 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWILT: A Multi-Turn, Memorization-Robust Inductive Logic Benchmark for LLMs
Oct 14, 2024



While large language models have shown impressive capabilities across a wide range of domains, they still encounter significant challenges in reasoning tasks that require gathering evidence over multiple turns and drawing logical conclusions. These challenges present significant obstacles for LLM chat user interfaces, which rely on multi-turn interactions to facilitate effective collaboration. This limitation leads to real-world issues; for example, service chatbots must gather necessary information from customers over multiple turns to diagnose and resolve problems effectively. Despite the multi-turn nature of many real-world LLM use cases, most existing benchmarks rely on carefully curated single-turn tests, which often blur the line between memorization and genuine reasoning. To address this, we introduce the Wason Inductive Logic Test (WILT), a simple yet challenging multi-turn reasoning benchmark designed to resist memorization. WILT is inspired by the Wason 2-4-6 task, where participants must infer a boolean function involving three variables (e.g., $x < y < z$) by proposing test cases (such as $(2, 4, 6)$). In WILT, each test starts from a clean slate, with only the initial instructions provided, preventing models from relying on pre-learned responses. Over several turns, models must interact with the environment by suggesting test cases to narrow the possible hypotheses and ultimately infer the hidden function based on the outcomes. Our findings reveal that LLMs struggle with this task, exhibiting distinct strengths and weaknesses: some are better at narrowing down the hypothesis space by proposing valuable test cases, while others are more adept at deducing the hidden function from observed cases. Despite these variations, the best-performing model achieves only 28% accuracy, highlighting a significant gap in LLM performance on complex multi-turn reasoning tasks.
Target Domain Data induces Negative Transfer in Mixed Domain Training with Disjoint Classes
Mar 02, 2023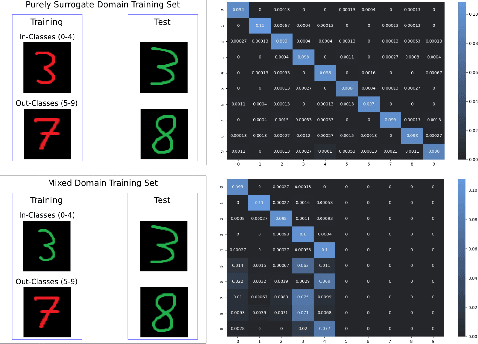

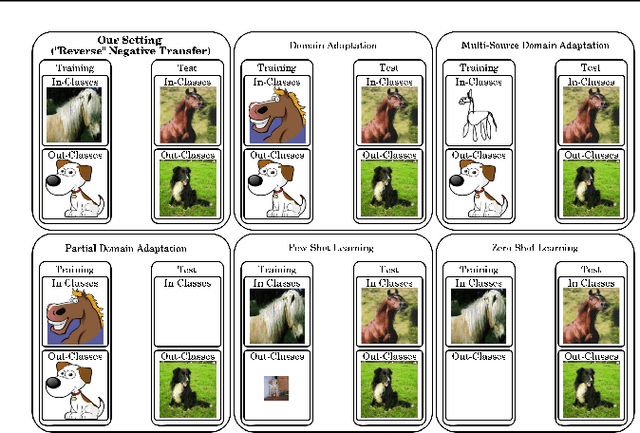
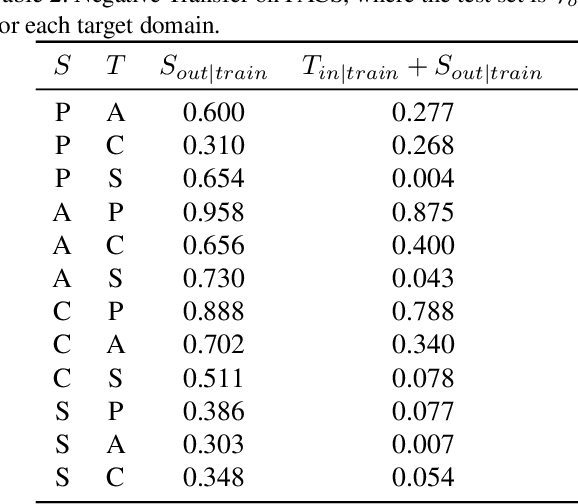
In practical scenarios, it is often the case that the available training data within the target domain only exist for a limited number of classes, with the remaining classes only available within surrogate domains. We show that including the target domain in training when there exist disjoint classes between the target and surrogate domains creates significant negative transfer, and causes performance to significantly decrease compared to training without the target domain at all. We hypothesize that this negative transfer is due to an intermediate shortcut that only occurs when multiple source domains are present, and provide experimental evidence that this may be the case. We show that this phenomena occurs on over 25 distinct domain shifts, both synthetic and real, and in many cases deteriorates the performance to well worse than random, even when using state-of-the-art domain adaptation methods.