 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying the Mechanisms Behind Emergent Exploration in Goal-conditioned RL
Oct 15, 2025In this work, we take a first step toward elucidating the mechanisms behind emergent exploration in unsupervised reinforcement learning. We study Single-Goal Contrastive Reinforcement Learning (SGCRL), a self-supervised algorithm capable of solving challenging long-horizon goal-reaching tasks without external rewards or curricula. We combine theoretical analysis of the algorithm's objective function with controlled experiments to understand what drives its exploration. We show that SGCRL maximizes implicit rewards shaped by its learned representations. These representations automatically modify the reward landscape to promote exploration before reaching the goal and exploitation thereafter. Our experiments also demonstrate that these exploration dynamics arise from learning low-rank representations of the state space rather than from neural network function approximation. Our improved understanding enables us to adapt SGCRL to perform safety-aware exploration.
Are Large Language Models Reliable AI Scientists? Assessing Reverse-Engineering of Black-Box Systems
May 23, 2025Using AI to create autonomous researchers has the potential to accelerate scientific discovery. A prerequisite for this vision is understanding how well an AI model can identify the underlying structure of a black-box system from its behavior. In this paper, we explore how well a large language model (LLM) learns to identify a black-box function from passively observed versus actively collected data. We investigate the reverse-engineering capabilities of LLMs across three distinct types of black-box systems, each chosen to represent different problem domains where future autonomous AI researchers may have considerable impact: Program, Formal Language, and Math Equation. Through extensive experiments, we show that LLMs fail to extract information from observations, reaching a performance plateau that falls short of the ideal of Bayesian inference. However, we demonstrate that prompting LLMs to not only observe but also intervene -- actively querying the black-box with specific inputs to observe the resulting output -- improves performance by allowing LLMs to test edge cases and refine their beliefs. By providing the intervention data from one LLM to another, we show that this improvement is partly a result of engaging in the process of generating effective interventions, paralleling results in the literature on human learning. Further analysis reveals that engaging in intervention can help LLMs escape from two common failure modes: overcomplication, where the LLM falsely assumes prior knowledge about the black-box, and overlooking, where the LLM fails to incorporate observations. These insights provide practical guidance for helping LLMs more effectively reverse-engineer black-box systems, supporting their use in making new discoveries.
Using Reinforcement Learning to Train Large Language Models to Explain Human Decisions
May 16, 2025



A central goal of cognitive modeling is to develop models that not only predict human behavior but also provide insight into the underlying cognitive mechanisms. While neural network models trained on large-scale behavioral data often achieve strong predictive performance, they typically fall short in offering interpretable explanations of the cognitive processes they capture. In this work, we explore the potential of pretrained large language models (LLMs) to serve as dual-purpose cognitive models--capable of both accurate prediction and interpretable explanation in natural language. Specifically, we employ reinforcement learning with outcome-based rewards to guide LLMs toward generating explicit reasoning traces for explaining human risky choices. Our findings demonstrate that this approach produces high-quality explanations alongside strong quantitative predictions of human decisions.
Toward Efficient Exploration by Large Language Model Agents
Apr 29, 2025A burgeoning area within reinforcement learning (RL) is the design of sequential decision-making agents centered around large language models (LLMs). While autonomous decision-making agents powered by modern LLMs could facilitate numerous real-world applications, such successes demand agents that are capable of data-efficient RL. One key obstacle to achieving data efficiency in RL is exploration, a challenge that we demonstrate many recent proposals for LLM agent designs struggle to contend with. Meanwhile, classic algorithms from the RL literature known to gracefully address exploration require technical machinery that can be challenging to operationalize in purely natural language settings. In this work, rather than relying on finetuning or in-context learning to coax LLMs into implicitly imitating a RL algorithm, we illustrate how LLMs can be used to explicitly implement an existing RL algorithm (Posterior Sampling for Reinforcement Learning) whose capacity for statistically-efficient exploration is already well-studied. We offer empirical results demonstrating how our LLM-based implementation of a known, data-efficient RL algorithm can be considerably more effective in natural language tasks that demand prudent exploration.
Satisficing Exploration for Deep Reinforcement Learning
Jul 16, 2024



A default assumption in the design of reinforcement-learning algorithms is that a decision-making agent always explores to learn optimal behavior. In sufficiently complex environments that approach the vastness and scale of the real world, however, attaining optimal performance may in fact be an entirely intractable endeavor and an agent may seldom find itself in a position to complete the requisite exploration for identifying an optimal policy. Recent work has leveraged tools from information theory to design agents that deliberately forgo optimal solutions in favor of sufficiently-satisfying or satisficing solutions, obtained through lossy compression. Notably, such agents may employ fundamentally different exploratory decisions to learn satisficing behaviors more efficiently than optimal ones that are more data intensive. While supported by a rigorous corroborating theory, the underlying algorithm relies on model-based planning, drastically limiting the compatibility of these ideas with function approximation and high-dimensional observations. In this work, we remedy this issue by extending an agent that directly represents uncertainty over the optimal value function allowing it to both bypass the need for model-based planning and to learn satisficing policies. We provide simple yet illustrative experiments that demonstrate how our algorithm enables deep reinforcement-learning agents to achieve satisficing behaviors. In keeping with previous work on this setting for multi-armed bandits, we additionally find that our algorithm is capable of synthesizing optimal behaviors, when feasible, more efficiently than its non-information-theoretic counterpart.
Exploration Unbound
Jul 16, 2024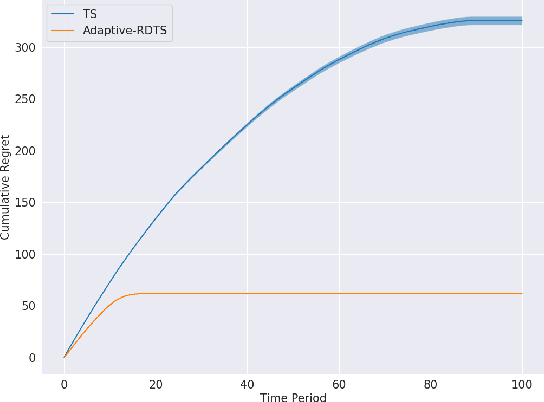
A sequential decision-making agent balances between exploring to gain new knowledge about an environment and exploiting current knowledge to maximize immediate reward. For environments studied in the traditional literature, optimal decisions gravitate over time toward exploitation as the agent accumulates sufficient knowledge and the benefits of further exploration vanish. What if, however, the environment offers an unlimited amount of useful knowledge and there is large benefit to further exploration no matter how much the agent has learned? We offer a simple, quintessential example of such a complex environment. In this environment, rewards are unbounded and an agent can always increase the rate at which rewards accumulate by exploring to learn more. Consequently, an optimal agent forever maintains a propensity to explore.
Social Contract AI: Aligning AI Assistants with Implicit Group Norms
Oct 26, 2023We explore the idea of aligning an AI assistant by inverting a model of users' (unknown) preferences from observed interactions. To validate our proposal, we run proof-of-concept simulations in the economic ultimatum game, formalizing user preferences as policies that guide the actions of simulated players. We find that the AI assistant accurately aligns its behavior to match standard policies from the economic literature (e.g., selfish, altruistic). However, the assistant's learned policies lack robustness and exhibit limited generalization in an out-of-distribution setting when confronted with a currency (e.g., grams of medicine) that was not included in the assistant's training distribution. Additionally, we find that when there is inconsistency in the relationship between language use and an unknown policy (e.g., an altruistic policy combined with rude language), the assistant's learning of the policy is slowed. Overall, our preliminary results suggest that developing simulation frameworks in which AI assistants need to infer preferences from diverse users can provide a valuable approach for studying practical alignment questions.
Hindsight-DICE: Stable Credit Assignment for Deep Reinforcement Learning
Jul 21, 2023Oftentimes, environments for sequential decision-making problems can be quite sparse in the provision of evaluative feedback to guide reinforcement-learning agents. In the extreme case, long trajectories of behavior are merely punctuated with a single terminal feedback signal, engendering a significant temporal delay between the observation of non-trivial reward and the individual steps of behavior culpable for eliciting such feedback. Coping with such a credit assignment challenge is one of the hallmark characteristics of reinforcement learning and, in this work, we capitalize on existing importance-sampling ratio estimation techniques for off-policy evaluation to drastically improve the handling of credit assignment with policy-gradient methods. While the use of so-called hindsight policies offers a principled mechanism for reweighting on-policy data by saliency to the observed trajectory return, naively applying importance sampling results in unstable or excessively lagged learning. In contrast, our hindsight distribution correction facilitates stable, efficient learning across a broad range of environments where credit assignment plagues baseline methods.
Shattering the Agent-Environment Interface for Fine-Tuning Inclusive Language Models
May 19, 2023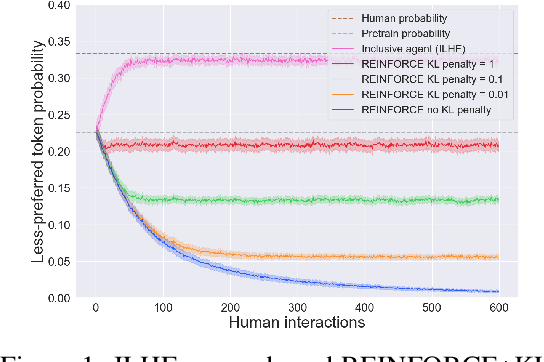
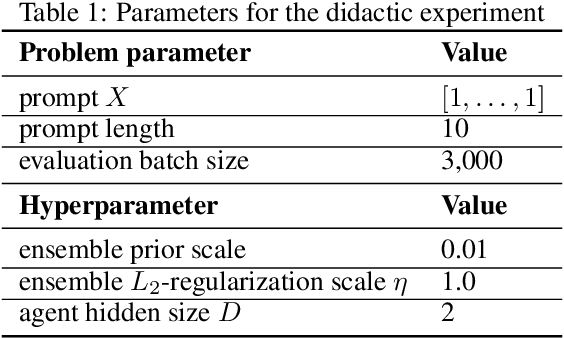
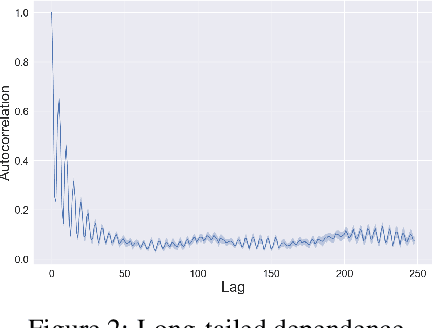

A centerpiece of the ever-popular reinforcement learning from human feedback (RLHF) approach to fine-tuning autoregressive language models is the explicit training of a reward model to emulate human feedback, distinct from the language model itself. This reward model is then coupled with policy-gradient methods to dramatically improve the alignment between language model outputs and desired responses. In this work, we adopt a novel perspective wherein a pre-trained language model is itself simultaneously a policy, reward function, and transition function. An immediate consequence of this is that reward learning and language model fine-tuning can be performed jointly and directly, without requiring any further downstream policy optimization. While this perspective does indeed break the traditional agent-environment interface, we nevertheless maintain that there can be enormous statistical benefits afforded by bringing to bear traditional algorithmic concepts from reinforcement learning. Our experiments demonstrate one concrete instance of this through efficient exploration based on the representation and resolution of epistemic uncertainty. In order to illustrate these ideas in a transparent manner, we restrict attention to a simple didactic data generating process and leave for future work extension to systems of practical scale.
Bayesian Reinforcement Learning with Limited Cognitive Load
May 05, 2023All biological and artificial agents must learn and make decisions given limits on their ability to process information. As such, a general theory of adaptive behavior should be able to account for the complex interactions between an agent's learning history, decisions, and capacity constraints. Recent work in computer science has begun to clarify the principles that shape these dynamics by bridging ideas from reinforcement learning, Bayesian decision-making, and rate-distortion theory. This body of work provides an account of capacity-limited Bayesian reinforcement learning, a unifying normative framework for modeling the effect of processing constraints on learning and action selection. Here, we provide an accessible review of recent algorithms and theoretical results in this setting, paying special attention to how these ideas can be applied to studying questions in the cognitive and behavioral sciences.