 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiview Image-Based Localization
Mar 30, 2025



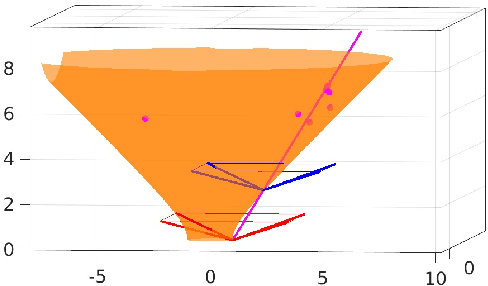
The image retrieval (IR) approach to image localization has distinct advantages to the 3D and the deep learning (DNN) approaches: it is seen-agnostic, simpler to implement and use, has no privacy issues, and is computationally efficient. The main drawback of this approach is relatively poor localization in both position and orientation of the query camera when compared to the competing approaches. This paper represents a hybrid approach that stores only image features in the database like some IR methods, but relies on a latent 3D reconstruction, like 3D methods but without retaining a 3D scene reconstruction. The approach is based on two ideas: {\em (i)} a novel proposal where query camera center estimation relies only on relative translation estimates but not relative rotation estimates through a decoupling of the two, and {\em (ii)} a shift from computing optimal pose from estimated relative pose to computing optimal pose from multiview correspondences, thus cutting out the ``middle-man''. Our approach shows improved performance on the 7-Scenes and Cambridge Landmarks datasets while also improving on timing and memory footprint as compared to state-of-the-art.
Geometry Depth Consistency in RGBD Relative Pose Estimation
Jan 01, 2024Relative pose estimation for RGBD cameras is crucial in a number of applications. Previous approaches either rely on the RGB aspect of the images to estimate pose thus not fully making use of depth in the estimation process or estimate pose from the 3D cloud of points that each image produces, thus not making full use of RGB information. This paper shows that if one pair of correspondences is hypothesized from the RGB-based ranked-ordered correspondence list, then the space of remaining correspondences is restricted to corresponding pairs of curves nested around the hypothesized correspondence, implicitly capturing depth consistency. This simple Geometric Depth Constraint (GDC) significantly reduces potential matches. In effect this becomes a filter on possible correspondences that helps reduce the number of outliers and thus expedites RANSAC significantly. As such, the same budget of time allows for more RANSAC iterations and therefore additional robustness and a significant speedup. In addition, the paper proposed a Nested RANSAC approach that also speeds up the process, as shown through experiments on TUM, ICL-NUIM, and RGBD Scenes v2 datasets.
Condition numbers in multiview geometry, instability in relative pose estimation, and RANSAC
Oct 04, 2023


In this paper we introduce a general framework for analyzing the numerical conditioning of minimal problems in multiple view geometry, using tools from computational algebra and Riemannian geometry. Special motivation comes from the fact that relative pose estimation, based on standard 5-point or 7-point Random Sample Consensus (RANSAC) algorithms, can fail even when no outliers are present and there is enough data to support a hypothesis. We argue that these cases arise due to the intrinsic instability of the 5- and 7-point minimal problems. We apply our framework to characterize the instabilities, both in terms of the world scenes that lead to infinite condition number, and directly in terms of ill-conditioned image data. The approach produces computational tests for assessing the condition number before solving the minimal problem. Lastly synthetic and real data experiments suggest that RANSAC serves not only to remove outliers, but also to select for well-conditioned image data, as predicted by our theory.
Generalized Relative Neighborhood Graph (GRNG) for Similarity Search
Aug 22, 2022



Similarity search is a fundamental building block for information retrieval on a variety of datasets. The notion of a neighbor is often based on binary considerations, such as the k nearest neighbors. However, considering that data is often organized as a manifold with low intrinsic dimension, the notion of a neighbor must recognize higher-order relationship, to capture neighbors in all directions. Proximity graphs, such as the Relative Neighbor Graphs (RNG), use trinary relationships which capture the notion of direction and have been successfully used in a number of applications. However, the current algorithms for computing the RNG, despite widespread use, are approximate and not scalable. This paper proposes a novel type of graph, the Generalized Relative Neighborhood Graph (GRNG) for use in a pivot layer that then guides the efficient and exact construction of the RNG of a set of exemplars. It also shows how to extend this to a multi-layer hierarchy which significantly improves over the state-of-the-art methods which can only construct an approximate RNG.
On the Instability of Relative Pose Estimation and RANSAC's Role
Dec 29, 2021
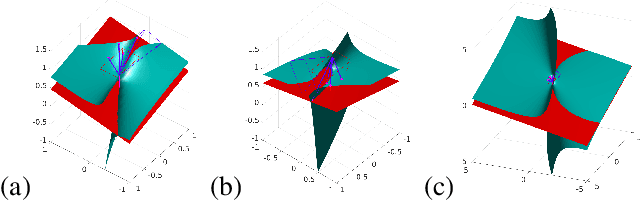

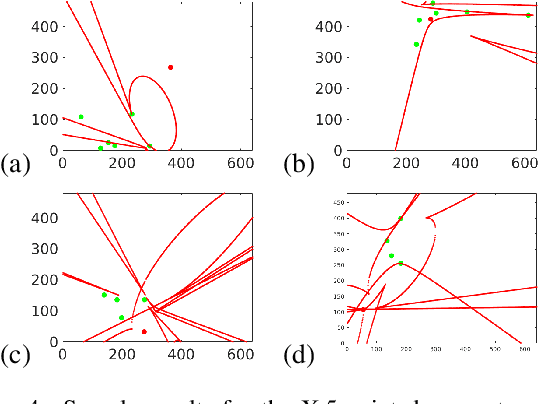
In this paper we study the numerical instabilities of the 5- and 7-point problems for essential and fundamental matrix estimation in multiview geometry. In both cases we characterize the ill-posed world scenes where the condition number for epipolar estimation is infinite. We also characterize the ill-posed instances in terms of the given image data. To arrive at these results, we present a general framework for analyzing the conditioning of minimal problems in multiview geometry, based on Riemannian manifolds. Experiments with synthetic and real-world data then reveal a striking conclusion: that Random Sample Consensus (RANSAC) in Structure-from-Motion (SfM) does not only serve to filter out outliers, but RANSAC also selects for well-conditioned image data, sufficiently separated from the ill-posed locus that our theory predicts. Our findings suggest that, in future work, one could try to accelerate and increase the success of RANSAC by testing only well-conditioned image data.
Benchmarking Pedestrian Odometry: The Brown Pedestrian Odometry Dataset (BPOD)
Dec 24, 2021
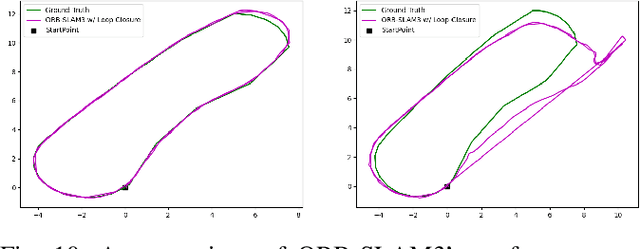
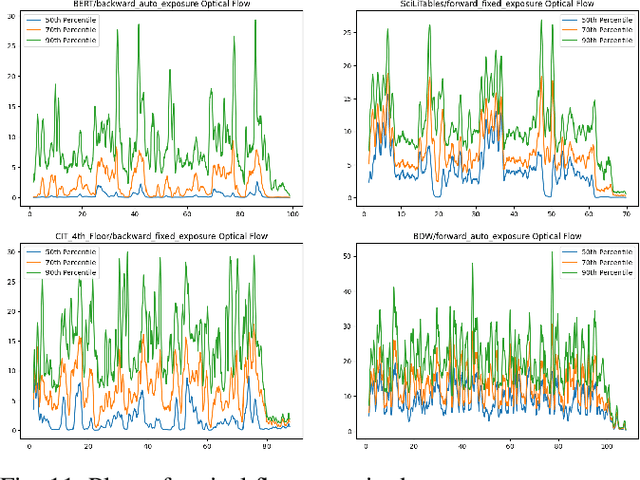

We present the Brown Pedestrian Odometry Dataset (BPOD) for benchmarking visual odometry algorithms in head-mounted pedestrian settings. This dataset was captured using synchronized global and rolling shutter stereo cameras in 12 diverse indoor and outdoor locations on Brown University's campus. Compared to existing datasets, BPOD contains more image blur and self-rotation, which are common in pedestrian odometry but rare elsewhere. Ground-truth trajectories are generated from stick-on markers placed along the pedestrian's path, and the pedestrian's position is documented using a third-person video. We evaluate the performance of representative direct, feature-based, and learning-based VO methods on BPOD. Our results show that significant development is needed to successfully capture pedestrian trajectories. The link to the dataset is here: \url{https://doi.org/10.26300/c1n7-7p93
GPU-Based Homotopy Continuation for Minimal Problems in Computer Vision
Dec 13, 2021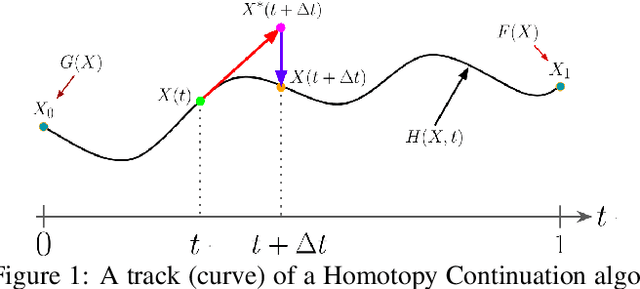
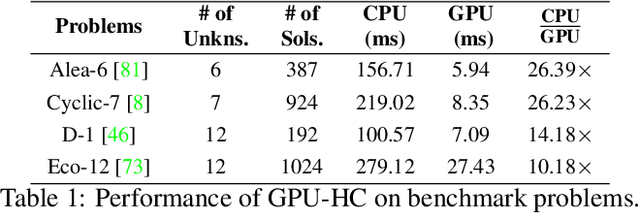
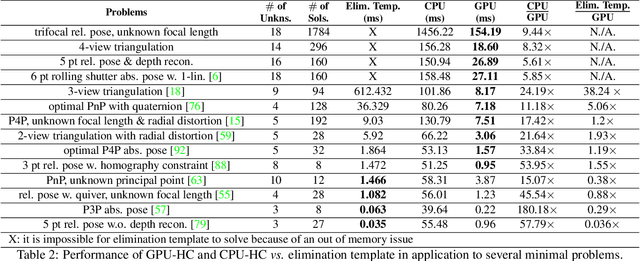
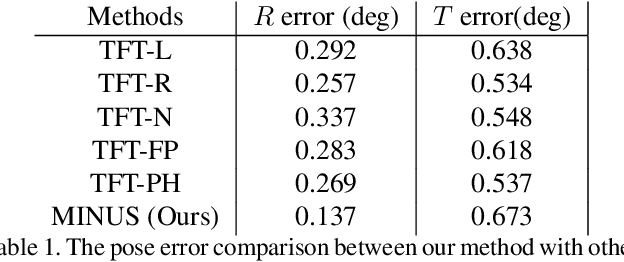
Systems of polynomial equations arise frequently in computer vision, especially in multiview geometry problems. Traditional methods for solving these systems typically aim to eliminate variables to reach a univariate polynomial, e.g., a tenth-order polynomial for 5-point pose estimation, using clever manipulations, or more generally using Grobner basis, resultants, and elimination templates, leading to successful algorithms for multiview geometry and other problems. However, these methods do not work when the problem is complex and when they do, they face efficiency and stability issues. Homotopy Continuation (HC) can solve more complex problems without the stability issues, and with guarantees of a global solution, but they are known to be slow. In this paper we show that HC can be parallelized on a GPU, showing significant speedups up to 26 times on polynomial benchmarks. We also show that GPU-HC can be generically applied to a range of computer vision problems, including 4-view triangulation and trifocal pose estimation with unknown focal length, which cannot be solved with elimination template but they can be efficiently solved with HC. GPU-HC opens the door to easy formulation and solution of a range of computer vision problems.
Shape-Biased Domain Generalization via Shock Graph Embeddings
Sep 13, 2021
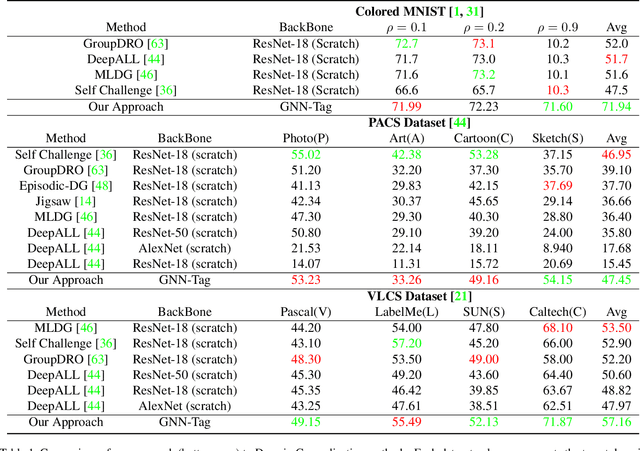

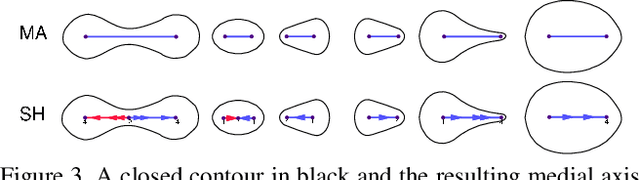
There is an emerging sense that the vulnerability of Image Convolutional Neural Networks (CNN), i.e., sensitivity to image corruptions, perturbations, and adversarial attacks, is connected with Texture Bias. This relative lack of Shape Bias is also responsible for poor performance in Domain Generalization (DG). The inclusion of a role of shape alleviates these vulnerabilities and some approaches have achieved this by training on negative images, images endowed with edge maps, or images with conflicting shape and texture information. This paper advocates an explicit and complete representation of shape using a classical computer vision approach, namely, representing the shape content of an image with the shock graph of its contour map. The resulting graph and its descriptor is a complete representation of contour content and is classified using recent Graph Neural Network (GNN) methods. The experimental results on three domain shift datasets, Colored MNIST, PACS, and VLCS demonstrate that even without using appearance the shape-based approach exceeds classical Image CNN based methods in domain generalization.
Trifocal Relative Pose from Lines at Points and its Efficient Solution
Apr 16, 2019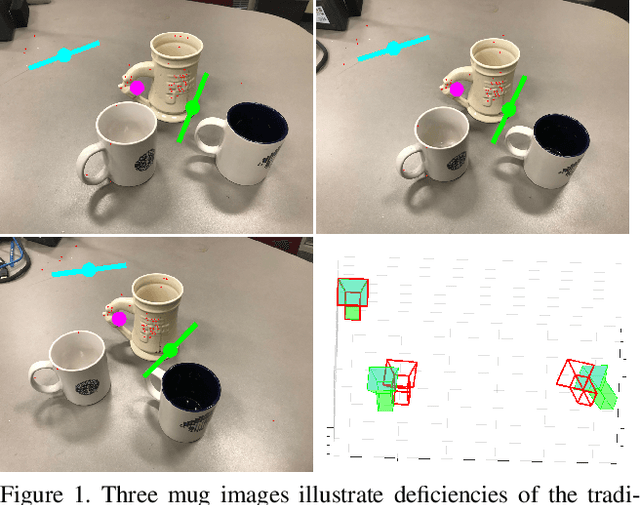
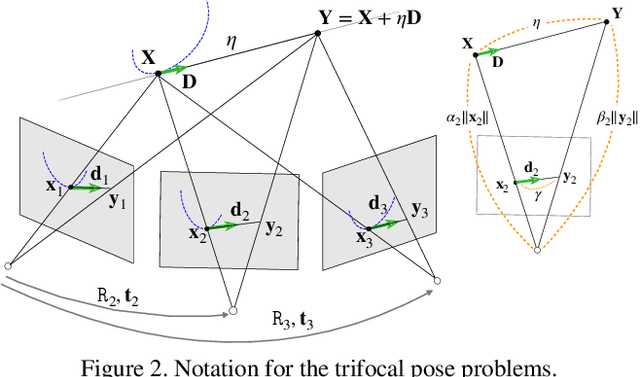

We present a new minimal problem for relative pose estimation mixing point features with lines incident at points observed in three views and its efficient homotopy continuation solver. We demonstrate the generality of the approach by analyzing and solving an additional problem with mixed point and line correspondences in three views. The minimal problems include correspondences of (i) three points and one line and (ii) three points and two lines through two of the points which is reported and analyzed here for the first time. These are difficult to solve, as they have 216 and - as shown here - 312 solutions, but cover important practical situations when line and point features appear together, e.g., in urban scenes or when observing curves. We demonstrate that even such difficult problems can be solved robustly using a suitable homotopy continuation technique and we provide an implementation optimized for minimal problems that can be integrated into engineering applications. Our simulated and real experiments demonstrate our solvers in the camera geometry computation task in structure from motion. We show that new solvers allow for reconstructing challenging scenes where the standard two-view initialization of structure from motion fails.
Robust pose tracking with a joint model of appearance and shape
Jun 28, 2018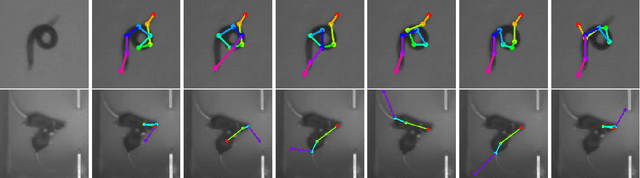
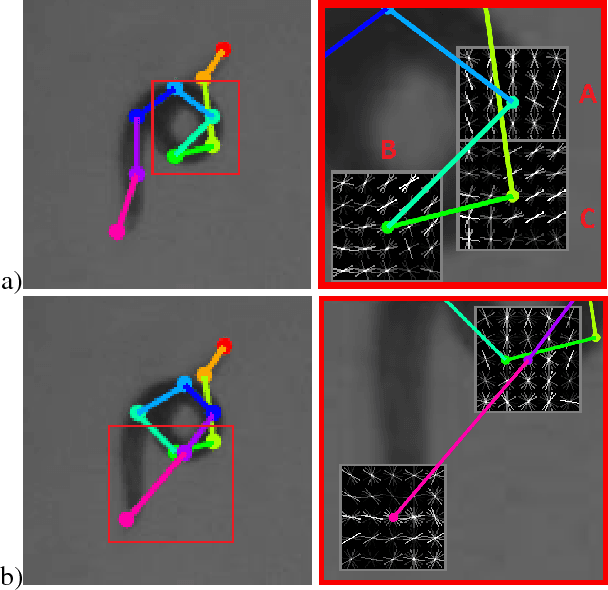
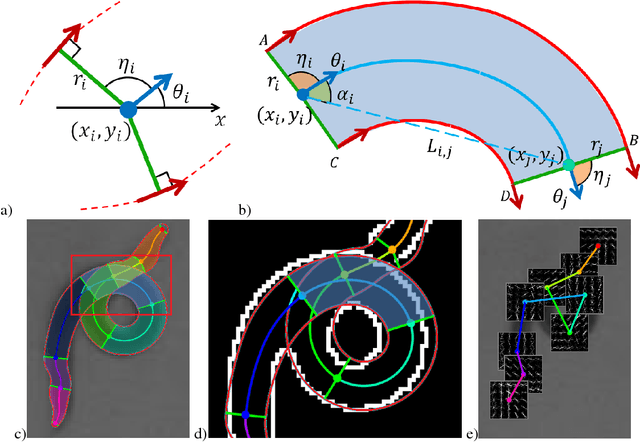
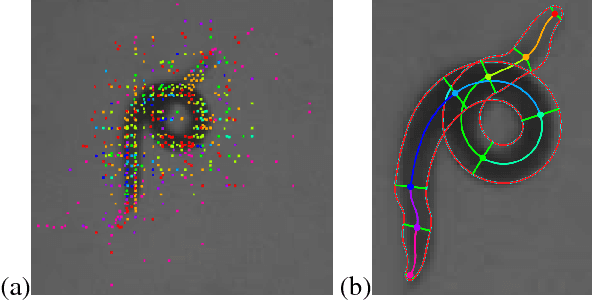
We present a novel approach for estimating the 2D pose of an articulated object with an application to automated video analysis of small laboratory animals. We have found that deformable part models developed for humans, exemplified by the flexible mixture of parts (FMP) model, typically fail on challenging animal poses. We argue that beyond encoding appearance and spatial relations, shape is needed to overcome the lack of distinctive landmarks on laboratory animal bodies. In our approach, a shape consistent FMP (scFMP) model computes promising pose candidates after a standard FMP model is used to rapidly discard false part detections. This "cascaded" approach combines the relative strengths of spatial-relations, appearance and shape representations and is shown to yield significant improvements over the original FMP model as well as a representative deep neural network baseline.