 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanatory models in neuroscience: Part 2 -- constraint-based intelligibility
Apr 14, 2021

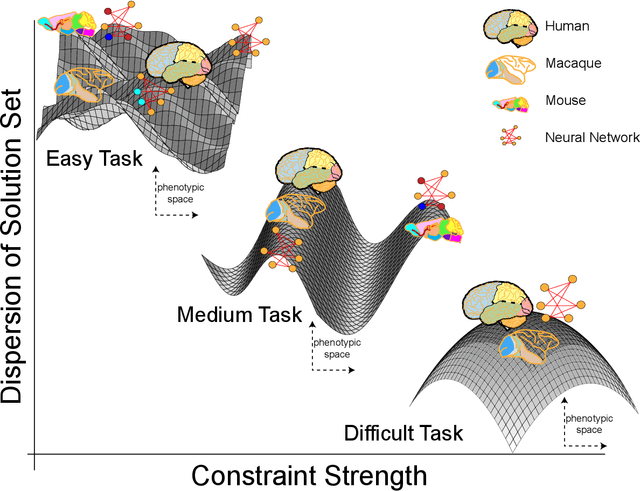
Computational modeling plays an increasingly important role in neuroscience, highlighting the philosophical question of how computational models explain. In the context of neural network models for neuroscience, concerns have been raised about model intelligibility, and how they relate (if at all) to what is found in the brain. We claim that what makes a system intelligible is an understanding of the dependencies between its behavior and the factors that are causally responsible for that behavior. In biological systems, many of these dependencies are naturally "top-down": ethological imperatives interact with evolutionary and developmental constraints under natural selection. We describe how the optimization techniques used to construct NN models capture some key aspects of these dependencies, and thus help explain why brain systems are as they are -- because when a challenging ecologically-relevant goal is shared by a NN and the brain, it places tight constraints on the possible mechanisms exhibited in both kinds of systems. By combining two familiar modes of explanation -- one based on bottom-up mechanism (whose relation to neural network models we address in a companion paper) and the other on top-down constraints, these models illuminate brain function.
Explanatory models in neuroscience: Part 1 -- taking mechanistic abstraction seriously
Apr 10, 2021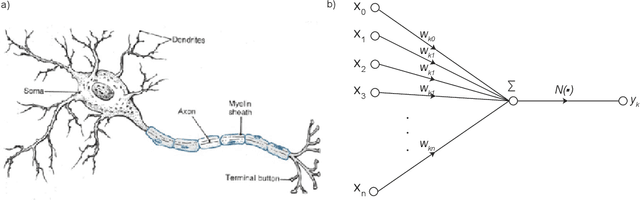

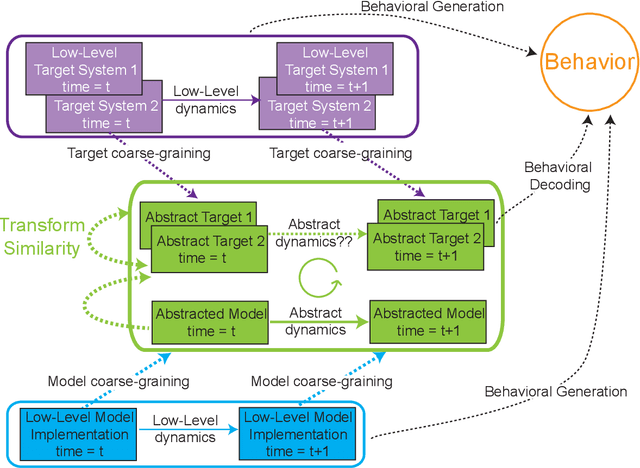

Despite the recent success of neural network models in mimicking animal performance on visual perceptual tasks, critics worry that these models fail to illuminate brain function. We take it that a central approach to explanation in systems neuroscience is that of mechanistic modeling, where understanding the system is taken to require fleshing out the parts, organization, and activities of a system, and how those give rise to behaviors of interest. However, it remains somewhat controversial what it means for a model to describe a mechanism, and whether neural network models qualify as explanatory. We argue that certain kinds of neural network models are actually good examples of mechanistic models, when the right notion of mechanistic mapping is deployed. Building on existing work on model-to-mechanism mapping (3M), we describe criteria delineating such a notion, which we call 3M++. These criteria require us, first, to identify a level of description that is both abstract but detailed enough to be "runnable", and then, to construct model-to-brain mappings using the same principles as those employed for brain-to-brain mapping across individuals. Perhaps surprisingly, the abstractions required are those already in use in experimental neuroscience, and are of the kind deployed in the construction of more familiar computational models, just as the principles of inter-brain mappings are very much in the spirit of those already employed in the collection and analysis of data across animals. In a companion paper, we address the relationship between optimization and intelligibility, in the context of functional evolutionary explanations. Taken together, mechanistic interpretations of computational models and the dependencies between form and function illuminated by optimization processes can help us to understand why brain systems are built they way they are.
Conditional Negative Sampling for Contrastive Learning of Visual Representations
Oct 05, 2020


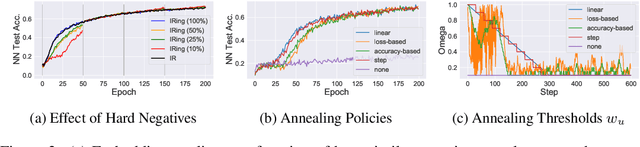
Recent methods for learning unsupervised visual representations, dubbed contrastive learning, optimize the noise-contrastive estimation (NCE) bound on mutual information between two views of an image. NCE uses randomly sampled negative examples to normalize the objective. In this paper, we show that choosing difficult negatives, or those more similar to the current instance, can yield stronger representations. To do this, we introduce a family of mutual information estimators that sample negatives conditionally -- in a "ring" around each positive. We prove that these estimators lower-bound mutual information, with higher bias but lower variance than NCE. Experimentally, we find our approach, applied on top of existing models (IR, CMC, and MoCo) improves accuracy by 2-5% points in each case, measured by linear evaluation on four standard image datasets. Moreover, we find continued benefits when transferring features to a variety of new image distributions from the Meta-Dataset collection and to a variety of downstream tasks such as object detection, instance segmentation, and keypoint detection.
Active World Model Learning with Progress Curiosity
Jul 15, 2020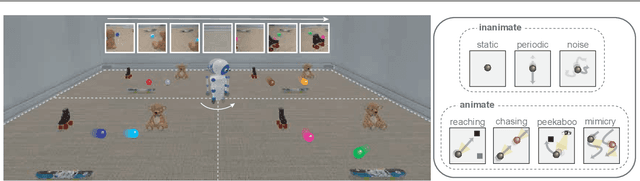
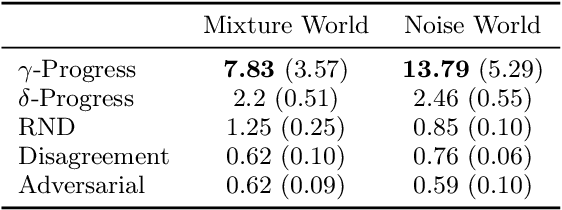
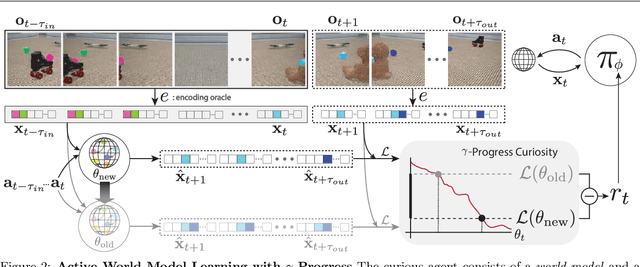
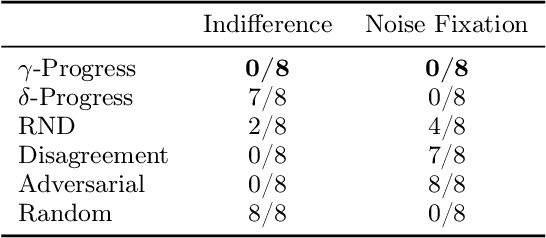
World models are self-supervised predictive models of how the world evolves. Humans learn world models by curiously exploring their environment, in the process acquiring compact abstractions of high bandwidth sensory inputs, the ability to plan across long temporal horizons, and an understanding of the behavioral patterns of other agents. In this work, we study how to design such a curiosity-driven Active World Model Learning (AWML) system. To do so, we construct a curious agent building world models while visually exploring a 3D physical environment rich with distillations of representative real-world agents. We propose an AWML system driven by $\gamma$-Progress: a scalable and effective learning progress-based curiosity signal. We show that $\gamma$-Progress naturally gives rise to an exploration policy that directs attention to complex but learnable dynamics in a balanced manner, thus overcoming the "white noise problem". As a result, our $\gamma$-Progress-driven controller achieves significantly higher AWML performance than baseline controllers equipped with state-of-the-art exploration strategies such as Random Network Distillation and Model Disagreement.
On Mutual Information in Contrastive Learning for Visual Representations
Jun 05, 2020
In recent years, several unsupervised, "contrastive" learning algorithms in vision have been shown to learn representations that perform remarkably well on transfer tasks. We show that this family of algorithms maximizes a lower bound on the mutual information between two or more "views" of an image where typical views come from a composition of image augmentations. Our bound generalizes the InfoNCE objective to support negative sampling from a restricted region of "difficult" contrasts. We find that the choice of negative samples and views are critical to the success of these algorithms. Reformulating previous learning objectives in terms of mutual information also simplifies and stabilizes them. In practice, our new objectives yield representations that outperform those learned with previous approaches for transfer to classification, bounding box detection, instance segmentation, and keypoint detection. % experiments show that choosing more difficult negative samples results in a stronger representation, outperforming those learned with IR, LA, and CMC in classification, bounding box detection, instance segmentation, and keypoint detection. The mutual information framework provides a unifying comparison of approaches to contrastive learning and uncovers the choices that impact representation learning.
Flexible and Efficient Long-Range Planning Through Curious Exploration
Apr 22, 2020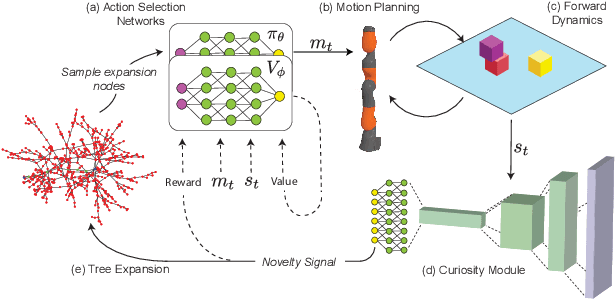
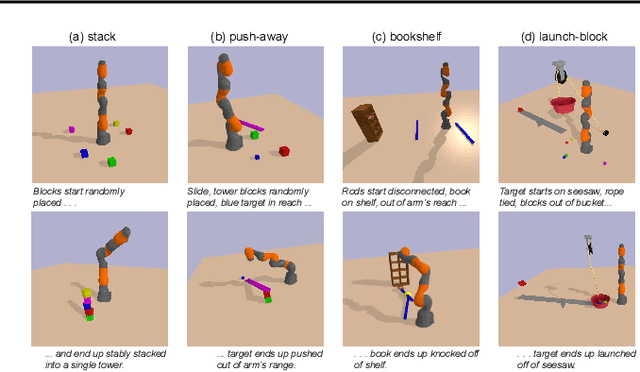
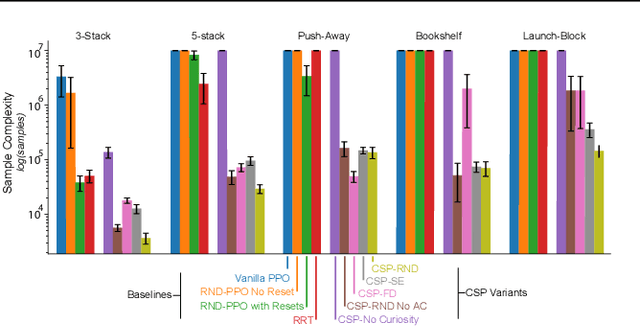
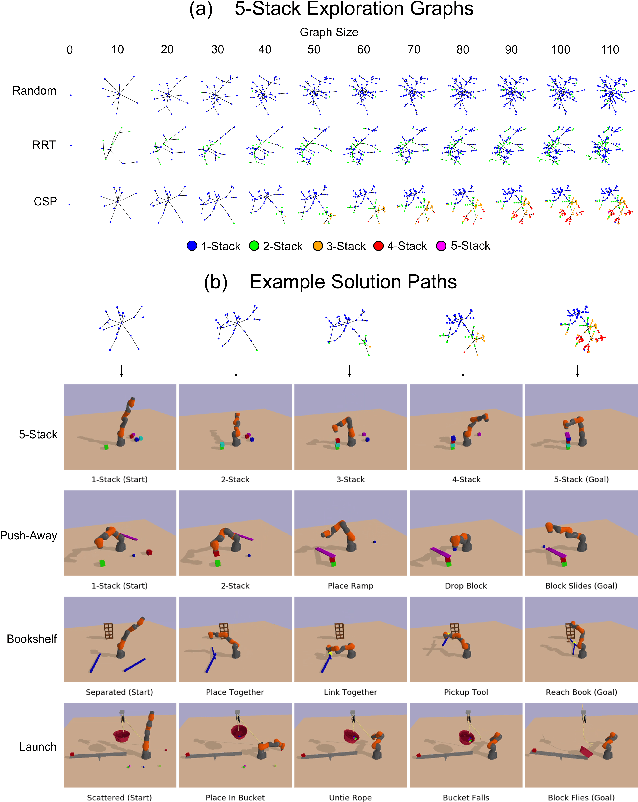
Identifying algorithms that flexibly and efficiently discover temporally-extended multi-phase plans is an essential step for the advancement of robotics and model-based reinforcement learning. The core problem of long-range planning is finding an efficient way to search through the tree of possible action sequences. Existing non-learned planning solutions from the Task and Motion Planning (TAMP) literature rely on the existence of logical descriptions for the effects and preconditions for actions. This constraint allows TAMP methods to efficiently reduce the tree search problem but limits their ability to generalize to unseen and complex physical environments. In contrast, deep reinforcement learning (DRL) methods use flexible neural-network-based function approximators to discover policies that generalize naturally to unseen circumstances. However, DRL methods struggle to handle the very sparse reward landscapes inherent to long-range multi-step planning situations. Here, we propose the Curious Sample Planner (CSP), which fuses elements of TAMP and DRL by combining a curiosity-guided sampling strategy with imitation learning to accelerate planning. We show that CSP can efficiently discover interesting and complex temporally-extended plans for solving a wide range of physically realistic 3D tasks. In contrast, standard planning and learning methods often fail to solve these tasks at all or do so only with a huge and highly variable number of training samples. We explore the use of a variety of curiosity metrics with CSP and analyze the types of solutions that CSP discovers. Finally, we show that CSP supports task transfer so that the exploration policies learned during experience with one task can help improve efficiency on related tasks.
Unsupervised Learning from Video with Deep Neural Embeddings
May 28, 2019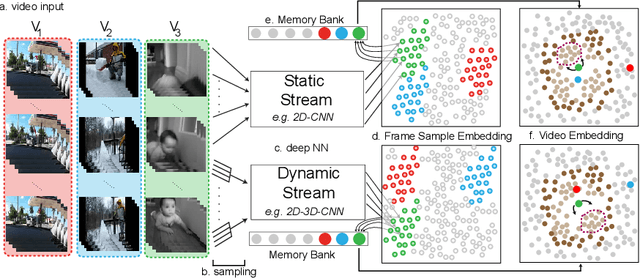



Because of the rich dynamical structure of videos and their ubiquity in everyday life, it is a natural idea that video data could serve as a powerful unsupervised learning signal for training visual representations in deep neural networks. However, instantiating this idea, especially at large scale, has remained a significant artificial intelligence challenge. Here we present the Video Instance Embedding (VIE) framework, which extends powerful recent unsupervised loss functions for learning deep nonlinear embeddings to multi-stream temporal processing architectures on large-scale video datasets. We show that VIE-trained networks substantially advance the state of the art in unsupervised learning from video datastreams, both for action recognition in the Kinetics dataset, and object recognition in the ImageNet dataset. We show that a hybrid model with both static and dynamic processing pathways is optimal for both transfer tasks, and provide analyses indicating how the pathways differ. Taken in context, our results suggest that deep neural embeddings are a promising approach to unsupervised visual learning across a wide variety of domains.
Local Label Propagation for Large-Scale Semi-Supervised Learning
May 28, 2019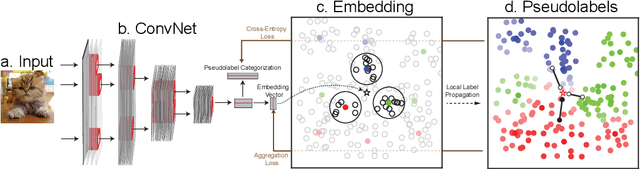
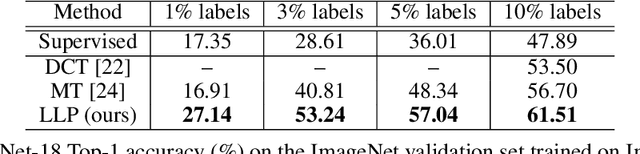
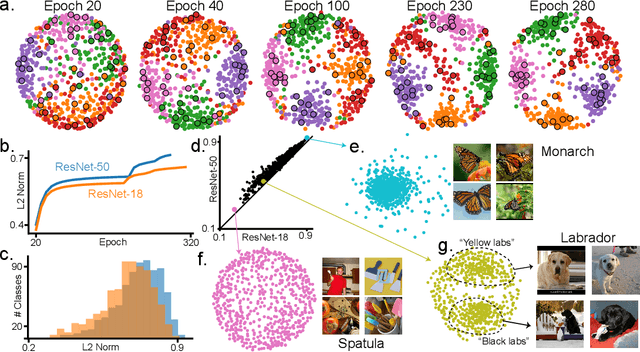
A significant issue in training deep neural networks to solve supervised learning tasks is the need for large numbers of labelled datapoints. The goal of semi-supervised learning is to leverage ubiquitous unlabelled data, together with small quantities of labelled data, to achieve high task performance. Though substantial recent progress has been made in developing semi-supervised algorithms that are effective for comparatively small datasets, many of these techniques do not scale readily to the large (unlaballed) datasets characteristic of real-world applications. In this paper we introduce a novel approach to scalable semi-supervised learning, called Local Label Propagation (LLP). Extending ideas from recent work on unsupervised embedding learning, LLP first embeds datapoints, labelled and otherwise, in a common latent space using a deep neural network. It then propagates pseudolabels from known to unknown datapoints in a manner that depends on the local geometry of the embedding, taking into account both inter-point distance and local data density as a weighting on propagation likelihood. The parameters of the deep embedding are then trained to simultaneously maximize pseudolabel categorization performance as well as a metric of the clustering of datapoints within each psuedo-label group, iteratively alternating stages of network training and label propagation. We illustrate the utility of the LLP method on the ImageNet dataset, achieving results that outperform previous state-of-the-art scalable semi-supervised learning algorithms by large margins, consistently across a wide variety of training regimes. We also show that the feature representation learned with LLP transfers well to scene recognition in the Places 205 dataset.
Local Aggregation for Unsupervised Learning of Visual Embeddings
Apr 10, 2019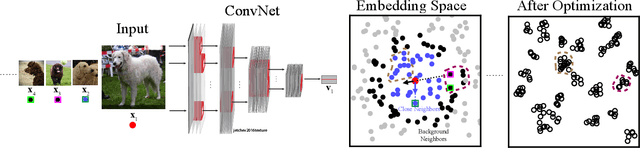

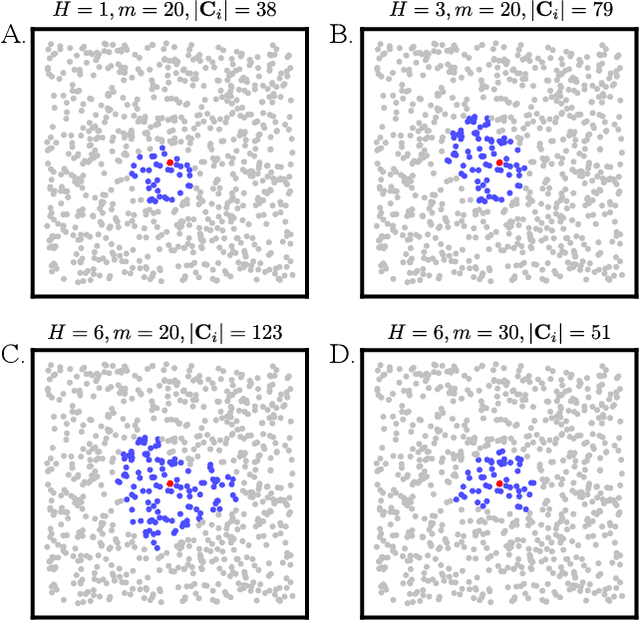
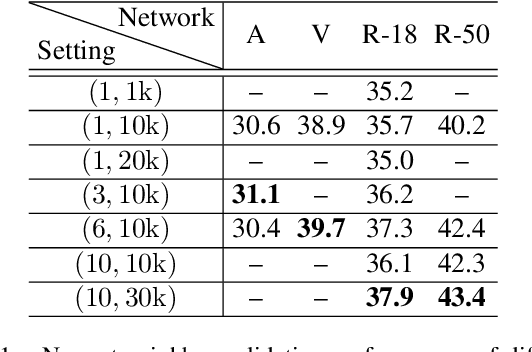
Unsupervised approaches to learning in neural networks are of substantial interest for furthering artificial intelligence, both because they would enable the training of networks without the need for large numbers of expensive annotations, and because they would be better models of the kind of general-purpose learning deployed by humans. However, unsupervised networks have long lagged behind the performance of their supervised counterparts, especially in the domain of large-scale visual recognition. Recent developments in training deep convolutional embeddings to maximize non-parametric instance separation and clustering objectives have shown promise in closing this gap. Here, we describe a method that trains an embedding function to maximize a metric of local aggregation, causing similar data instances to move together in the embedding space, while allowing dissimilar instances to separate. This aggregation metric is dynamic, allowing soft clusters of different scales to emerge. We evaluate our procedure on several large-scale visual recognition datasets, achieving state-of-the-art unsupervised transfer learning performance on object recognition in ImageNet, scene recognition in Places 205, and object detection in PASCAL VOC.
Toward Goal-Driven Neural Network Models for the Rodent Whisker-Trigeminal System
Jun 23, 2017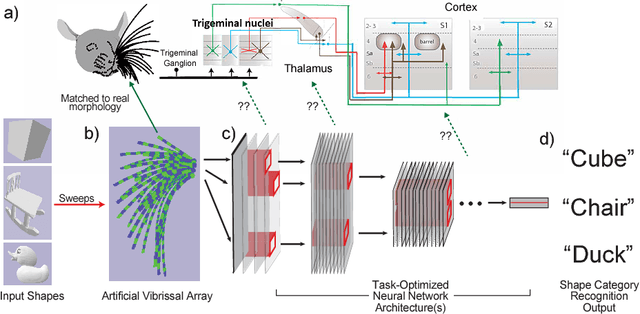
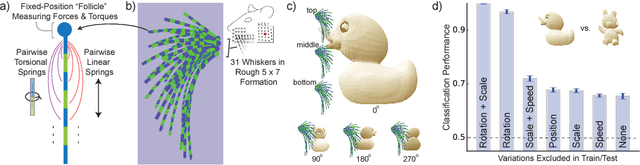
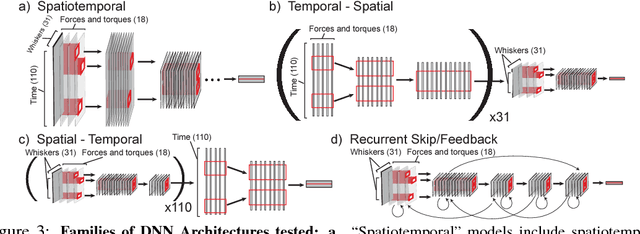
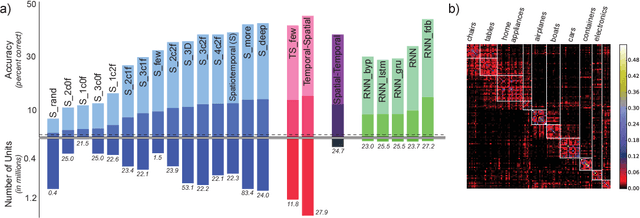
In large part, rodents see the world through their whiskers, a powerful tactile sense enabled by a series of brain areas that form the whisker-trigeminal system. Raw sensory data arrives in the form of mechanical input to the exquisitely sensitive, actively-controllable whisker array, and is processed through a sequence of neural circuits, eventually arriving in cortical regions that communicate with decision-making and memory areas. Although a long history of experimental studies has characterized many aspects of these processing stages, the computational operations of the whisker-trigeminal system remain largely unknown. In the present work, we take a goal-driven deep neural network (DNN) approach to modeling these computations. First, we construct a biophysically-realistic model of the rat whisker array. We then generate a large dataset of whisker sweeps across a wide variety of 3D objects in highly-varying poses, angles, and speeds. Next, we train DNNs from several distinct architectural families to solve a shape recognition task in this dataset. Each architectural family represents a structurally-distinct hypothesis for processing in the whisker-trigeminal system, corresponding to different ways in which spatial and temporal information can be integrated. We find that most networks perform poorly on the challenging shape recognition task, but that specific architectures from several families can achieve reasonable performance levels. Finally, we show that Representational Dissimilarity Matrices (RDMs), a tool for comparing population codes between neural systems, can separate these higher-performing networks with data of a type that could plausibly be collected in a neurophysiological or imaging experiment. Our results are a proof-of-concept that goal-driven DNN networks of the whisker-trigeminal system are potentially within reach.