 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget Domain Data induces Negative Transfer in Mixed Domain Training with Disjoint Classes
Mar 02, 2023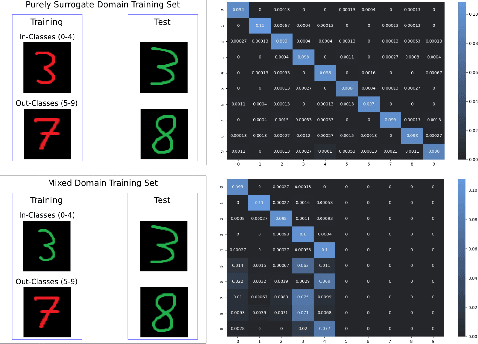

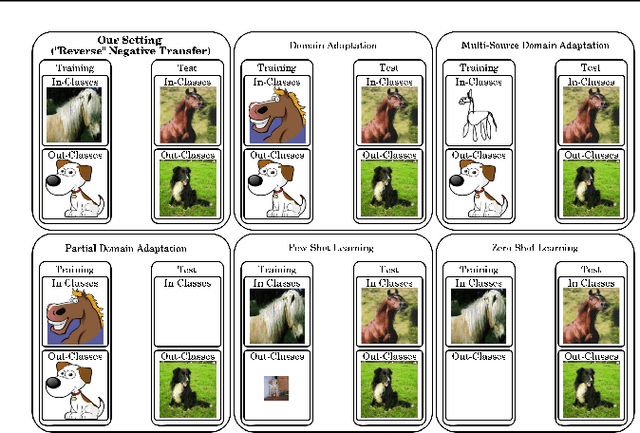
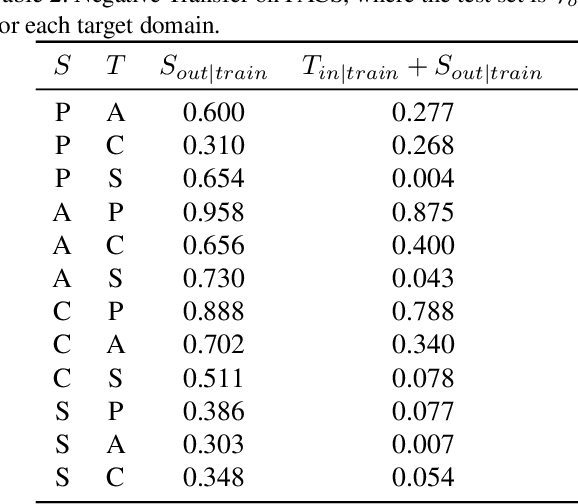
In practical scenarios, it is often the case that the available training data within the target domain only exist for a limited number of classes, with the remaining classes only available within surrogate domains. We show that including the target domain in training when there exist disjoint classes between the target and surrogate domains creates significant negative transfer, and causes performance to significantly decrease compared to training without the target domain at all. We hypothesize that this negative transfer is due to an intermediate shortcut that only occurs when multiple source domains are present, and provide experimental evidence that this may be the case. We show that this phenomena occurs on over 25 distinct domain shifts, both synthetic and real, and in many cases deteriorates the performance to well worse than random, even when using state-of-the-art domain adaptation methods.
Shape-Biased Domain Generalization via Shock Graph Embeddings
Sep 13, 2021
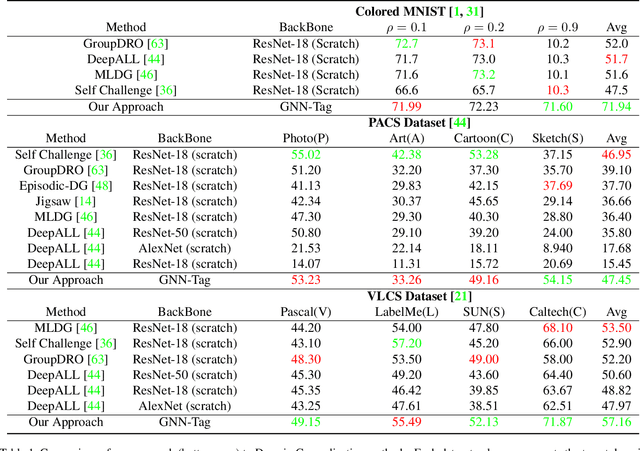

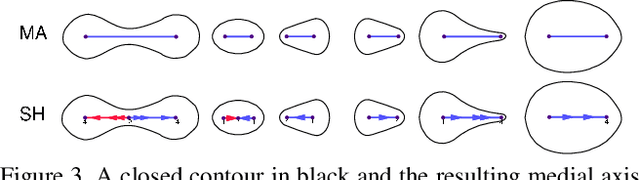
There is an emerging sense that the vulnerability of Image Convolutional Neural Networks (CNN), i.e., sensitivity to image corruptions, perturbations, and adversarial attacks, is connected with Texture Bias. This relative lack of Shape Bias is also responsible for poor performance in Domain Generalization (DG). The inclusion of a role of shape alleviates these vulnerabilities and some approaches have achieved this by training on negative images, images endowed with edge maps, or images with conflicting shape and texture information. This paper advocates an explicit and complete representation of shape using a classical computer vision approach, namely, representing the shape content of an image with the shock graph of its contour map. The resulting graph and its descriptor is a complete representation of contour content and is classified using recent Graph Neural Network (GNN) methods. The experimental results on three domain shift datasets, Colored MNIST, PACS, and VLCS demonstrate that even without using appearance the shape-based approach exceeds classical Image CNN based methods in domain generalization.
Accurate Layerwise Interpretable Competence Estimation
Oct 24, 2019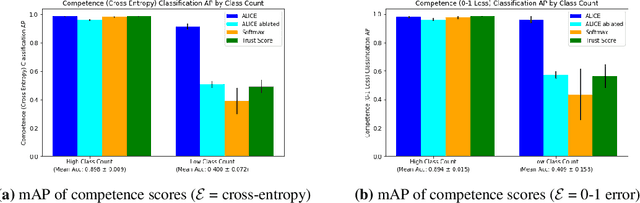
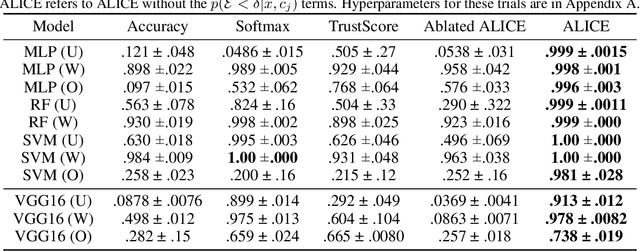
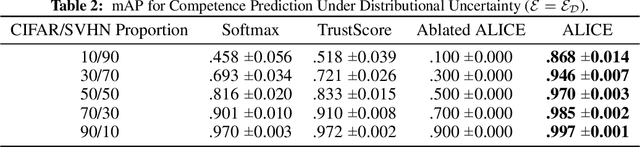
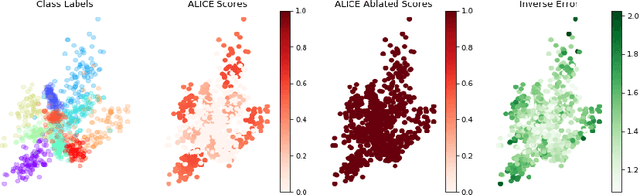
Estimating machine learning performance 'in the wild' is both an important and unsolved problem. In this paper, we seek to examine, understand, and predict the pointwise competence of classification models. Our contributions are twofold: First, we establish a statistically rigorous definition of competence that generalizes the common notion of classifier confidence; second, we present the ALICE (Accurate Layerwise Interpretable Competence Estimation) Score, a pointwise competence estimator for any classifier. By considering distributional, data, and model uncertainty, ALICE empirically shows accurate competence estimation in common failure situations such as class-imbalanced datasets, out-of-distribution datasets, and poorly trained models. Our contributions allow us to accurately predict the competence of any classification model given any input and error function. We compare our score with state-of-the-art confidence estimators such as model confidence and Trust Score, and show significant improvements in competence prediction over these methods on datasets such as DIGITS, CIFAR10, and CIFAR100.