 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainability Via Causal Self-Talk
Nov 17, 2022Explaining the behavior of AI systems is an important problem that, in practice, is generally avoided. While the XAI community has been developing an abundance of techniques, most incur a set of costs that the wider deep learning community has been unwilling to pay in most situations. We take a pragmatic view of the issue, and define a set of desiderata that capture both the ambitions of XAI and the practical constraints of deep learning. We describe an effective way to satisfy all the desiderata: train the AI system to build a causal model of itself. We develop an instance of this solution for Deep RL agents: Causal Self-Talk. CST operates by training the agent to communicate with itself across time. We implement this method in a simulated 3D environment, and show how it enables agents to generate faithful and semantically-meaningful explanations of their own behavior. Beyond explanations, we also demonstrate that these learned models provide new ways of building semantic control interfaces to AI systems.
Transformers generalize differently from information stored in context vs in weights
Oct 11, 2022
Transformer models can use two fundamentally different kinds of information: information stored in weights during training, and information provided ``in-context'' at inference time. In this work, we show that transformers exhibit different inductive biases in how they represent and generalize from the information in these two sources. In particular, we characterize whether they generalize via parsimonious rules (rule-based generalization) or via direct comparison with observed examples (exemplar-based generalization). This is of important practical consequence, as it informs whether to encode information in weights or in context, depending on how we want models to use that information. In transformers trained on controlled stimuli, we find that generalization from weights is more rule-based whereas generalization from context is largely exemplar-based. In contrast, we find that in transformers pre-trained on natural language, in-context learning is significantly rule-based, with larger models showing more rule-basedness. We hypothesise that rule-based generalization from in-context information might be an emergent consequence of large-scale training on language, which has sparse rule-like structure. Using controlled stimuli, we verify that transformers pretrained on data containing sparse rule-like structure exhibit more rule-based generalization.
Tracking Without Re-recognition in Humans and Machines
Jun 03, 2021



Imagine trying to track one particular fruitfly in a swarm of hundreds. Higher biological visual systems have evolved to track moving objects by relying on both appearance and motion features. We investigate if state-of-the-art deep neural networks for visual tracking are capable of the same. For this, we introduce PathTracker, a synthetic visual challenge that asks human observers and machines to track a target object in the midst of identical-looking "distractor" objects. While humans effortlessly learn PathTracker and generalize to systematic variations in task design, state-of-the-art deep networks struggle. To address this limitation, we identify and model circuit mechanisms in biological brains that are implicated in tracking objects based on motion cues. When instantiated as a recurrent network, our circuit model learns to solve PathTracker with a robust visual strategy that rivals human performance and explains a significant proportion of their decision-making on the challenge. We also show that the success of this circuit model extends to object tracking in natural videos. Adding it to a transformer-based architecture for object tracking builds tolerance to visual nuisances that affect object appearance, resulting in a new state-of-the-art performance on the large-scale TrackingNet object tracking challenge. Our work highlights the importance of building artificial vision models that can help us better understand human vision and improve computer vision.
Recurrent neural circuits for contour detection
Oct 29, 2020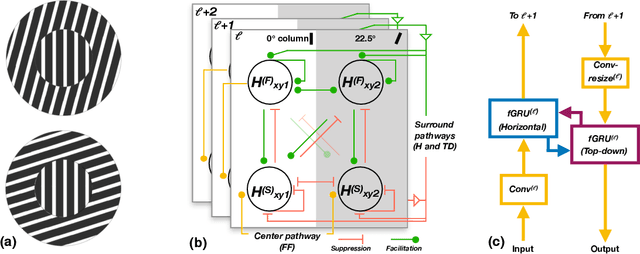
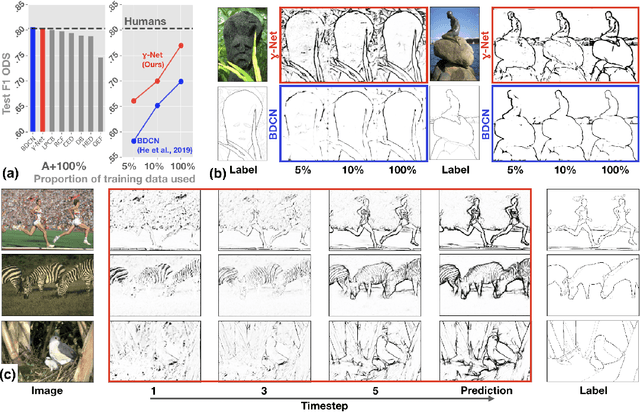
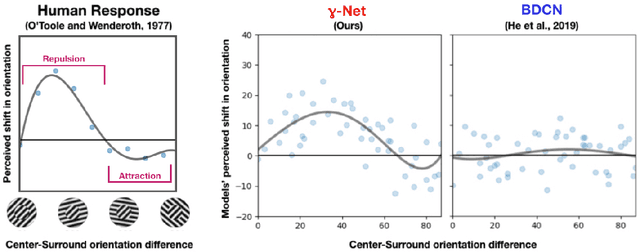
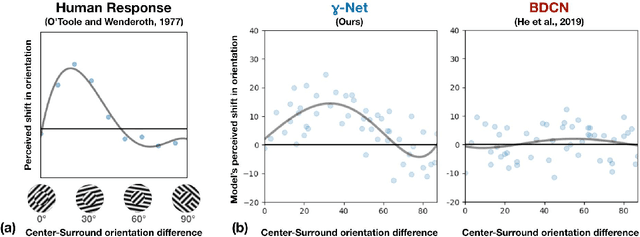
We introduce a deep recurrent neural network architecture that approximates visual cortical circuits. We show that this architecture, which we refer to as the gamma-net, learns to solve contour detection tasks with better sample efficiency than state-of-the-art feedforward networks, while also exhibiting a classic perceptual illusion, known as the orientation-tilt illusion. Correcting this illusion significantly reduces gamma-net contour detection accuracy by driving it to prefer low-level edges over high-level object boundary contours. Overall, our study suggests that the orientation-tilt illusion is a byproduct of neural circuits that help biological visual systems achieve robust and efficient contour detection, and that incorporating these circuits in artificial neural networks can improve computer vision.
Disentangling neural mechanisms for perceptual grouping
Jun 04, 2019

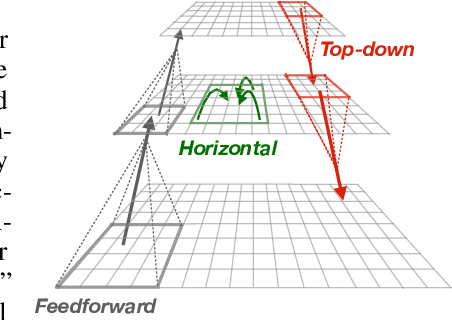
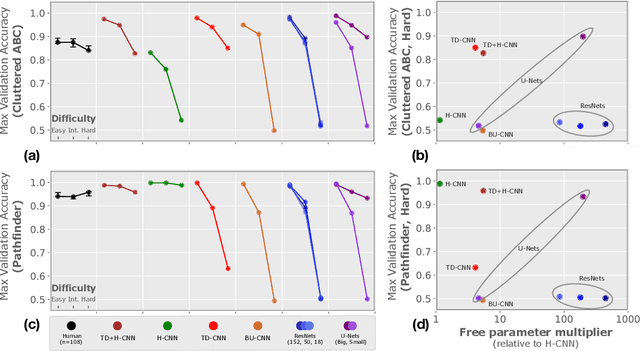
Forming perceptual groups and individuating objects in visual scenes is an essential step towards visual intelligence. This ability is thought to arise in the brain from computations implemented by bottom-up, horizontal, and top-down connections between neurons. However, the relative contributions of these connections to perceptual grouping are poorly understood. We address this question by systematically evaluating neural network architectures featuring combinations of these connections on two synthetic visual tasks, which stress low-level `gestalt' vs. high-level object cues for perceptual grouping. We show that increasing the difficulty of either task strains learning for networks that rely solely on bottom-up processing. Horizontal connections resolve this limitation on tasks with gestalt cues by supporting incremental spatial propagation of activities, whereas top-down connections rescue learning on tasks featuring object cues by propagating coarse predictions about the position of the target object. Our findings disassociate the computational roles of bottom-up, horizontal and top-down connectivity, and demonstrate how a model featuring all of these interactions can more flexibly learn to form perceptual groups.
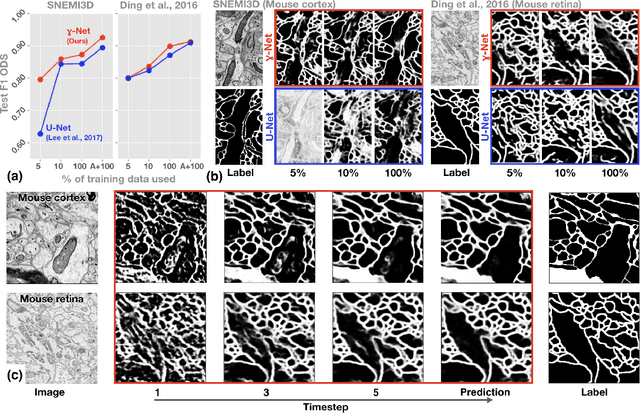
Robust neural circuit reconstruction from serial electron microscopy with convolutional recurrent networks
Nov 28, 2018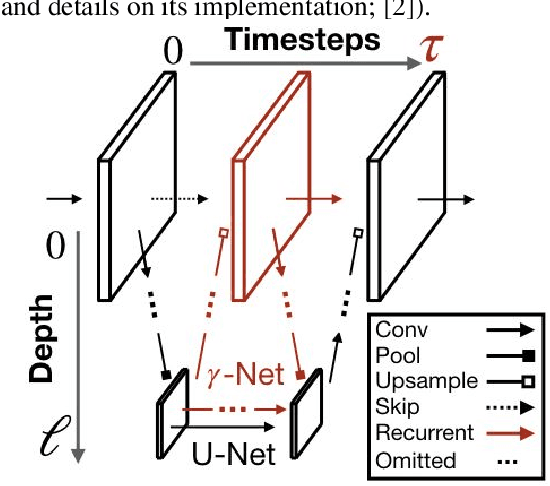
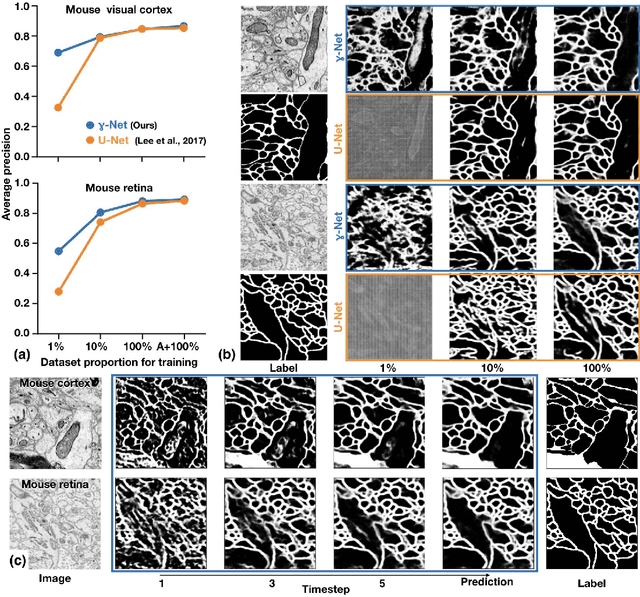

Recent successes in deep learning have started to impact neuroscience. Of particular significance are claims that current segmentation algorithms achieve "super-human" accuracy in an area known as connectomics. However, as we will show, these algorithms do not effectively generalize beyond the particular source and brain tissues used for training -- severely limiting their usability by the broader neuroscience community. To fill this gap, we describe a novel connectomics challenge for source- and tissue-agnostic reconstruction of neurons (STAR), which favors broad generalization over fitting specific datasets. We first demonstrate that current state-of-the-art approaches to neuron segmentation perform poorly on the challenge. We further describe a novel convolutional recurrent neural network module that combines short-range horizontal connections within a processing stage and long-range top-down connections between stages. The resulting architecture establishes the state of the art on the STAR challenge and represents a significant step towards widely usable and fully-automated connectomics analysis.
Learning long-range spatial dependencies with horizontal gated-recurrent units
Jun 22, 2018
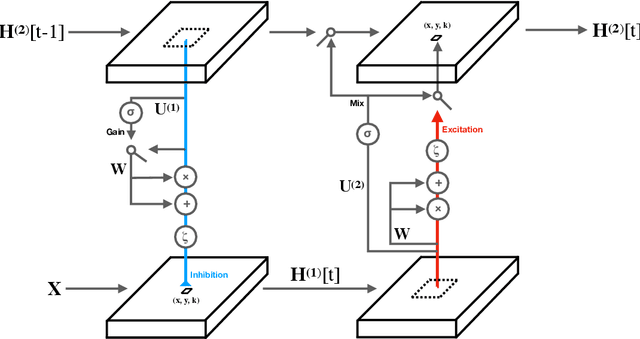
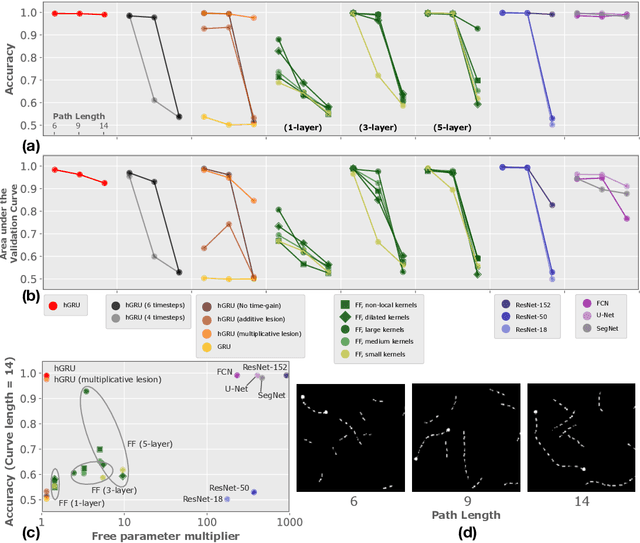
Progress in deep learning has spawned great successes in many engineering applications. As a prime example, convolutional neural networks, a type of feedforward neural networks, are now approaching -- and sometimes even surpassing -- human accuracy on a variety of visual recognition tasks. Here, however, we show that these neural networks and their recent extensions struggle in recognition tasks where co-dependent visual features must be detected over long spatial ranges. We introduce the horizontal gated-recurrent unit (hGRU) to learn intrinsic horizontal connections -- both within and across feature columns. We demonstrate that a single hGRU layer matches or outperforms all tested feedforward hierarchical baselines including state-of-the-art architectures which have orders of magnitude more free parameters. We further discuss the biological plausibility of the hGRU in comparison to anatomical data from the visual cortex as well as human behavioral data on a classic contour detection task.
Same-different problems strain convolutional neural networks
May 25, 2018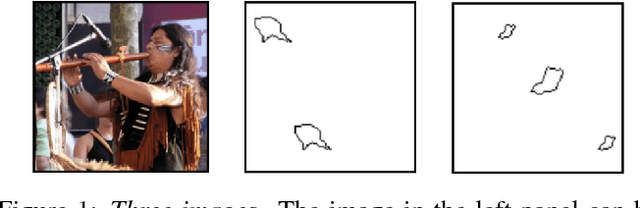
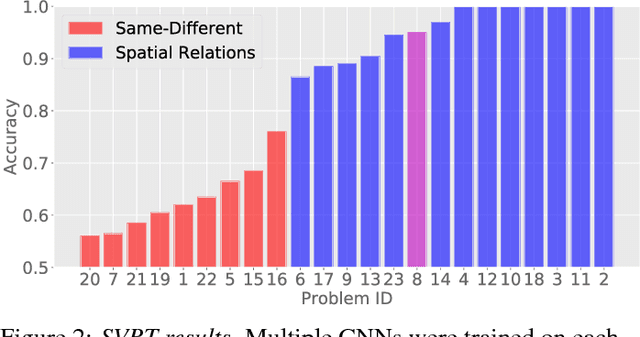
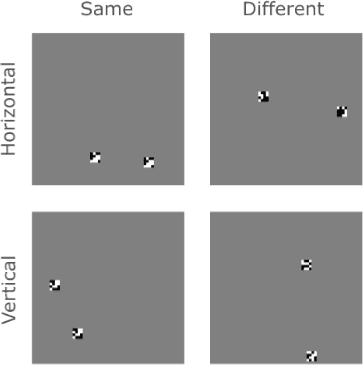
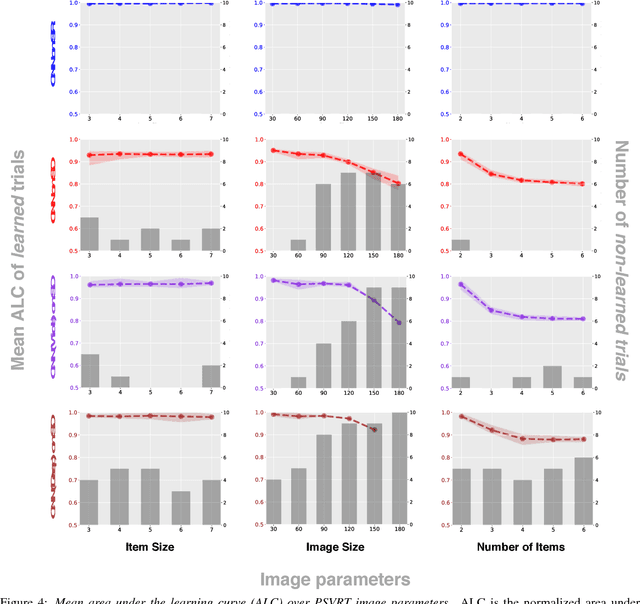
The robust and efficient recognition of visual relations in images is a hallmark of biological vision. We argue that, despite recent progress in visual recognition, modern machine vision algorithms are severely limited in their ability to learn visual relations. Through controlled experiments, we demonstrate that visual-relation problems strain convolutional neural networks (CNNs). The networks eventually break altogether when rote memorization becomes impossible, as when intra-class variability exceeds network capacity. Motivated by the comparable success of biological vision, we argue that feedback mechanisms including attention and perceptual grouping may be the key computational components underlying abstract visual reasoning.\