 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust pose tracking with a joint model of appearance and shape
Paper and Code
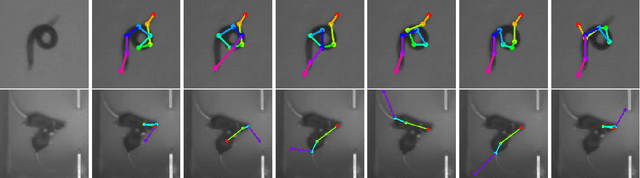
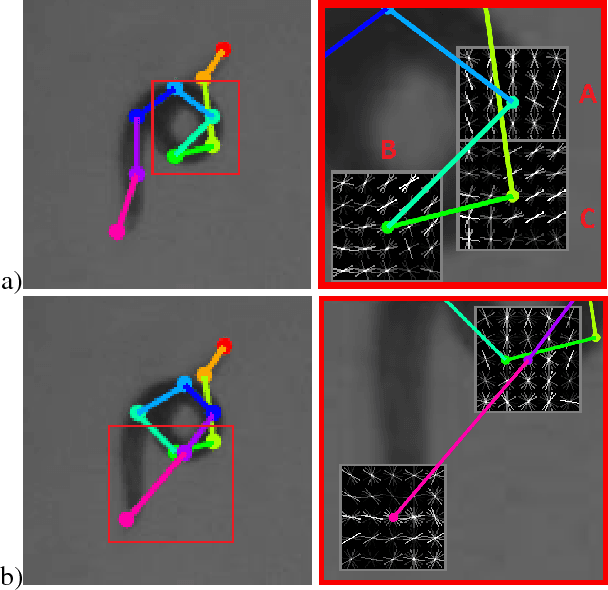
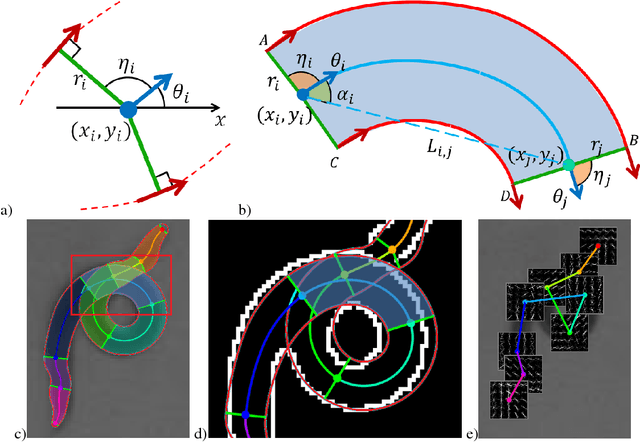
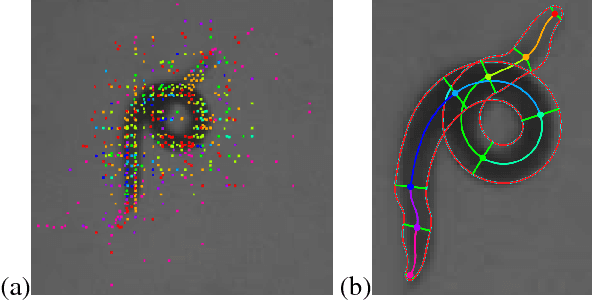
We present a novel approach for estimating the 2D pose of an articulated object with an application to automated video analysis of small laboratory animals. We have found that deformable part models developed for humans, exemplified by the flexible mixture of parts (FMP) model, typically fail on challenging animal poses. We argue that beyond encoding appearance and spatial relations, shape is needed to overcome the lack of distinctive landmarks on laboratory animal bodies. In our approach, a shape consistent FMP (scFMP) model computes promising pose candidates after a standard FMP model is used to rapidly discard false part detections. This "cascaded" approach combines the relative strengths of spatial-relations, appearance and shape representations and is shown to yield significant improvements over the original FMP model as well as a representative deep neural network baseline.