 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking objects that change in appearance with phase synchrony
Oct 02, 2024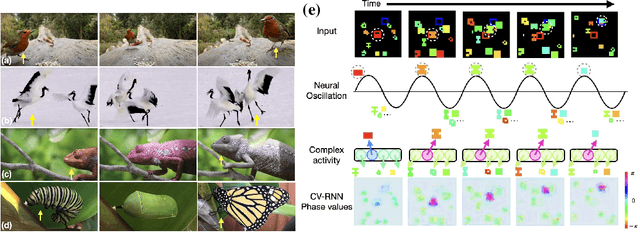
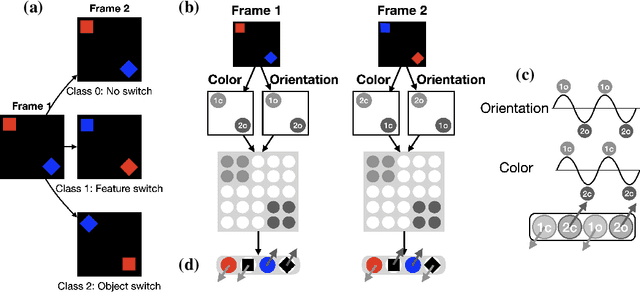
Objects we encounter often change appearance as we interact with them. Changes in illumination (shadows), object pose, or movement of nonrigid objects can drastically alter available image features. How do biological visual systems track objects as they change? It may involve specific attentional mechanisms for reasoning about the locations of objects independently of their appearances -- a capability that prominent neuroscientific theories have associated with computing through neural synchrony. We computationally test the hypothesis that the implementation of visual attention through neural synchrony underlies the ability of biological visual systems to track objects that change in appearance over time. We first introduce a novel deep learning circuit that can learn to precisely control attention to features separately from their location in the world through neural synchrony: the complex-valued recurrent neural network (CV-RNN). Next, we compare object tracking in humans, the CV-RNN, and other deep neural networks (DNNs), using FeatureTracker: a large-scale challenge that asks observers to track objects as their locations and appearances change in precisely controlled ways. While humans effortlessly solved FeatureTracker, state-of-the-art DNNs did not. In contrast, our CV-RNN behaved similarly to humans on the challenge, providing a computational proof-of-concept for the role of phase synchronization as a neural substrate for tracking appearance-morphing objects as they move about.
The Challenge of Appearance-Free Object Tracking with Feedforward Neural Networks
Sep 30, 2021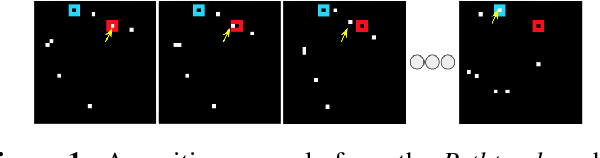
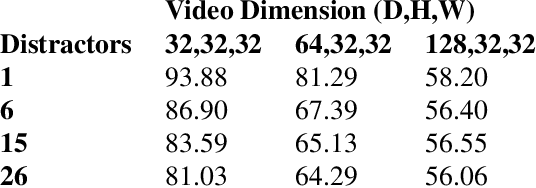
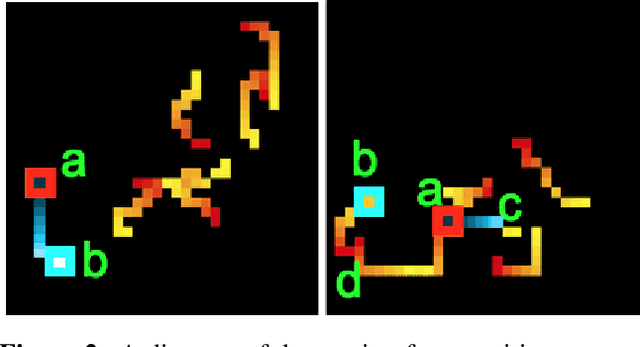

Nearly all models for object tracking with artificial neural networks depend on appearance features extracted from a "backbone" architecture, designed for object recognition. Indeed, significant progress on object tracking has been spurred by introducing backbones that are better able to discriminate objects by their appearance. However, extensive neurophysiology and psychophysics evidence suggests that biological visual systems track objects using both appearance and motion features. Here, we introduce $\textit{PathTracker}$, a visual challenge inspired by cognitive psychology, which tests the ability of observers to learn to track objects solely by their motion. We find that standard 3D-convolutional deep network models struggle to solve this task when clutter is introduced into the generated scenes, or when objects travel long distances. This challenge reveals that tracing the path of object motion is a blind spot of feedforward neural networks. We expect that strategies for appearance-free object tracking from biological vision can inspire solutions these failures of deep neural networks.
Tracking Without Re-recognition in Humans and Machines
Jun 03, 2021



Imagine trying to track one particular fruitfly in a swarm of hundreds. Higher biological visual systems have evolved to track moving objects by relying on both appearance and motion features. We investigate if state-of-the-art deep neural networks for visual tracking are capable of the same. For this, we introduce PathTracker, a synthetic visual challenge that asks human observers and machines to track a target object in the midst of identical-looking "distractor" objects. While humans effortlessly learn PathTracker and generalize to systematic variations in task design, state-of-the-art deep networks struggle. To address this limitation, we identify and model circuit mechanisms in biological brains that are implicated in tracking objects based on motion cues. When instantiated as a recurrent network, our circuit model learns to solve PathTracker with a robust visual strategy that rivals human performance and explains a significant proportion of their decision-making on the challenge. We also show that the success of this circuit model extends to object tracking in natural videos. Adding it to a transformer-based architecture for object tracking builds tolerance to visual nuisances that affect object appearance, resulting in a new state-of-the-art performance on the large-scale TrackingNet object tracking challenge. Our work highlights the importance of building artificial vision models that can help us better understand human vision and improve computer vision.