 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRDA: Reward Design Agent for Reinforcement Learning
Jun 01, 2026Reinforcement learning has enabled the acquisition of impressive robotic skills, but typically requires hand-crafted reward functions that are slow to design and difficult to align with human intentions. Recent work, such as Eureka, automates reward design by using an LLM to iteratively generate and refine reward code from task descriptions. However, they rely on coarse feedback signals such as success rate, which provide little semantic insight into the learned behavior. As a result, their trained policies achieve the final goal but are frequently poorly aligned with task instructions. We introduce the Reward Design Agent (RDA), a VLM-based agentic framework that injects semantic understanding into reward design. RDA decomposes tasks, visually evaluates trajectories, summarizes failure modes, and iteratively revises reward code to better align with task instructions. Across 12 tabletop manipulation tasks from ManiSkill and 4 whole-body manipulation tasks from HumanoidBench, RDA produces policies substantially more instruction-aligned than those of other baselines, while achieving comparable task success rates. Videos and the generated reward code are available on https://nitinkamra1992.github.io/reward-design-agent.
Benchmarking Egocentric Multimodal Goal Inference for Assistive Wearable Agents
Oct 25, 2025There has been a surge of interest in assistive wearable agents: agents embodied in wearable form factors (e.g., smart glasses) who take assistive actions toward a user's goal/query (e.g. "Where did I leave my keys?"). In this work, we consider the important complementary problem of inferring that goal from multi-modal contextual observations. Solving this "goal inference" problem holds the promise of eliminating the effort needed to interact with such an agent. This work focuses on creating WAGIBench, a strong benchmark to measure progress in solving this problem using vision-language models (VLMs). Given the limited prior work in this area, we collected a novel dataset comprising 29 hours of multimodal data from 348 participants across 3,477 recordings, featuring ground-truth goals alongside accompanying visual, audio, digital, and longitudinal contextual observations. We validate that human performance exceeds model performance, achieving 93% multiple-choice accuracy compared with 84% for the best-performing VLM. Generative benchmark results that evaluate several families of modern vision-language models show that larger models perform significantly better on the task, yet remain far from practical usefulness, as they produce relevant goals only 55% of the time. Through a modality ablation, we show that models benefit from extra information in relevant modalities with minimal performance degradation from irrelevant modalities.
EgoToM: Benchmarking Theory of Mind Reasoning from Egocentric Videos
Mar 28, 2025

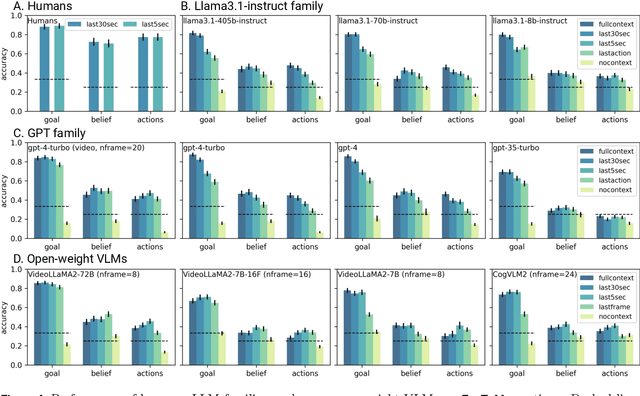

We introduce EgoToM, a new video question-answering benchmark that extends Theory-of-Mind (ToM) evaluation to egocentric domains. Using a causal ToM model, we generate multi-choice video QA instances for the Ego4D dataset to benchmark the ability to predict a camera wearer's goals, beliefs, and next actions. We study the performance of both humans and state of the art multimodal large language models (MLLMs) on these three interconnected inference problems. Our evaluation shows that MLLMs achieve close to human-level accuracy on inferring goals from egocentric videos. However, MLLMs (including the largest ones we tested with over 100B parameters) fall short of human performance when inferring the camera wearers' in-the-moment belief states and future actions that are most consistent with the unseen video future. We believe that our results will shape the future design of an important class of egocentric digital assistants which are equipped with a reasonable model of the user's internal mental states.
Adaptive recurrent vision performs zero-shot computation scaling to unseen difficulty levels
Nov 12, 2023



Humans solving algorithmic (or) reasoning problems typically exhibit solution times that grow as a function of problem difficulty. Adaptive recurrent neural networks have been shown to exhibit this property for various language-processing tasks. However, little work has been performed to assess whether such adaptive computation can also enable vision models to extrapolate solutions beyond their training distribution's difficulty level, with prior work focusing on very simple tasks. In this study, we investigate a critical functional role of such adaptive processing using recurrent neural networks: to dynamically scale computational resources conditional on input requirements that allow for zero-shot generalization to novel difficulty levels not seen during training using two challenging visual reasoning tasks: PathFinder and Mazes. We combine convolutional recurrent neural networks (ConvRNNs) with a learnable halting mechanism based on Graves (2016). We explore various implementations of such adaptive ConvRNNs (AdRNNs) ranging from tying weights across layers to more sophisticated biologically inspired recurrent networks that possess lateral connections and gating. We show that 1) AdRNNs learn to dynamically halt processing early (or late) to solve easier (or harder) problems, 2) these RNNs zero-shot generalize to more difficult problem settings not shown during training by dynamically increasing the number of recurrent iterations at test time. Our study provides modeling evidence supporting the hypothesis that recurrent processing enables the functional advantage of adaptively allocating compute resources conditional on input requirements and hence allowing generalization to harder difficulty levels of a visual reasoning problem without training.
Learning compact generalizable neural representations supporting perceptual grouping
Jun 21, 2020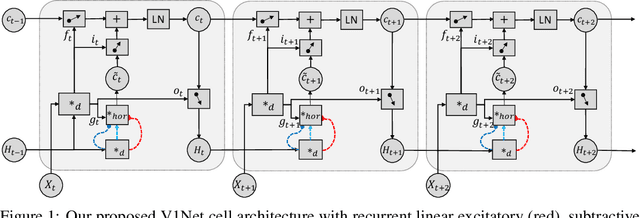
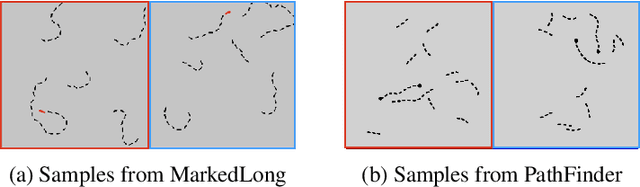
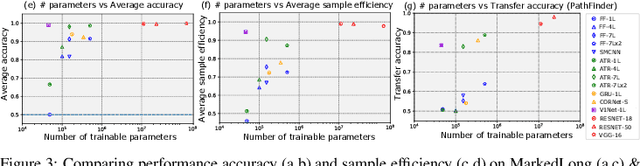

Work at the intersection of vision science and deep learning is starting to explore the efficacy of deep convolutional networks (DCNs) and recurrent networks in solving perceptual grouping problems that underlie primate visual recognition and segmentation. Here, we extend this line of work to investigate the compactness and generalizability of DCN solutions to learning low-level perceptual grouping routines involving contour integration. We introduce V1Net, a bio-inspired recurrent unit that incorporates lateral connections ubiquitous in cortical circuitry. Feedforward convolutional layers in DCNs can be substituted with V1Net modules to enhance their contextual visual processing support for perceptual grouping. We compare the learning efficiency and accuracy of V1Net-DCNs to that of 14 carefully selected feedforward and recurrent neural architectures (including state-of-the-art DCNs) on MarkedLong -- a synthetic forced-choice contour integration dataset of 800,000 images we introduce here -- and the previously published Pathfinder contour integration benchmarks. We gauged solution generalizability by measuring the transfer learning performance of our candidate models trained on MarkedLong that were fine-tuned to learn PathFinder. Our results demonstrate that a compact 3-layer V1Net-DCN matches or outperforms the test accuracy and sample efficiency of all tested comparison models which contain between 5x and 1000x more trainable parameters; we also note that V1Net-DCN learns the most compact generalizable solution to MarkedLong. A visualization of the temporal dynamics of a V1Net-DCN elucidates its usage of interpretable grouping computations to solve MarkedLong. The compact and rich representations of V1Net-DCN also make it a promising candidate to build on-device machine vision algorithms as well as help better understand biological cortical circuitry.
Adversarial Distortion for Learned Video Compression
Apr 22, 2020

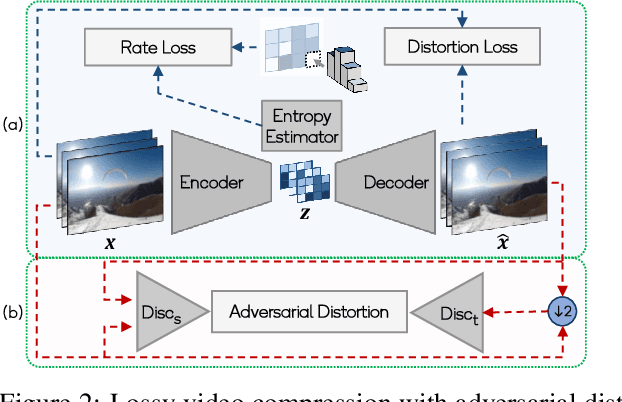
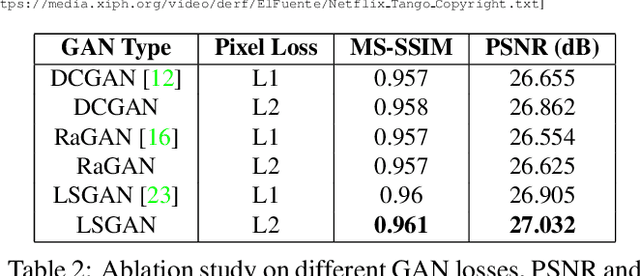
In this paper, we present a novel adversarial lossy video compression model. At extremely low bit-rates, standard video coding schemes suffer from unpleasant reconstruction artifacts such as blocking, ringing etc. Existing learned neural approaches to video compression have achieved reasonable success on reducing the bit-rate for efficient transmission and reduce the impact of artifacts to an extent. However, they still tend to produce blurred results under extreme compression. In this paper, we present a deep adversarial learned video compression model that minimizes an auxiliary adversarial distortion objective. We find this adversarial objective to correlate better with human perceptual quality judgement relative to traditional quality metrics such as MS-SSIM and PSNR. Our experiments using a state-of-the-art learned video compression system demonstrate a reduction of perceptual artifacts and reconstruction of detail lost especially under extremely high compression.
Learning long-range spatial dependencies with horizontal gated-recurrent units
Jun 22, 2018
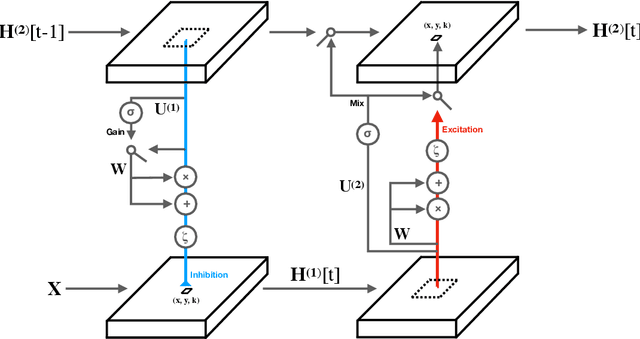
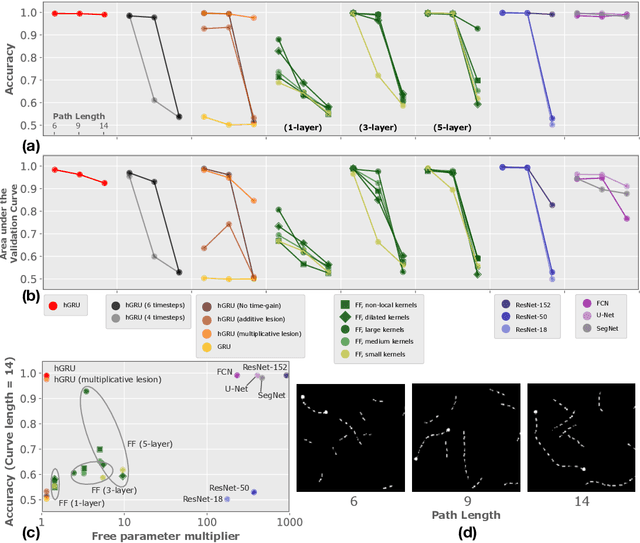
Progress in deep learning has spawned great successes in many engineering applications. As a prime example, convolutional neural networks, a type of feedforward neural networks, are now approaching -- and sometimes even surpassing -- human accuracy on a variety of visual recognition tasks. Here, however, we show that these neural networks and their recent extensions struggle in recognition tasks where co-dependent visual features must be detected over long spatial ranges. We introduce the horizontal gated-recurrent unit (hGRU) to learn intrinsic horizontal connections -- both within and across feature columns. We demonstrate that a single hGRU layer matches or outperforms all tested feedforward hierarchical baselines including state-of-the-art architectures which have orders of magnitude more free parameters. We further discuss the biological plausibility of the hGRU in comparison to anatomical data from the visual cortex as well as human behavioral data on a classic contour detection task.