 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the BabyLM Challenge: Sample-Efficient Pretraining on Developmentally Plausible Corpora
Apr 10, 2025



Children can acquire language from less than 100 million words of input. Large language models are far less data-efficient: they typically require 3 or 4 orders of magnitude more data and still do not perform as well as humans on many evaluations. These intensive resource demands limit the ability of researchers to train new models and use existing models as developmentally plausible cognitive models. The BabyLM Challenge is a communal effort in which participants compete to optimize language model training on a fixed data budget. Submissions are compared on various evaluation tasks targeting grammatical ability, downstream task performance, and generalization. Participants can submit to up to three tracks with progressively looser data restrictions. From over 30 submissions, we extract concrete recommendations on how best to train data-efficient language models, and on where future efforts should (and perhaps should not) focus. The winning submissions using the LTG-BERT architecture (Samuel et al., 2023) outperformed models trained on trillions of words. Other submissions achieved strong results through training on shorter input sequences or training a student model on a pretrained teacher. Curriculum learning attempts, which accounted for a large number of submissions, were largely unsuccessful, though some showed modest improvements.
* Published in Proceedings of BabyLM. Please cite the published version on ACL anthology: http://aclanthology.org/2023.conll-babylm.1/
Findings of the Second BabyLM Challenge: Sample-Efficient Pretraining on Developmentally Plausible Corpora
Dec 06, 2024The BabyLM Challenge is a community effort to close the data-efficiency gap between human and computational language learners. Participants compete to optimize language model training on a fixed language data budget of 100 million words or less. This year, we released improved text corpora, as well as a vision-and-language corpus to facilitate research into cognitively plausible vision language models. Submissions were compared on evaluation tasks targeting grammatical ability, (visual) question answering, pragmatic abilities, and grounding, among other abilities. Participants could submit to a 10M-word text-only track, a 100M-word text-only track, and/or a 100M-word and image multimodal track. From 31 submissions employing diverse methods, a hybrid causal-masked language model architecture outperformed other approaches. No submissions outperformed the baselines in the multimodal track. In follow-up analyses, we found a strong relationship between training FLOPs and average performance across tasks, and that the best-performing submissions proposed changes to the training data, training objective, and model architecture. This year's BabyLM Challenge shows that there is still significant room for innovation in this setting, in particular for image-text modeling, but community-driven research can yield actionable insights about effective strategies for small-scale language modeling.
The BabyView dataset: High-resolution egocentric videos of infants' and young children's everyday experiences
Jun 14, 2024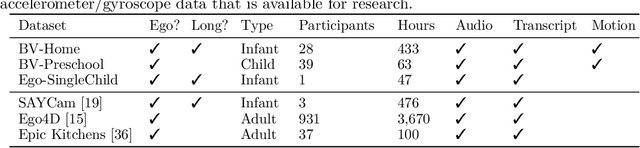
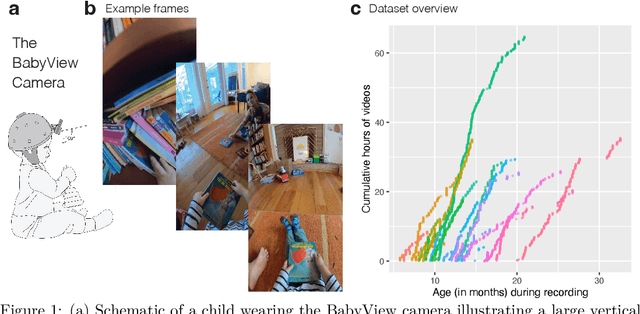
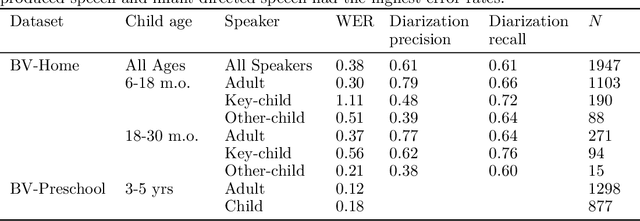
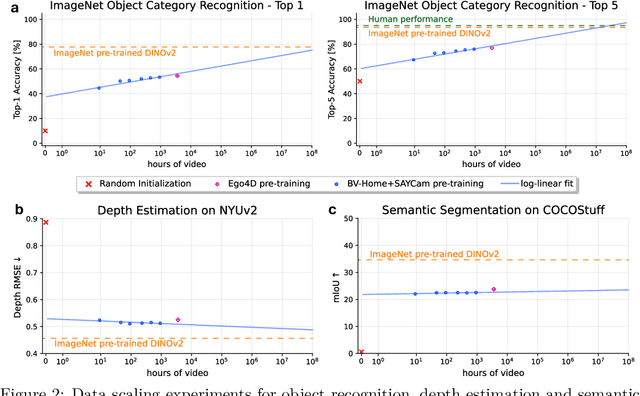
Human children far exceed modern machine learning algorithms in their sample efficiency, achieving high performance in key domains with much less data than current models. This ''data gap'' is a key challenge both for building intelligent artificial systems and for understanding human development. Egocentric video capturing children's experience -- their ''training data'' -- is a key ingredient for comparison of humans and models and for the development of algorithmic innovations to bridge this gap. Yet there are few such datasets available, and extant data are low-resolution, have limited metadata, and importantly, represent only a small set of children's experiences. Here, we provide the first release of the largest developmental egocentric video dataset to date -- the BabyView dataset -- recorded using a high-resolution camera with a large vertical field-of-view and gyroscope/accelerometer data. This 493 hour dataset includes egocentric videos from children spanning 6 months - 5 years of age in both longitudinal, at-home contexts and in a preschool environment. We provide gold-standard annotations for the evaluation of speech transcription, speaker diarization, and human pose estimation, and evaluate models in each of these domains. We train self-supervised language and vision models and evaluate their transfer to out-of-distribution tasks including syntactic structure learning, object recognition, depth estimation, and image segmentation. Although performance in each scales with dataset size, overall performance is relatively lower than when models are trained on curated datasets, especially in the visual domain. Our dataset stands as an open challenge for robust, humanlike AI systems: how can such systems achieve human-levels of success on the same scale and distribution of training data as humans?
[Call for Papers] The 2nd BabyLM Challenge: Sample-efficient pretraining on a developmentally plausible corpus
Apr 09, 2024![Figure 1 for [Call for Papers] The 2nd BabyLM Challenge: Sample-efficient pretraining on a developmentally plausible corpus](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F6c552d900eadfcedce23c16cbd70fdf6d3024125%2F3-Table1-1.png&w=640&q=75)
After last year's successful BabyLM Challenge, the competition will be hosted again in 2024/2025. The overarching goals of the challenge remain the same; however, some of the competition rules will be different. The big changes for this year's competition are as follows: First, we replace the loose track with a paper track, which allows (for example) non-model-based submissions, novel cognitively-inspired benchmarks, or analysis techniques. Second, we are relaxing the rules around pretraining data, and will now allow participants to construct their own datasets provided they stay within the 100M-word or 10M-word budget. Third, we introduce a multimodal vision-and-language track, and will release a corpus of 50% text-only and 50% image-text multimodal data as a starting point for LM model training. The purpose of this CfP is to provide rules for this year's challenge, explain these rule changes and their rationale in greater detail, give a timeline of this year's competition, and provide answers to frequently asked questions from last year's challenge.
Lexicon-Level Contrastive Visual-Grounding Improves Language Modeling
Mar 21, 2024Today's most accurate language models are trained on orders of magnitude more language data than human language learners receive - but with no supervision from other sensory modalities that play a crucial role in human learning. Can we make LMs' representations and predictions more accurate (and more human-like) with more ecologically plausible supervision? This paper describes LexiContrastive Grounding (LCG), a grounded language learning procedure that leverages visual supervision to improve textual representations. LexiContrastive Grounding combines a next token prediction strategy with a contrastive visual grounding objective, focusing on early-layer representations that encode lexical information. Across multiple word-learning and sentence-understanding benchmarks, LexiContrastive Grounding not only outperforms standard language-only models in learning efficiency, but also improves upon vision-and-language learning procedures including CLIP, GIT, Flamingo, and Vokenization. Moreover, LexiContrastive Grounding improves perplexity by around 5% on multiple language modeling tasks. This work underscores the potential of incorporating visual grounding into language models, aligning more closely with the multimodal nature of human language acquisition.
Visual Grounding Helps Learn Word Meanings in Low-Data Regimes
Oct 20, 2023Modern neural language models (LMs) are powerful tools for modeling human sentence production and comprehension, and their internal representations are remarkably well-aligned with representations of language in the human brain. But to achieve these results, LMs must be trained in distinctly un-human-like ways -- requiring orders of magnitude more language data than children receive during development, and without any of the accompanying grounding in perception, action, or social behavior. Do models trained more naturalistically -- with grounded supervision -- exhibit more human-like language learning? We investigate this question in the context of word learning, a key sub-task in language acquisition. We train a diverse set of LM architectures, with and without auxiliary supervision from image captioning tasks, on datasets of varying scales. We then evaluate these models on a broad set of benchmarks characterizing models' learning of syntactic categories, lexical relations, semantic features, semantic similarity, and alignment with human neural representations. We find that visual supervision can indeed improve the efficiency of word learning. However, these improvements are limited: they are present almost exclusively in the low-data regime, and sometimes canceled out by the inclusion of rich distributional signals from text. The information conveyed by text and images is not redundant -- we find that models mainly driven by visual information yield qualitatively different from those mainly driven by word co-occurrences. However, our results suggest that current multi-modal modeling approaches fail to effectively leverage visual information to build more human-like word representations from human-sized datasets.
Call for Papers -- The BabyLM Challenge: Sample-efficient pretraining on a developmentally plausible corpus
Jan 27, 2023

We present the call for papers for the BabyLM Challenge: Sample-efficient pretraining on a developmentally plausible corpus. This shared task is intended for participants with an interest in small scale language modeling, human language acquisition, low-resource NLP, and cognitive modeling. In partnership with CoNLL and CMCL, we provide a platform for approaches to pretraining with a limited-size corpus sourced from data inspired by the input to children. The task has three tracks, two of which restrict the training data to pre-released datasets of 10M and 100M words and are dedicated to explorations of approaches such as architectural variations, self-supervised objectives, or curriculum learning. The final track only restricts the amount of text used, allowing innovation in the choice of the data, its domain, and even its modality (i.e., data from sources other than text is welcome). We will release a shared evaluation pipeline which scores models on a variety of benchmarks and tasks, including targeted syntactic evaluations and natural language understanding.
Conditional Negative Sampling for Contrastive Learning of Visual Representations
Oct 05, 2020


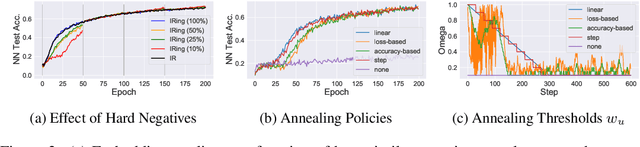
Recent methods for learning unsupervised visual representations, dubbed contrastive learning, optimize the noise-contrastive estimation (NCE) bound on mutual information between two views of an image. NCE uses randomly sampled negative examples to normalize the objective. In this paper, we show that choosing difficult negatives, or those more similar to the current instance, can yield stronger representations. To do this, we introduce a family of mutual information estimators that sample negatives conditionally -- in a "ring" around each positive. We prove that these estimators lower-bound mutual information, with higher bias but lower variance than NCE. Experimentally, we find our approach, applied on top of existing models (IR, CMC, and MoCo) improves accuracy by 2-5% points in each case, measured by linear evaluation on four standard image datasets. Moreover, we find continued benefits when transferring features to a variety of new image distributions from the Meta-Dataset collection and to a variety of downstream tasks such as object detection, instance segmentation, and keypoint detection.
On Mutual Information in Contrastive Learning for Visual Representations
Jun 05, 2020
In recent years, several unsupervised, "contrastive" learning algorithms in vision have been shown to learn representations that perform remarkably well on transfer tasks. We show that this family of algorithms maximizes a lower bound on the mutual information between two or more "views" of an image where typical views come from a composition of image augmentations. Our bound generalizes the InfoNCE objective to support negative sampling from a restricted region of "difficult" contrasts. We find that the choice of negative samples and views are critical to the success of these algorithms. Reformulating previous learning objectives in terms of mutual information also simplifies and stabilizes them. In practice, our new objectives yield representations that outperform those learned with previous approaches for transfer to classification, bounding box detection, instance segmentation, and keypoint detection. % experiments show that choosing more difficult negative samples results in a stronger representation, outperforming those learned with IR, LA, and CMC in classification, bounding box detection, instance segmentation, and keypoint detection. The mutual information framework provides a unifying comparison of approaches to contrastive learning and uncovers the choices that impact representation learning.
Unsupervised Learning from Video with Deep Neural Embeddings
May 28, 2019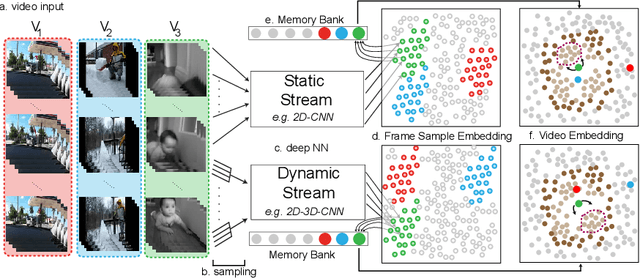



Because of the rich dynamical structure of videos and their ubiquity in everyday life, it is a natural idea that video data could serve as a powerful unsupervised learning signal for training visual representations in deep neural networks. However, instantiating this idea, especially at large scale, has remained a significant artificial intelligence challenge. Here we present the Video Instance Embedding (VIE) framework, which extends powerful recent unsupervised loss functions for learning deep nonlinear embeddings to multi-stream temporal processing architectures on large-scale video datasets. We show that VIE-trained networks substantially advance the state of the art in unsupervised learning from video datastreams, both for action recognition in the Kinetics dataset, and object recognition in the ImageNet dataset. We show that a hybrid model with both static and dynamic processing pathways is optimal for both transfer tasks, and provide analyses indicating how the pathways differ. Taken in context, our results suggest that deep neural embeddings are a promising approach to unsupervised visual learning across a wide variety of domains.