 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Frame Calibration with Siamese Network in Facial Action Unit Recognition
Aug 30, 2024
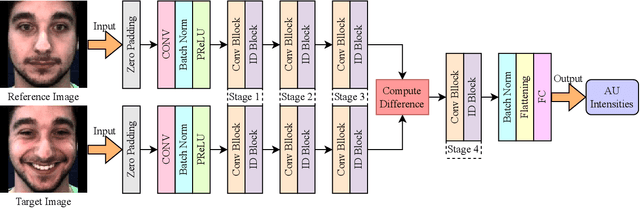
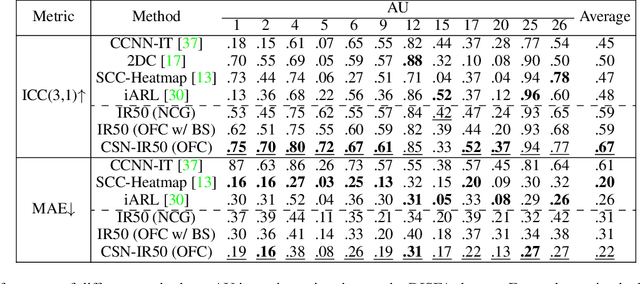
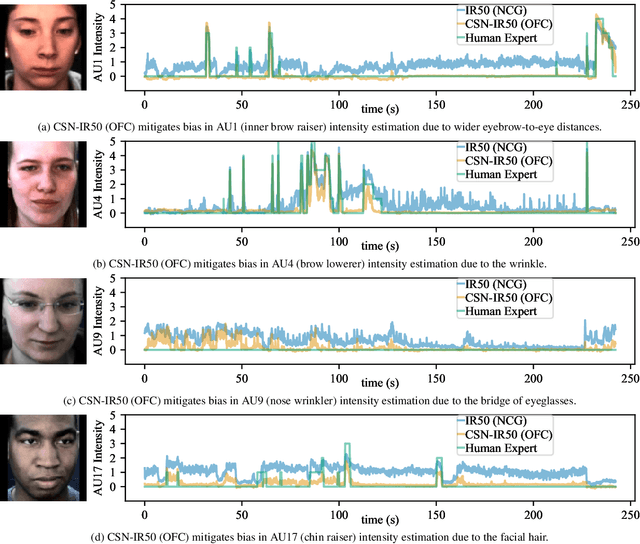
Automatic facial action unit (AU) recognition is used widely in facial expression analysis. Most existing AU recognition systems aim for cross-participant non-calibrated generalization (NCG) to unseen faces without further calibration. However, due to the diversity of facial attributes across different identities, accurately inferring AU activation from single images of an unseen face is sometimes infeasible, even for human experts -- it is crucial to first understand how the face appears in its neutral expression, or significant bias may be incurred. Therefore, we propose to perform one-frame calibration (OFC) in AU recognition: for each face, a single image of its neutral expression is used as the reference image for calibration. With this strategy, we develop a Calibrating Siamese Network (CSN) for AU recognition and demonstrate its remarkable effectiveness with a simple iResNet-50 (IR50) backbone. On the DISFA, DISFA+, and UNBC-McMaster datasets, we show that our OFC CSN-IR50 model (a) substantially improves the performance of IR50 by mitigating facial attribute biases (including biases due to wrinkles, eyebrow positions, facial hair, etc.), (b) substantially outperforms the naive OFC method of baseline subtraction as well as (c) a fine-tuned version of this naive OFC method, and (d) also outperforms state-of-the-art NCG models for both AU intensity estimation and AU detection.
FERGI: Automatic Annotation of User Preferences for Text-to-Image Generation from Spontaneous Facial Expression Reaction
Dec 05, 2023Researchers have proposed to use data of human preference feedback to fine-tune text-to-image generative models. However, the scalability of human feedback collection has been limited by its reliance on manual annotation. Therefore, we develop and test a method to automatically annotate user preferences from their spontaneous facial expression reaction to the generated images. We collect a dataset of Facial Expression Reaction to Generated Images (FERGI) and show that the activations of multiple facial action units (AUs) are highly correlated with user evaluations of the generated images. Specifically, AU4 (brow lowerer) is most consistently reflective of negative evaluations of the generated image. This can be useful in two ways. Firstly, we can automatically annotate user preferences between image pairs with substantial difference in AU4 responses to them with an accuracy significantly outperforming state-of-the-art scoring models. Secondly, directly integrating the AU4 responses with the scoring models improves their consistency with human preferences. Additionally, the AU4 response best reflects the user's evaluation of the image fidelity, making it complementary to the state-of-the-art scoring models, which are generally better at reflecting image-text alignment. Finally, this method of automatic annotation with facial expression analysis can be potentially generalized to other generation tasks. The code is available at https://github.com/ShuangquanFeng/FERGI, and the dataset is also available at the same link for research purposes.
Adaptive recurrent vision performs zero-shot computation scaling to unseen difficulty levels
Nov 12, 2023



Humans solving algorithmic (or) reasoning problems typically exhibit solution times that grow as a function of problem difficulty. Adaptive recurrent neural networks have been shown to exhibit this property for various language-processing tasks. However, little work has been performed to assess whether such adaptive computation can also enable vision models to extrapolate solutions beyond their training distribution's difficulty level, with prior work focusing on very simple tasks. In this study, we investigate a critical functional role of such adaptive processing using recurrent neural networks: to dynamically scale computational resources conditional on input requirements that allow for zero-shot generalization to novel difficulty levels not seen during training using two challenging visual reasoning tasks: PathFinder and Mazes. We combine convolutional recurrent neural networks (ConvRNNs) with a learnable halting mechanism based on Graves (2016). We explore various implementations of such adaptive ConvRNNs (AdRNNs) ranging from tying weights across layers to more sophisticated biologically inspired recurrent networks that possess lateral connections and gating. We show that 1) AdRNNs learn to dynamically halt processing early (or late) to solve easier (or harder) problems, 2) these RNNs zero-shot generalize to more difficult problem settings not shown during training by dynamically increasing the number of recurrent iterations at test time. Our study provides modeling evidence supporting the hypothesis that recurrent processing enables the functional advantage of adaptively allocating compute resources conditional on input requirements and hence allowing generalization to harder difficulty levels of a visual reasoning problem without training.
Learning compact generalizable neural representations supporting perceptual grouping
Jun 21, 2020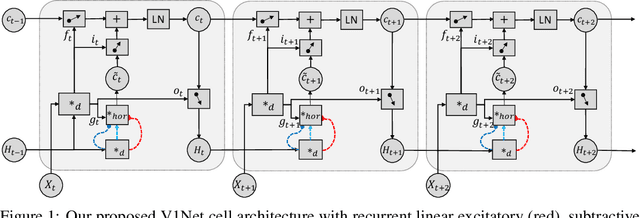
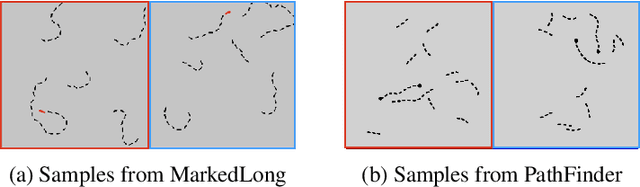
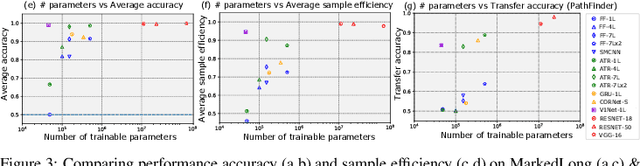

Work at the intersection of vision science and deep learning is starting to explore the efficacy of deep convolutional networks (DCNs) and recurrent networks in solving perceptual grouping problems that underlie primate visual recognition and segmentation. Here, we extend this line of work to investigate the compactness and generalizability of DCN solutions to learning low-level perceptual grouping routines involving contour integration. We introduce V1Net, a bio-inspired recurrent unit that incorporates lateral connections ubiquitous in cortical circuitry. Feedforward convolutional layers in DCNs can be substituted with V1Net modules to enhance their contextual visual processing support for perceptual grouping. We compare the learning efficiency and accuracy of V1Net-DCNs to that of 14 carefully selected feedforward and recurrent neural architectures (including state-of-the-art DCNs) on MarkedLong -- a synthetic forced-choice contour integration dataset of 800,000 images we introduce here -- and the previously published Pathfinder contour integration benchmarks. We gauged solution generalizability by measuring the transfer learning performance of our candidate models trained on MarkedLong that were fine-tuned to learn PathFinder. Our results demonstrate that a compact 3-layer V1Net-DCN matches or outperforms the test accuracy and sample efficiency of all tested comparison models which contain between 5x and 1000x more trainable parameters; we also note that V1Net-DCN learns the most compact generalizable solution to MarkedLong. A visualization of the temporal dynamics of a V1Net-DCN elucidates its usage of interpretable grouping computations to solve MarkedLong. The compact and rich representations of V1Net-DCN also make it a promising candidate to build on-device machine vision algorithms as well as help better understand biological cortical circuitry.
Deep Transfer Learning with Ridge Regression
Jun 11, 2020
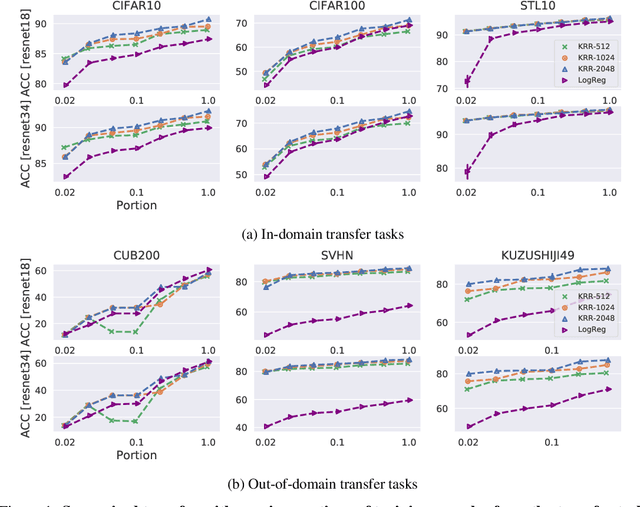


The large amount of online data and vast array of computing resources enable current researchers in both industry and academia to employ the power of deep learning with neural networks. While deep models trained with massive amounts of data demonstrate promising generalisation ability on unseen data from relevant domains, the computational cost of finetuning gradually becomes a bottleneck in transfering the learning to new domains. We address this issue by leveraging the low-rank property of learnt feature vectors produced from deep neural networks (DNNs) with the closed-form solution provided in kernel ridge regression (KRR). This frees transfer learning from finetuning and replaces it with an ensemble of linear systems with many fewer hyperparameters. Our method is successful on supervised and semi-supervised transfer learning tasks.
An Empirical Study on Post-processing Methods for Word Embeddings
May 28, 2019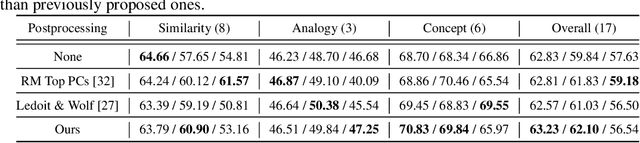

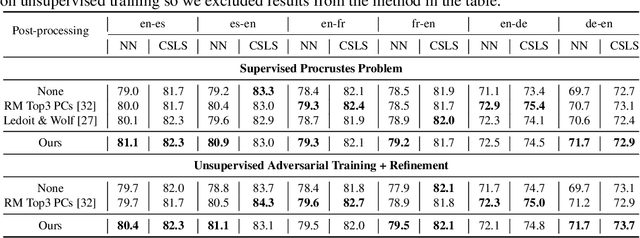
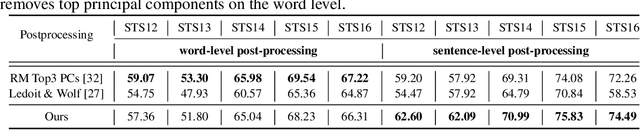
Word embeddings learnt from large corpora have been adopted in various applications in natural language processing and served as the general input representations to learning systems. Recently, a series of post-processing methods have been proposed to boost the performance of word embeddings on similarity comparison and analogy retrieval tasks, and some have been adapted to compose sentence representations. The general hypothesis behind these methods is that by enforcing the embedding space to be more isotropic, the similarity between words can be better expressed. We view these methods as an approach to shrink the covariance/gram matrix, which is estimated by learning word vectors, towards a scaled identity matrix. By optimising an objective in the semi-Riemannian manifold with Centralised Kernel Alignment (CKA), we are able to search for the optimal shrinkage parameter, and provide a post-processing method to smooth the spectrum of learnt word vectors which yields improved performance on downstream tasks.
Learning Distributed Representations of Symbolic Structure Using Binding and Unbinding Operations
Nov 03, 2018
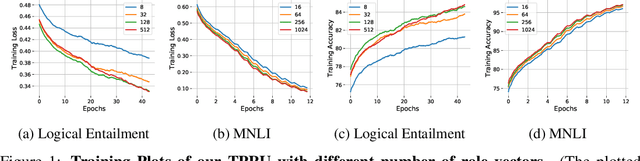
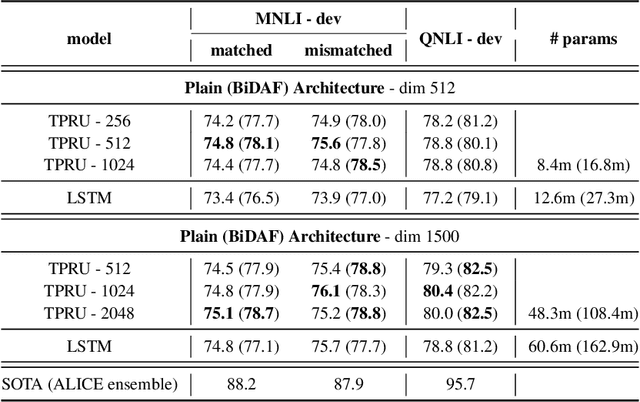
Widely used recurrent units, including Long-short Term Memory (LSTM) and Gated Recurrent Unit (GRU), perform well on natural language tasks, but their ability to learn structured representations is still questionable. Exploiting Tensor Product Representations (TPRs) --- distributed representations of symbolic structure in which vector-embedded symbols are bound to vector-embedded structural positions --- we propose the TPRU, a recurrent unit that, at each time step, explicitly executes structural-role binding and unbinding operations to incorporate structural information into learning. Experiments are conducted on both the Logical Entailment task and the Multi-genre Natural Language Inference (MNLI) task, and our TPR-derived recurrent unit provides strong performance with significantly fewer parameters than LSTM and GRU baselines. Furthermore, our learnt TPRU trained on MNLI demonstrates solid generalisation ability on downstream tasks.
Improving Sentence Representations with Multi-view Frameworks
Oct 02, 2018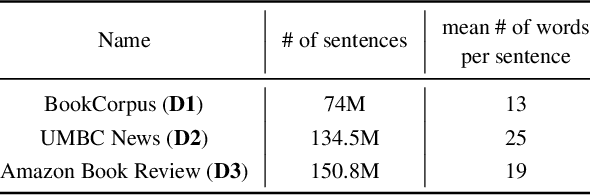
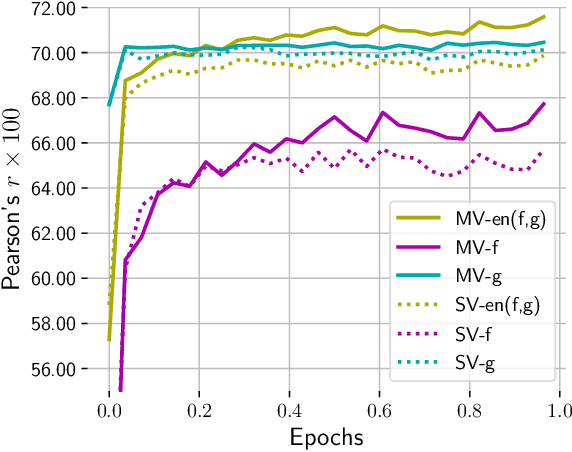
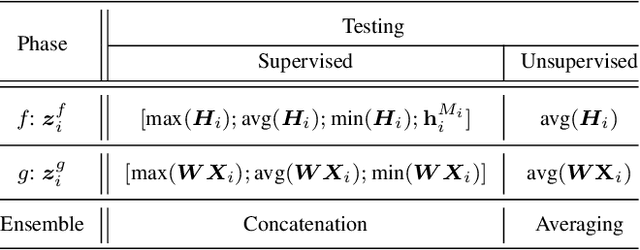
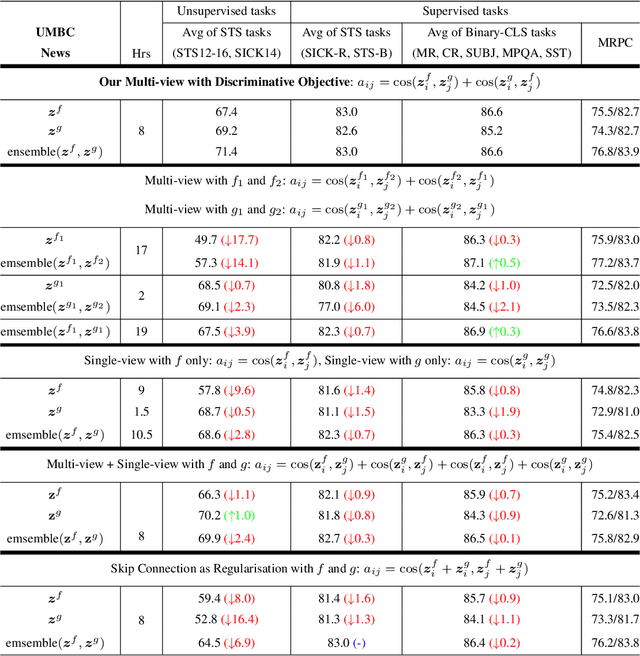
Multi-view learning can provide self-supervision when different views are available of the same data. Distributional hypothesis provides another form of useful self-supervision from adjacent sentences which are plentiful in large unlabelled corpora. Motivated by the asymmetry in the two hemispheres of the human brain as well as the observation that different learning architectures tend to emphasise different aspects of sentence meaning, we present two multi-view frameworks for learning sentence representations in an unsupervised fashion. One framework uses a generative objective and the other a discriminative one. In both frameworks, the final representation is an ensemble of two views, in which, one view encodes the input sentence with a Recurrent Neural Network (RNN), and the other view encodes it with a simple linear model. We show that, after learning, the vectors produced by our multi-view frameworks provide improved representations over their single-view learned counterparts, and the combination of different views gives representational improvement over each view and demonstrates solid transferability on standard downstream tasks.
Exploiting Invertible Decoders for Unsupervised Sentence Representation Learning
Sep 08, 2018
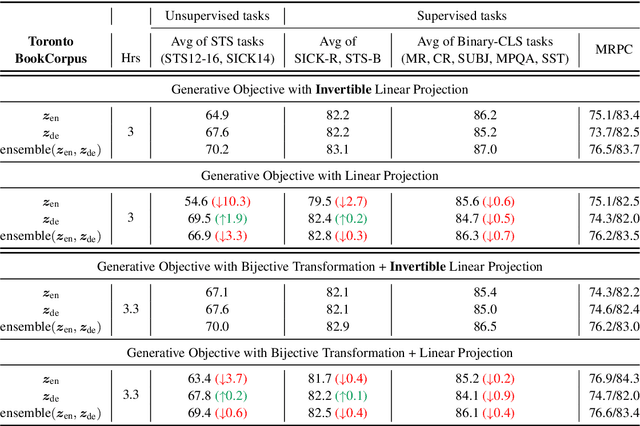
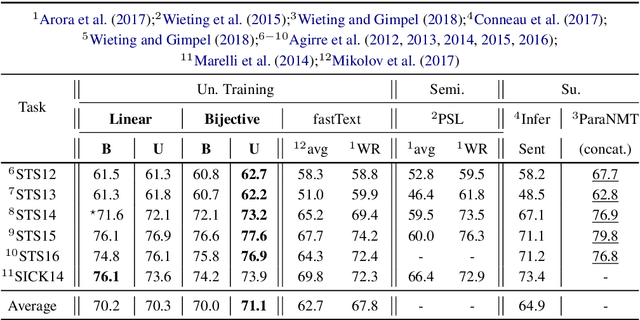
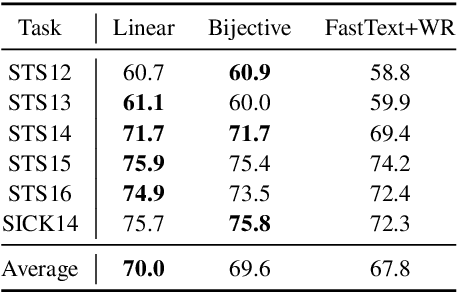
The encoder-decoder models for unsupervised sentence representation learning tend to discard the decoder after being trained on a large unlabelled corpus, since only the encoder is needed to map the input sentence into a vector representation. However, parameters learnt in the decoder also contain useful information about language. In order to utilise the decoder after learning, we present two types of decoding functions whose inverse can be easily derived without expensive inverse calculation. Therefore, the inverse of the decoding function serves as another encoder that produces sentence representations. We show that, with careful design of the decoding functions, the model learns good sentence representations, and the ensemble of the representations produced from the encoder and the inverse of the decoder demonstrate even better generalisation ability and solid transferability.
Speeding up Context-based Sentence Representation Learning with Non-autoregressive Convolutional Decoding
Jun 01, 2018
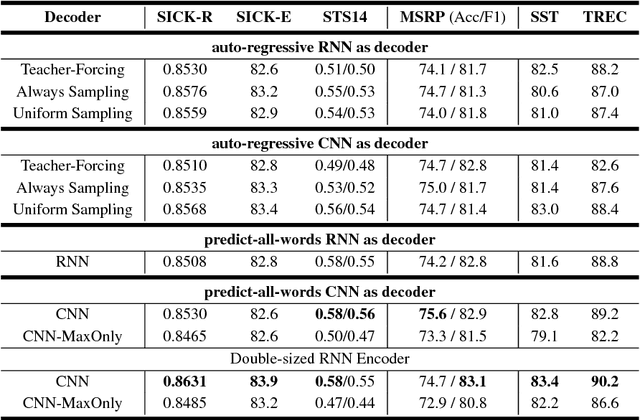
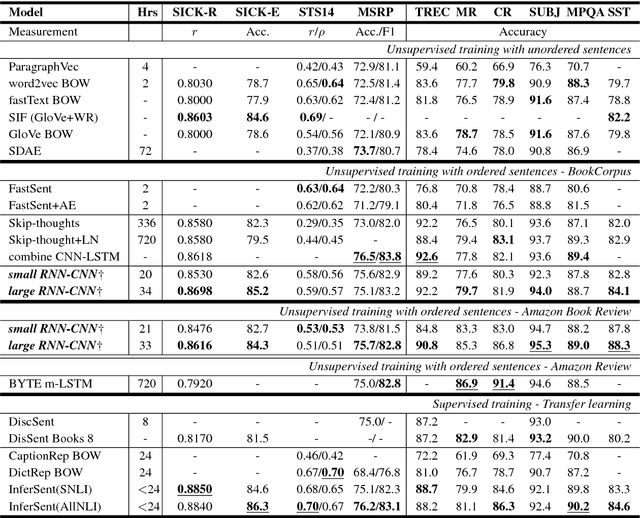

Context plays an important role in human language understanding, thus it may also be useful for machines learning vector representations of language. In this paper, we explore an asymmetric encoder-decoder structure for unsupervised context-based sentence representation learning. We carefully designed experiments to show that neither an autoregressive decoder nor an RNN decoder is required. After that, we designed a model which still keeps an RNN as the encoder, while using a non-autoregressive convolutional decoder. We further combine a suite of effective designs to significantly improve model efficiency while also achieving better performance. Our model is trained on two different large unlabelled corpora, and in both cases the transferability is evaluated on a set of downstream NLP tasks. We empirically show that our model is simple and fast while producing rich sentence representations that excel in downstream tasks.