paradigms: LLM surprisal is not enough
Feb 04, 2026Using temporarily ambiguous garden-path sentences ("While the team trained the striker wondered ...") as a test case, we present a latent-process mixture model of human reading behavior across four different reading paradigms (eye tracking, uni- and bidirectional self-paced reading, Maze). The model distinguishes between garden-path probability, garden-path cost, and reanalysis cost, and yields more realistic processing cost estimates by taking into account trials with inattentive reading. We show that the model is able to reproduce empirical patterns with regard to rereading behavior, comprehension question responses, and grammaticality judgments. Cross-validation reveals that the mixture model also has better predictive fit to human reading patterns and end-of-trial task data than a mixture-free model based on GPT-2-derived surprisal values. We discuss implications for future work.
Language Models Struggle to Use Representations Learned In-Context
Feb 04, 2026Though large language models (LLMs) have enabled great success across a wide variety of tasks, they still appear to fall short of one of the loftier goals of artificial intelligence research: creating an artificial system that can adapt its behavior to radically new contexts upon deployment. One important step towards this goal is to create systems that can induce rich representations of data that are seen in-context, and then flexibly deploy these representations to accomplish goals. Recently, Park et al. (2024) demonstrated that current LLMs are indeed capable of inducing such representation from context (i.e., in-context representation learning). The present study investigates whether LLMs can use these representations to complete simple downstream tasks. We first assess whether open-weights LLMs can use in-context representations for next-token prediction, and then probe models using a novel task, adaptive world modeling. In both tasks, we find evidence that open-weights LLMs struggle to deploy representations of novel semantics that are defined in-context, even if they encode these semantics in their latent representations. Furthermore, we assess closed-source, state-of-the-art reasoning models on the adaptive world modeling task, demonstrating that even the most performant LLMs cannot reliably leverage novel patterns presented in-context. Overall, this work seeks to inspire novel methods for encouraging models to not only encode information presented in-context, but to do so in a manner that supports flexible deployment of this information.
RELIC: Evaluating Compositional Instruction Following via Language Recognition
Jun 05, 2025Large language models (LLMs) are increasingly expected to perform tasks based only on a specification of the task provided in context, without examples of inputs and outputs; this ability is referred to as instruction following. We introduce the Recognition of Languages In-Context (RELIC) framework to evaluate instruction following using language recognition: the task of determining if a string is generated by formal grammar. Unlike many standard evaluations of LLMs' ability to use their context, this task requires composing together a large number of instructions (grammar productions) retrieved from the context. Because the languages are synthetic, the task can be increased in complexity as LLMs' skills improve, and new instances can be automatically generated, mitigating data contamination. We evaluate state-of-the-art LLMs on RELIC and find that their accuracy can be reliably predicted from the complexity of the grammar and the individual example strings, and that even the most advanced LLMs currently available show near-chance performance on more complex grammars and samples, in line with theoretical expectations. We also use RELIC to diagnose how LLMs attempt to solve increasingly difficult reasoning tasks, finding that as the complexity of the language recognition task increases, models switch to relying on shallow heuristics instead of following complex instructions.
Multilingual Prompting for Improving LLM Generation Diversity
May 21, 2025



Large Language Models (LLMs) are known to lack cultural representation and overall diversity in their generations, from expressing opinions to answering factual questions. To mitigate this problem, we propose multilingual prompting: a prompting method which generates several variations of a base prompt with added cultural and linguistic cues from several cultures, generates responses, and then combines the results. Building on evidence that LLMs have language-specific knowledge, multilingual prompting seeks to increase diversity by activating a broader range of cultural knowledge embedded in model training data. Through experiments across multiple models (GPT-4o, GPT-4o-mini, LLaMA 70B, and LLaMA 8B), we show that multilingual prompting consistently outperforms existing diversity-enhancing techniques such as high-temperature sampling, step-by-step recall, and personas prompting. Further analyses show that the benefits of multilingual prompting vary with language resource level and model size, and that aligning the prompting language with the cultural cues reduces hallucination about culturally-specific information.
Findings of the BabyLM Challenge: Sample-Efficient Pretraining on Developmentally Plausible Corpora
Apr 10, 2025



Children can acquire language from less than 100 million words of input. Large language models are far less data-efficient: they typically require 3 or 4 orders of magnitude more data and still do not perform as well as humans on many evaluations. These intensive resource demands limit the ability of researchers to train new models and use existing models as developmentally plausible cognitive models. The BabyLM Challenge is a communal effort in which participants compete to optimize language model training on a fixed data budget. Submissions are compared on various evaluation tasks targeting grammatical ability, downstream task performance, and generalization. Participants can submit to up to three tracks with progressively looser data restrictions. From over 30 submissions, we extract concrete recommendations on how best to train data-efficient language models, and on where future efforts should (and perhaps should not) focus. The winning submissions using the LTG-BERT architecture (Samuel et al., 2023) outperformed models trained on trillions of words. Other submissions achieved strong results through training on shorter input sequences or training a student model on a pretrained teacher. Curriculum learning attempts, which accounted for a large number of submissions, were largely unsuccessful, though some showed modest improvements.
* Published in Proceedings of BabyLM. Please cite the published version on ACL anthology: http://aclanthology.org/2023.conll-babylm.1/
Between Circuits and Chomsky: Pre-pretraining on Formal Languages Imparts Linguistic Biases
Feb 26, 2025



Pretraining language models on formal languages can improve their acquisition of natural language, but it is unclear which features of the formal language impart an inductive bias that leads to effective transfer. Drawing on insights from linguistics and complexity theory, we hypothesize that effective transfer occurs when the formal language both captures dependency structures in natural language and remains within the computational limitations of the model architecture. Focusing on transformers, we find that formal languages with both these properties enable language models to achieve lower loss on natural language and better linguistic generalization compared to other languages. In fact, pre-pretraining, or training on formal-then-natural language, reduces loss more efficiently than the same amount of natural language. For a 1B-parameter language model trained on roughly 1.6B tokens of natural language, pre-pretraining achieves the same loss and better linguistic generalization with a 33% smaller token budget. We also give mechanistic evidence of cross-task transfer from formal to natural language: attention heads acquired during formal language pretraining remain crucial for the model's performance on syntactic evaluations.
Rapid Word Learning Through Meta In-Context Learning
Feb 20, 2025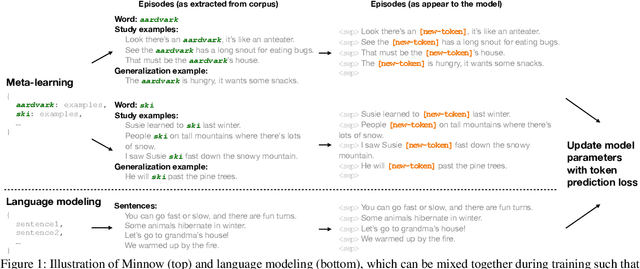
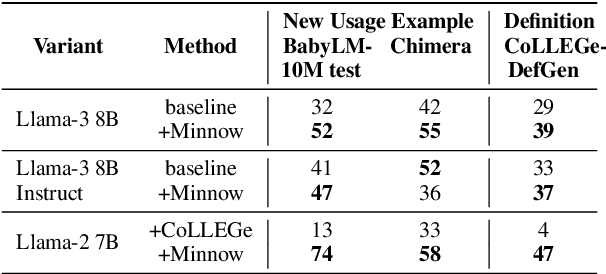

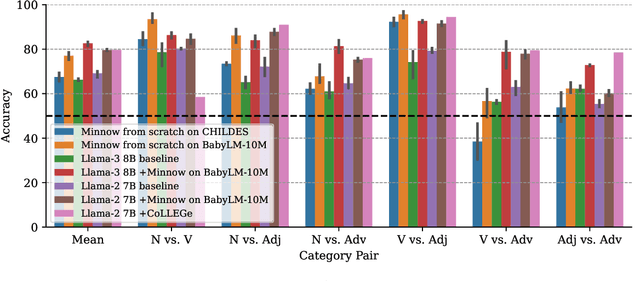
Humans can quickly learn a new word from a few illustrative examples, and then systematically and flexibly use it in novel contexts. Yet the abilities of current language models for few-shot word learning, and methods for improving these abilities, are underexplored. In this study, we introduce a novel method, Meta-training for IN-context learNing Of Words (Minnow). This method trains language models to generate new examples of a word's usage given a few in-context examples, using a special placeholder token to represent the new word. This training is repeated on many new words to develop a general word-learning ability. We find that training models from scratch with Minnow on human-scale child-directed language enables strong few-shot word learning, comparable to a large language model (LLM) pre-trained on orders of magnitude more data. Furthermore, through discriminative and generative evaluations, we demonstrate that finetuning pre-trained LLMs with Minnow improves their ability to discriminate between new words, identify syntactic categories of new words, and generate reasonable new usages and definitions for new words, based on one or a few in-context examples. These findings highlight the data efficiency of Minnow and its potential to improve language model performance in word learning tasks.
Findings of the Second BabyLM Challenge: Sample-Efficient Pretraining on Developmentally Plausible Corpora
Dec 06, 2024The BabyLM Challenge is a community effort to close the data-efficiency gap between human and computational language learners. Participants compete to optimize language model training on a fixed language data budget of 100 million words or less. This year, we released improved text corpora, as well as a vision-and-language corpus to facilitate research into cognitively plausible vision language models. Submissions were compared on evaluation tasks targeting grammatical ability, (visual) question answering, pragmatic abilities, and grounding, among other abilities. Participants could submit to a 10M-word text-only track, a 100M-word text-only track, and/or a 100M-word and image multimodal track. From 31 submissions employing diverse methods, a hybrid causal-masked language model architecture outperformed other approaches. No submissions outperformed the baselines in the multimodal track. In follow-up analyses, we found a strong relationship between training FLOPs and average performance across tasks, and that the best-performing submissions proposed changes to the training data, training objective, and model architecture. This year's BabyLM Challenge shows that there is still significant room for innovation in this setting, in particular for image-text modeling, but community-driven research can yield actionable insights about effective strategies for small-scale language modeling.
What Goes Into a LM Acceptability Judgment? Rethinking the Impact of Frequency and Length
Nov 04, 2024


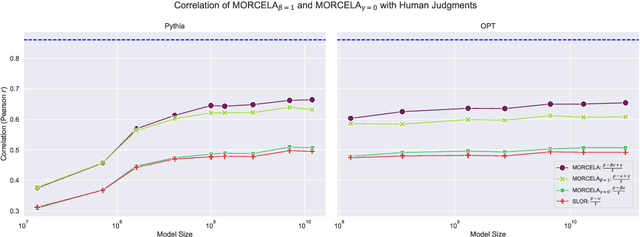
When comparing the linguistic capabilities of language models (LMs) with humans using LM probabilities, factors such as the length of the sequence and the unigram frequency of lexical items have a significant effect on LM probabilities in ways that humans are largely robust to. Prior works in comparing LM and human acceptability judgments treat these effects uniformly across models, making a strong assumption that models require the same degree of adjustment to control for length and unigram frequency effects. We propose MORCELA, a new linking theory between LM scores and acceptability judgments where the optimal level of adjustment for these effects is estimated from data via learned parameters for length and unigram frequency. We first show that MORCELA outperforms a commonly used linking theory for acceptability--SLOR (Pauls and Klein, 2012; Lau et al. 2017)--across two families of transformer LMs (Pythia and OPT). Furthermore, we demonstrate that the assumed degrees of adjustment in SLOR for length and unigram frequency overcorrect for these confounds, and that larger models require a lower relative degree of adjustment for unigram frequency, though a significant amount of adjustment is still necessary for all models. Finally, our subsequent analysis shows that larger LMs' lower susceptibility to frequency effects can be explained by an ability to better predict rarer words in context.