 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWILT: A Multi-Turn, Memorization-Robust Inductive Logic Benchmark for LLMs
Oct 14, 2024



While large language models have shown impressive capabilities across a wide range of domains, they still encounter significant challenges in reasoning tasks that require gathering evidence over multiple turns and drawing logical conclusions. These challenges present significant obstacles for LLM chat user interfaces, which rely on multi-turn interactions to facilitate effective collaboration. This limitation leads to real-world issues; for example, service chatbots must gather necessary information from customers over multiple turns to diagnose and resolve problems effectively. Despite the multi-turn nature of many real-world LLM use cases, most existing benchmarks rely on carefully curated single-turn tests, which often blur the line between memorization and genuine reasoning. To address this, we introduce the Wason Inductive Logic Test (WILT), a simple yet challenging multi-turn reasoning benchmark designed to resist memorization. WILT is inspired by the Wason 2-4-6 task, where participants must infer a boolean function involving three variables (e.g., $x < y < z$) by proposing test cases (such as $(2, 4, 6)$). In WILT, each test starts from a clean slate, with only the initial instructions provided, preventing models from relying on pre-learned responses. Over several turns, models must interact with the environment by suggesting test cases to narrow the possible hypotheses and ultimately infer the hidden function based on the outcomes. Our findings reveal that LLMs struggle with this task, exhibiting distinct strengths and weaknesses: some are better at narrowing down the hypothesis space by proposing valuable test cases, while others are more adept at deducing the hidden function from observed cases. Despite these variations, the best-performing model achieves only 28% accuracy, highlighting a significant gap in LLM performance on complex multi-turn reasoning tasks.
Differentiable Weight Masks for Domain Transfer
Aug 26, 2023

One of the major drawbacks of deep learning models for computer vision has been their inability to retain multiple sources of information in a modular fashion. For instance, given a network that has been trained on a source task, we would like to re-train this network on a similar, yet different, target task while maintaining its performance on the source task. Simultaneously, researchers have extensively studied modularization of network weights to localize and identify the set of weights culpable for eliciting the observed performance on a given task. One set of works studies the modularization induced in the weights of a neural network by learning and analysing weight masks. In this work, we combine these fields to study three such weight masking methods and analyse their ability to mitigate "forgetting'' on the source task while also allowing for efficient finetuning on the target task. We find that different masking techniques have trade-offs in retaining knowledge in the source task without adversely affecting target task performance.
Hindsight-DICE: Stable Credit Assignment for Deep Reinforcement Learning
Jul 21, 2023Oftentimes, environments for sequential decision-making problems can be quite sparse in the provision of evaluative feedback to guide reinforcement-learning agents. In the extreme case, long trajectories of behavior are merely punctuated with a single terminal feedback signal, engendering a significant temporal delay between the observation of non-trivial reward and the individual steps of behavior culpable for eliciting such feedback. Coping with such a credit assignment challenge is one of the hallmark characteristics of reinforcement learning and, in this work, we capitalize on existing importance-sampling ratio estimation techniques for off-policy evaluation to drastically improve the handling of credit assignment with policy-gradient methods. While the use of so-called hindsight policies offers a principled mechanism for reweighting on-policy data by saliency to the observed trajectory return, naively applying importance sampling results in unstable or excessively lagged learning. In contrast, our hindsight distribution correction facilitates stable, efficient learning across a broad range of environments where credit assignment plagues baseline methods.
PushWorld: A benchmark for manipulation planning with tools and movable obstacles
Feb 01, 2023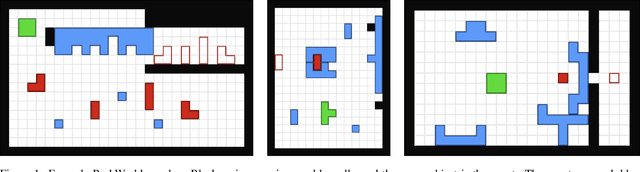

While recent advances in artificial intelligence have achieved human-level performance in environments like Starcraft and Go, many physical reasoning tasks remain challenging for modern algorithms. To date, few algorithms have been evaluated on physical tasks that involve manipulating objects when movable obstacles are present and when tools must be used to perform the manipulation. To promote research on such tasks, we introduce PushWorld, an environment with simplistic physics that requires manipulation planning with both movable obstacles and tools. We provide a benchmark of more than 200 PushWorld puzzles in PDDL and in an OpenAI Gym environment. We evaluate state-of-the-art classical planning and reinforcement learning algorithms on this benchmark, and we find that these baseline results are below human-level performance. We then provide a new classical planning heuristic that solves the most puzzles among the baselines, and although it is 40 times faster than the best baseline planner, it remains below human-level performance.
LISA: Learning Interpretable Skill Abstractions from Language
Feb 28, 2022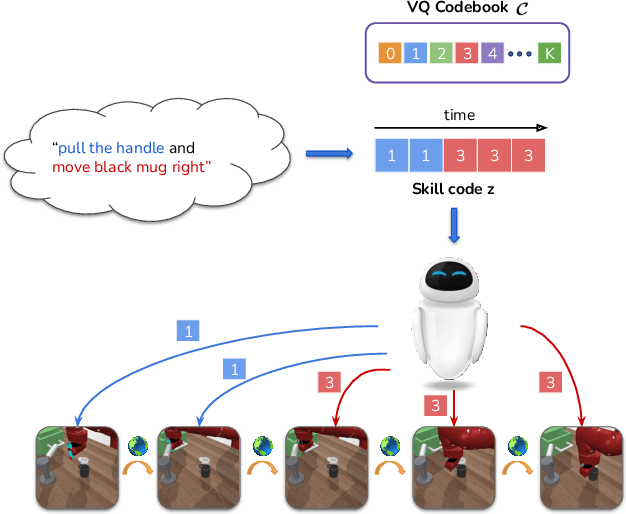

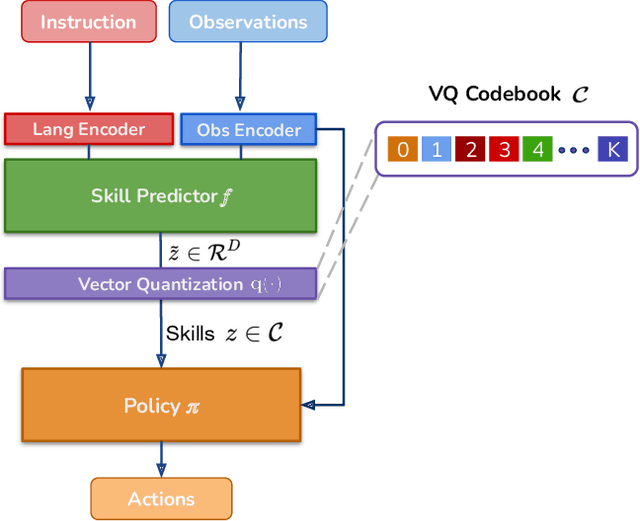

Learning policies that effectually utilize language instructions in complex, multi-task environments is an important problem in imitation learning. While it is possible to condition on the entire language instruction directly, such an approach could suffer from generalization issues. To encode complex instructions into skills that can generalize to unseen instructions, we propose Learning Interpretable Skill Abstractions (LISA), a hierarchical imitation learning framework that can learn diverse, interpretable skills from language-conditioned demonstrations. LISA uses vector quantization to learn discrete skill codes that are highly correlated with language instructions and the behavior of the learned policy. In navigation and robotic manipulation environments, LISA is able to outperform a strong non-hierarchical baseline in the low data regime and compose learned skills to solve tasks containing unseen long-range instructions. Our method demonstrates a more natural way to condition on language in sequential decision-making problems and achieve interpretable and controllable behavior with the learned skills.