 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGASPnet: Global Agreement to Synchronize Phases
Jul 22, 2025In recent years, Transformer architectures have revolutionized most fields of artificial intelligence, relying on an attentional mechanism based on the agreement between keys and queries to select and route information in the network. In previous work, we introduced a novel, brain-inspired architecture that leverages a similar implementation to achieve a global 'routing by agreement' mechanism. Such a system modulates the network's activity by matching each neuron's key with a single global query, pooled across the entire network. Acting as a global attentional system, this mechanism improves noise robustness over baseline levels but is insufficient for multi-classification tasks. Here, we improve on this work by proposing a novel mechanism that combines aspects of the Transformer attentional operations with a compelling neuroscience theory, namely, binding by synchrony. This theory proposes that the brain binds together features by synchronizing the temporal activity of neurons encoding those features. This allows the binding of features from the same object while efficiently disentangling those from distinct objects. We drew inspiration from this theory and incorporated angular phases into all layers of a convolutional network. After achieving phase alignment via Kuramoto dynamics, we use this approach to enhance operations between neurons with similar phases and suppresses those with opposite phases. We test the benefits of this mechanism on two datasets: one composed of pairs of digits and one composed of a combination of an MNIST item superimposed on a CIFAR-10 image. Our results reveal better accuracy than CNN networks, proving more robust to noise and with better generalization abilities. Overall, we propose a novel mechanism that addresses the visual binding problem in neural networks by leveraging the synergy between neuroscience and machine learning.
Follow the Energy, Find the Path: Riemannian Metrics from Energy-Based Models
May 23, 2025What is the shortest path between two data points lying in a high-dimensional space? While the answer is trivial in Euclidean geometry, it becomes significantly more complex when the data lies on a curved manifold -- requiring a Riemannian metric to describe the space's local curvature. Estimating such a metric, however, remains a major challenge in high dimensions. In this work, we propose a method for deriving Riemannian metrics directly from pretrained Energy-Based Models (EBMs) -- a class of generative models that assign low energy to high-density regions. These metrics define spatially varying distances, enabling the computation of geodesics -- shortest paths that follow the data manifold's intrinsic geometry. We introduce two novel metrics derived from EBMs and show that they produce geodesics that remain closer to the data manifold and exhibit lower curvature distortion, as measured by alignment with ground-truth trajectories. We evaluate our approach on increasingly complex datasets: synthetic datasets with known data density, rotated character images with interpretable geometry, and high-resolution natural images embedded in a pretrained VAE latent space. Our results show that EBM-derived metrics consistently outperform established baselines, especially in high-dimensional settings. Our work is the first to derive Riemannian metrics from EBMs, enabling data-aware geodesics and unlocking scalable, geometry-driven learning for generative modeling and simulation.
Multimodal Dreaming: A Global Workspace Approach to World Model-Based Reinforcement Learning
Feb 28, 2025Humans leverage rich internal models of the world to reason about the future, imagine counterfactuals, and adapt flexibly to new situations. In Reinforcement Learning (RL), world models aim to capture how the environment evolves in response to the agent's actions, facilitating planning and generalization. However, typical world models directly operate on the environment variables (e.g. pixels, physical attributes), which can make their training slow and cumbersome; instead, it may be advantageous to rely on high-level latent dimensions that capture relevant multimodal variables. Global Workspace (GW) Theory offers a cognitive framework for multimodal integration and information broadcasting in the brain, and recent studies have begun to introduce efficient deep learning implementations of GW. Here, we evaluate the capabilities of an RL system combining GW with a world model. We compare our GW-Dreamer with various versions of the standard PPO and the original Dreamer algorithms. We show that performing the dreaming process (i.e., mental simulation) inside the GW latent space allows for training with fewer environment steps. As an additional emergent property, the resulting model (but not its comparison baselines) displays strong robustness to the absence of one of its observation modalities (images or simulation attributes). We conclude that the combination of GW with World Models holds great potential for improving decision-making in RL agents.
Enhancing deep neural networks through complex-valued representations and Kuramoto synchronization dynamics
Feb 28, 2025Neural synchrony is hypothesized to play a crucial role in how the brain organizes visual scenes into structured representations, enabling the robust encoding of multiple objects within a scene. However, current deep learning models often struggle with object binding, limiting their ability to represent multiple objects effectively. Inspired by neuroscience, we investigate whether synchrony-based mechanisms can enhance object encoding in artificial models trained for visual categorization. Specifically, we combine complex-valued representations with Kuramoto dynamics to promote phase alignment, facilitating the grouping of features belonging to the same object. We evaluate two architectures employing synchrony: a feedforward model and a recurrent model with feedback connections to refine phase synchronization using top-down information. Both models outperform their real-valued counterparts and complex-valued models without Kuramoto synchronization on tasks involving multi-object images, such as overlapping handwritten digits, noisy inputs, and out-of-distribution transformations. Our findings highlight the potential of synchrony-driven mechanisms to enhance deep learning models, improving their performance, robustness, and generalization in complex visual categorization tasks.
Tracking objects that change in appearance with phase synchrony
Oct 02, 2024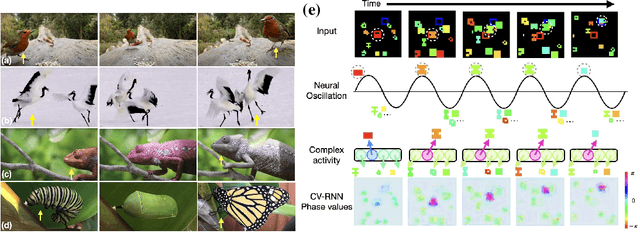
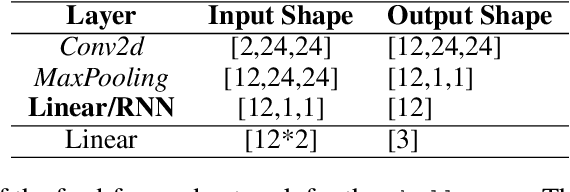
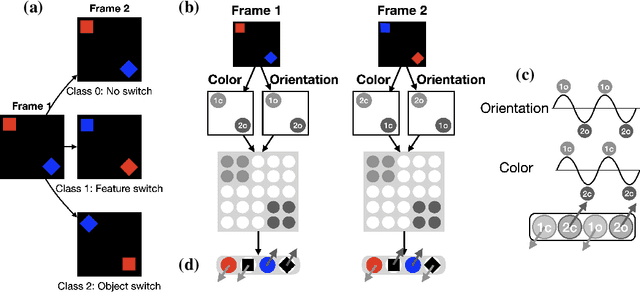
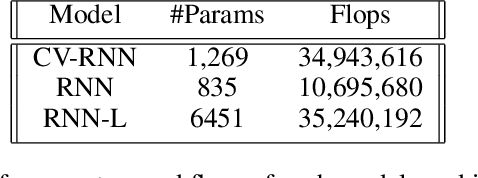
Objects we encounter often change appearance as we interact with them. Changes in illumination (shadows), object pose, or movement of nonrigid objects can drastically alter available image features. How do biological visual systems track objects as they change? It may involve specific attentional mechanisms for reasoning about the locations of objects independently of their appearances -- a capability that prominent neuroscientific theories have associated with computing through neural synchrony. We computationally test the hypothesis that the implementation of visual attention through neural synchrony underlies the ability of biological visual systems to track objects that change in appearance over time. We first introduce a novel deep learning circuit that can learn to precisely control attention to features separately from their location in the world through neural synchrony: the complex-valued recurrent neural network (CV-RNN). Next, we compare object tracking in humans, the CV-RNN, and other deep neural networks (DNNs), using FeatureTracker: a large-scale challenge that asks observers to track objects as their locations and appearances change in precisely controlled ways. While humans effortlessly solved FeatureTracker, state-of-the-art DNNs did not. In contrast, our CV-RNN behaved similarly to humans on the challenge, providing a computational proof-of-concept for the role of phase synchronization as a neural substrate for tracking appearance-morphing objects as they move about.
Latent Representation Matters: Human-like Sketches in One-shot Drawing Tasks
Jun 10, 2024Humans can effortlessly draw new categories from a single exemplar, a feat that has long posed a challenge for generative models. However, this gap has started to close with recent advances in diffusion models. This one-shot drawing task requires powerful inductive biases that have not been systematically investigated. Here, we study how different inductive biases shape the latent space of Latent Diffusion Models (LDMs). Along with standard LDM regularizers (KL and vector quantization), we explore supervised regularizations (including classification and prototype-based representation) and contrastive inductive biases (using SimCLR and redundancy reduction objectives). We demonstrate that LDMs with redundancy reduction and prototype-based regularizations produce near-human-like drawings (regarding both samples' recognizability and originality) -- better mimicking human perception (as evaluated psychophysically). Overall, our results suggest that the gap between humans and machines in one-shot drawings is almost closed.
Modality-Agnostic fMRI Decoding of Vision and Language
Mar 18, 2024



Previous studies have shown that it is possible to map brain activation data of subjects viewing images onto the feature representation space of not only vision models (modality-specific decoding) but also language models (cross-modal decoding). In this work, we introduce and use a new large-scale fMRI dataset (~8,500 trials per subject) of people watching both images and text descriptions of such images. This novel dataset enables the development of modality-agnostic decoders: a single decoder that can predict which stimulus a subject is seeing, irrespective of the modality (image or text) in which the stimulus is presented. We train and evaluate such decoders to map brain signals onto stimulus representations from a large range of publicly available vision, language and multimodal (vision+language) models. Our findings reveal that (1) modality-agnostic decoders perform as well as (and sometimes even better than) modality-specific decoders (2) modality-agnostic decoders mapping brain data onto representations from unimodal models perform as well as decoders relying on multimodal representations (3) while language and low-level visual (occipital) brain regions are best at decoding text and image stimuli, respectively, high-level visual (temporal) regions perform well on both stimulus types.
Zero-shot cross-modal transfer of Reinforcement Learning policies through a Global Workspace
Mar 07, 2024



Humans perceive the world through multiple senses, enabling them to create a comprehensive representation of their surroundings and to generalize information across domains. For instance, when a textual description of a scene is given, humans can mentally visualize it. In fields like robotics and Reinforcement Learning (RL), agents can also access information about the environment through multiple sensors; yet redundancy and complementarity between sensors is difficult to exploit as a source of robustness (e.g. against sensor failure) or generalization (e.g. transfer across domains). Prior research demonstrated that a robust and flexible multimodal representation can be efficiently constructed based on the cognitive science notion of a 'Global Workspace': a unique representation trained to combine information across modalities, and to broadcast its signal back to each modality. Here, we explore whether such a brain-inspired multimodal representation could be advantageous for RL agents. First, we train a 'Global Workspace' to exploit information collected about the environment via two input modalities (a visual input, or an attribute vector representing the state of the agent and/or its environment). Then, we train a RL agent policy using this frozen Global Workspace. In two distinct environments and tasks, our results reveal the model's ability to perform zero-shot cross-modal transfer between input modalities, i.e. to apply to image inputs a policy previously trained on attribute vectors (and vice-versa), without additional training or fine-tuning. Variants and ablations of the full Global Workspace (including a CLIP-like multimodal representation trained via contrastive learning) did not display the same generalization abilities.
Leveraging Self-Supervised Instance Contrastive Learning for Radar Object Detection
Feb 13, 2024



In recent years, driven by the need for safer and more autonomous transport systems, the automotive industry has shifted toward integrating a growing number of Advanced Driver Assistance Systems (ADAS). Among the array of sensors employed for object recognition tasks, radar sensors have emerged as a formidable contender due to their abilities in adverse weather conditions or low-light scenarios and their robustness in maintaining consistent performance across diverse environments. However, the small size of radar datasets and the complexity of the labelling of those data limit the performance of radar object detectors. Driven by the promising results of self-supervised learning in computer vision, this paper presents RiCL, an instance contrastive learning framework to pre-train radar object detectors. We propose to exploit the detection from the radar and the temporal information to pre-train the radar object detection model in a self-supervised way using contrastive learning. We aim to pre-train an object detector's backbone, head and neck to learn with fewer data. Experiments on the CARRADA and the RADDet datasets show the effectiveness of our approach in learning generic representations of objects in range-Doppler maps. Notably, our pre-training strategy allows us to use only 20% of the labelled data to reach a similar mAP@0.5 than a supervised approach using the whole training set.
Consciousness in Artificial Intelligence: Insights from the Science of Consciousness
Aug 22, 2023
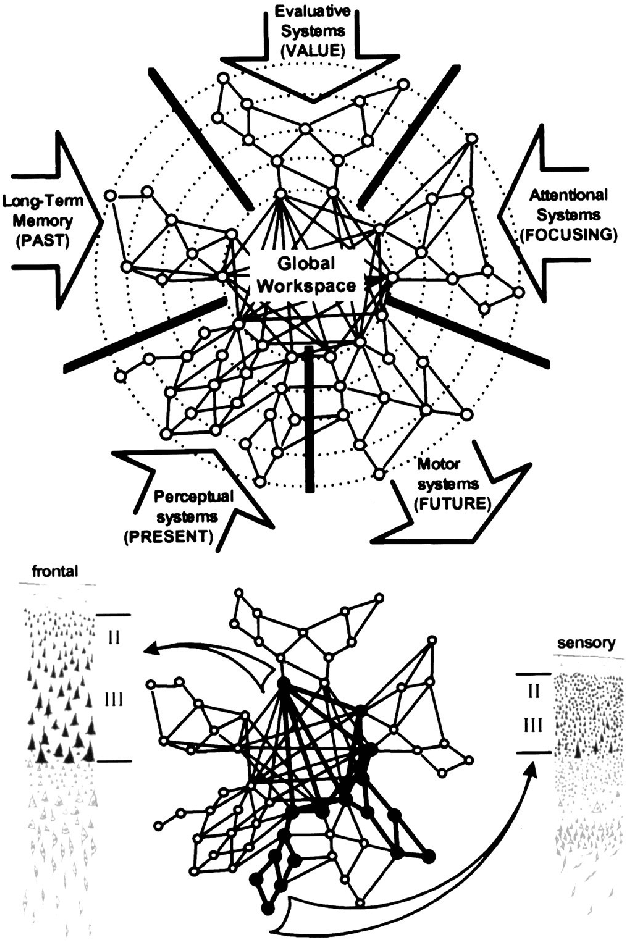

Whether current or near-term AI systems could be conscious is a topic of scientific interest and increasing public concern. This report argues for, and exemplifies, a rigorous and empirically grounded approach to AI consciousness: assessing existing AI systems in detail, in light of our best-supported neuroscientific theories of consciousness. We survey several prominent scientific theories of consciousness, including recurrent processing theory, global workspace theory, higher-order theories, predictive processing, and attention schema theory. From these theories we derive "indicator properties" of consciousness, elucidated in computational terms that allow us to assess AI systems for these properties. We use these indicator properties to assess several recent AI systems, and we discuss how future systems might implement them. Our analysis suggests that no current AI systems are conscious, but also suggests that there are no obvious technical barriers to building AI systems which satisfy these indicators.