 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Knowledge Distillation for Embedding Refinement in Personalized Speech Enhancement
Jan 21, 2026Personalized speech enhancement (PSE) has shown convincing results when it comes to extracting a known target voice among interfering ones. The corresponding systems usually incorporate a representation of the target voice within the enhancement system, which is extracted from an enrollment clip of the target voice with upstream models. Those models are generally heavy as the speaker embedding's quality directly affects PSE performances. Yet, embeddings generated beforehand cannot account for the variations of the target voice during inference time. In this paper, we propose to perform on-thefly refinement of the speaker embedding using a tiny speaker encoder. We first introduce a novel contrastive knowledge distillation methodology in order to train a 150k-parameter encoder from complex embeddings. We then use this encoder within the enhancement system during inference and show that the proposed method greatly improves PSE performances while maintaining a low computational load.
GASPnet: Global Agreement to Synchronize Phases
Jul 22, 2025In recent years, Transformer architectures have revolutionized most fields of artificial intelligence, relying on an attentional mechanism based on the agreement between keys and queries to select and route information in the network. In previous work, we introduced a novel, brain-inspired architecture that leverages a similar implementation to achieve a global 'routing by agreement' mechanism. Such a system modulates the network's activity by matching each neuron's key with a single global query, pooled across the entire network. Acting as a global attentional system, this mechanism improves noise robustness over baseline levels but is insufficient for multi-classification tasks. Here, we improve on this work by proposing a novel mechanism that combines aspects of the Transformer attentional operations with a compelling neuroscience theory, namely, binding by synchrony. This theory proposes that the brain binds together features by synchronizing the temporal activity of neurons encoding those features. This allows the binding of features from the same object while efficiently disentangling those from distinct objects. We drew inspiration from this theory and incorporated angular phases into all layers of a convolutional network. After achieving phase alignment via Kuramoto dynamics, we use this approach to enhance operations between neurons with similar phases and suppresses those with opposite phases. We test the benefits of this mechanism on two datasets: one composed of pairs of digits and one composed of a combination of an MNIST item superimposed on a CIFAR-10 image. Our results reveal better accuracy than CNN networks, proving more robust to noise and with better generalization abilities. Overall, we propose a novel mechanism that addresses the visual binding problem in neural networks by leveraging the synergy between neuroscience and machine learning.
Follow the Energy, Find the Path: Riemannian Metrics from Energy-Based Models
May 23, 2025What is the shortest path between two data points lying in a high-dimensional space? While the answer is trivial in Euclidean geometry, it becomes significantly more complex when the data lies on a curved manifold -- requiring a Riemannian metric to describe the space's local curvature. Estimating such a metric, however, remains a major challenge in high dimensions. In this work, we propose a method for deriving Riemannian metrics directly from pretrained Energy-Based Models (EBMs) -- a class of generative models that assign low energy to high-density regions. These metrics define spatially varying distances, enabling the computation of geodesics -- shortest paths that follow the data manifold's intrinsic geometry. We introduce two novel metrics derived from EBMs and show that they produce geodesics that remain closer to the data manifold and exhibit lower curvature distortion, as measured by alignment with ground-truth trajectories. We evaluate our approach on increasingly complex datasets: synthetic datasets with known data density, rotated character images with interpretable geometry, and high-resolution natural images embedded in a pretrained VAE latent space. Our results show that EBM-derived metrics consistently outperform established baselines, especially in high-dimensional settings. Our work is the first to derive Riemannian metrics from EBMs, enabling data-aware geodesics and unlocking scalable, geometry-driven learning for generative modeling and simulation.
Enhancing deep neural networks through complex-valued representations and Kuramoto synchronization dynamics
Feb 28, 2025Neural synchrony is hypothesized to play a crucial role in how the brain organizes visual scenes into structured representations, enabling the robust encoding of multiple objects within a scene. However, current deep learning models often struggle with object binding, limiting their ability to represent multiple objects effectively. Inspired by neuroscience, we investigate whether synchrony-based mechanisms can enhance object encoding in artificial models trained for visual categorization. Specifically, we combine complex-valued representations with Kuramoto dynamics to promote phase alignment, facilitating the grouping of features belonging to the same object. We evaluate two architectures employing synchrony: a feedforward model and a recurrent model with feedback connections to refine phase synchronization using top-down information. Both models outperform their real-valued counterparts and complex-valued models without Kuramoto synchronization on tasks involving multi-object images, such as overlapping handwritten digits, noisy inputs, and out-of-distribution transformations. Our findings highlight the potential of synchrony-driven mechanisms to enhance deep learning models, improving their performance, robustness, and generalization in complex visual categorization tasks.
Local vs distributed representations: What is the right basis for interpretability?
Nov 06, 2024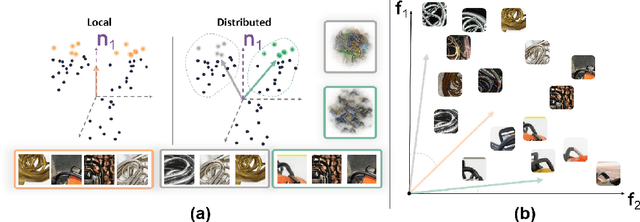


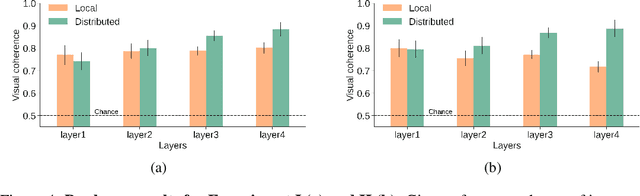
Much of the research on the interpretability of deep neural networks has focused on studying the visual features that maximally activate individual neurons. However, recent work has cast doubts on the usefulness of such local representations for understanding the behavior of deep neural networks because individual neurons tend to respond to multiple unrelated visual patterns, a phenomenon referred to as "superposition". A promising alternative to disentangle these complex patterns is learning sparsely distributed vector representations from entire network layers, as the resulting basis vectors seemingly encode single identifiable visual patterns consistently. Thus, one would expect the resulting code to align better with human perceivable visual patterns, but supporting evidence remains, at best, anecdotal. To fill this gap, we conducted three large-scale psychophysics experiments collected from a pool of 560 participants. Our findings provide (i) strong evidence that features obtained from sparse distributed representations are easier to interpret by human observers and (ii) that this effect is more pronounced in the deepest layers of a neural network. Complementary analyses also reveal that (iii) features derived from sparse distributed representations contribute more to the model's decision. Overall, our results highlight that distributed representations constitute a superior basis for interpretability, underscoring a need for the field to move beyond the interpretation of local neural codes in favor of sparsely distributed ones.
RTify: Aligning Deep Neural Networks with Human Behavioral Decisions
Nov 06, 2024



Current neural network models of primate vision focus on replicating overall levels of behavioral accuracy, often neglecting perceptual decisions' rich, dynamic nature. Here, we introduce a novel computational framework to model the dynamics of human behavioral choices by learning to align the temporal dynamics of a recurrent neural network (RNN) to human reaction times (RTs). We describe an approximation that allows us to constrain the number of time steps an RNN takes to solve a task with human RTs. The approach is extensively evaluated against various psychophysics experiments. We also show that the approximation can be used to optimize an "ideal-observer" RNN model to achieve an optimal tradeoff between speed and accuracy without human data. The resulting model is found to account well for human RT data. Finally, we use the approximation to train a deep learning implementation of the popular Wong-Wang decision-making model. The model is integrated with a convolutional neural network (CNN) model of visual processing and evaluated using both artificial and natural image stimuli. Overall, we present a novel framework that helps align current vision models with human behavior, bringing us closer to an integrated model of human vision.
Tracking objects that change in appearance with phase synchrony
Oct 02, 2024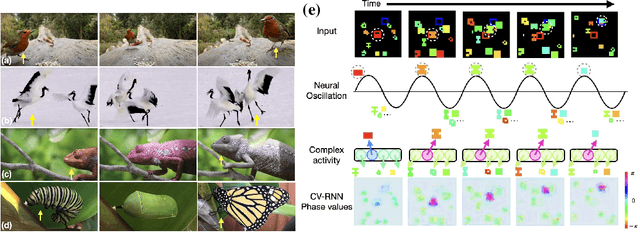
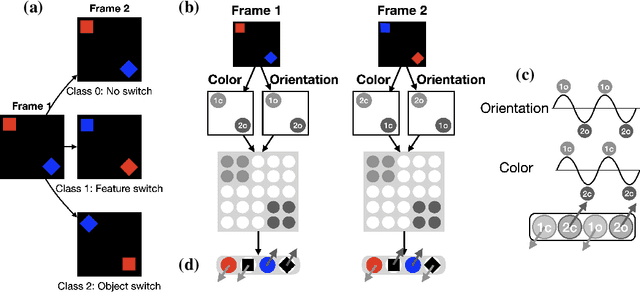
Objects we encounter often change appearance as we interact with them. Changes in illumination (shadows), object pose, or movement of nonrigid objects can drastically alter available image features. How do biological visual systems track objects as they change? It may involve specific attentional mechanisms for reasoning about the locations of objects independently of their appearances -- a capability that prominent neuroscientific theories have associated with computing through neural synchrony. We computationally test the hypothesis that the implementation of visual attention through neural synchrony underlies the ability of biological visual systems to track objects that change in appearance over time. We first introduce a novel deep learning circuit that can learn to precisely control attention to features separately from their location in the world through neural synchrony: the complex-valued recurrent neural network (CV-RNN). Next, we compare object tracking in humans, the CV-RNN, and other deep neural networks (DNNs), using FeatureTracker: a large-scale challenge that asks observers to track objects as their locations and appearances change in precisely controlled ways. While humans effortlessly solved FeatureTracker, state-of-the-art DNNs did not. In contrast, our CV-RNN behaved similarly to humans on the challenge, providing a computational proof-of-concept for the role of phase synchronization as a neural substrate for tracking appearance-morphing objects as they move about.
Understanding Visual Feature Reliance through the Lens of Complexity
Jul 08, 2024



Recent studies suggest that deep learning models inductive bias towards favoring simpler features may be one of the sources of shortcut learning. Yet, there has been limited focus on understanding the complexity of the myriad features that models learn. In this work, we introduce a new metric for quantifying feature complexity, based on $\mathscr{V}$-information and capturing whether a feature requires complex computational transformations to be extracted. Using this $\mathscr{V}$-information metric, we analyze the complexities of 10,000 features, represented as directions in the penultimate layer, that were extracted from a standard ImageNet-trained vision model. Our study addresses four key questions: First, we ask what features look like as a function of complexity and find a spectrum of simple to complex features present within the model. Second, we ask when features are learned during training. We find that simpler features dominate early in training, and more complex features emerge gradually. Third, we investigate where within the network simple and complex features flow, and find that simpler features tend to bypass the visual hierarchy via residual connections. Fourth, we explore the connection between features complexity and their importance in driving the networks decision. We find that complex features tend to be less important. Surprisingly, important features become accessible at earlier layers during training, like a sedimentation process, allowing the model to build upon these foundational elements.
Beyond the Doors of Perception: Vision Transformers Represent Relations Between Objects
Jun 22, 2024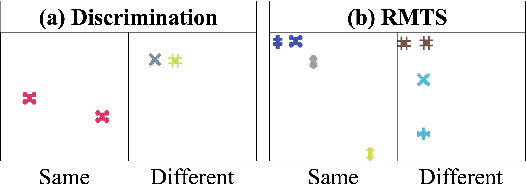
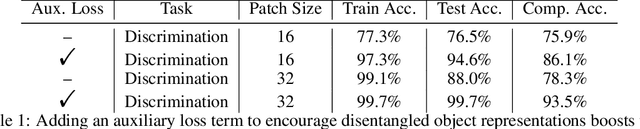
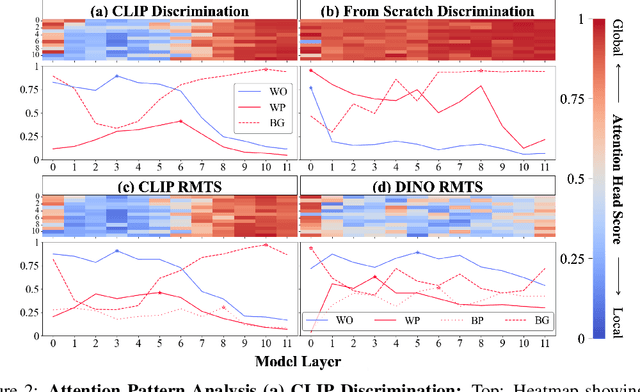
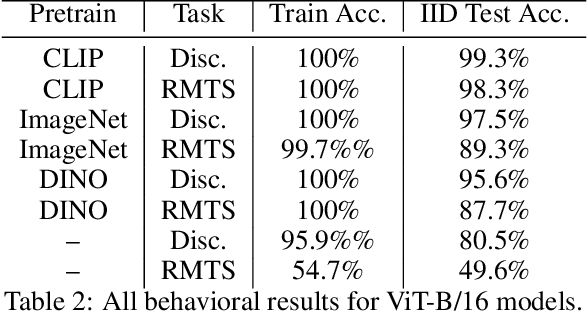
Though vision transformers (ViTs) have achieved state-of-the-art performance in a variety of settings, they exhibit surprising failures when performing tasks involving visual relations. This begs the question: how do ViTs attempt to perform tasks that require computing visual relations between objects? Prior efforts to interpret ViTs tend to focus on characterizing relevant low-level visual features. In contrast, we adopt methods from mechanistic interpretability to study the higher-level visual algorithms that ViTs use to perform abstract visual reasoning. We present a case study of a fundamental, yet surprisingly difficult, relational reasoning task: judging whether two visual entities are the same or different. We find that pretrained ViTs fine-tuned on this task often exhibit two qualitatively different stages of processing despite having no obvious inductive biases to do so: 1) a perceptual stage wherein local object features are extracted and stored in a disentangled representation, and 2) a relational stage wherein object representations are compared. In the second stage, we find evidence that ViTs can learn to represent somewhat abstract visual relations, a capability that has long been considered out of reach for artificial neural networks. Finally, we demonstrate that failure points at either stage can prevent a model from learning a generalizable solution to our fairly simple tasks. By understanding ViTs in terms of discrete processing stages, one can more precisely diagnose and rectify shortcomings of existing and future models.
Latent Representation Matters: Human-like Sketches in One-shot Drawing Tasks
Jun 10, 2024Humans can effortlessly draw new categories from a single exemplar, a feat that has long posed a challenge for generative models. However, this gap has started to close with recent advances in diffusion models. This one-shot drawing task requires powerful inductive biases that have not been systematically investigated. Here, we study how different inductive biases shape the latent space of Latent Diffusion Models (LDMs). Along with standard LDM regularizers (KL and vector quantization), we explore supervised regularizations (including classification and prototype-based representation) and contrastive inductive biases (using SimCLR and redundancy reduction objectives). We demonstrate that LDMs with redundancy reduction and prototype-based regularizations produce near-human-like drawings (regarding both samples' recognizability and originality) -- better mimicking human perception (as evaluated psychophysically). Overall, our results suggest that the gap between humans and machines in one-shot drawings is almost closed.