 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Post-processing Methods for Word Embeddings
Paper and Code
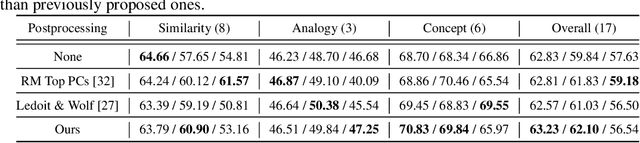

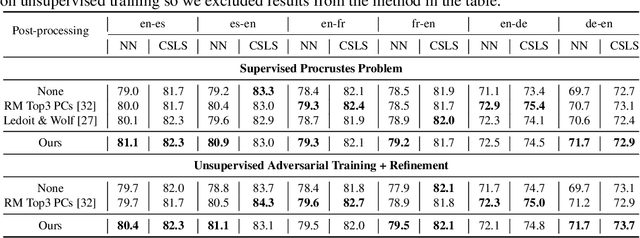
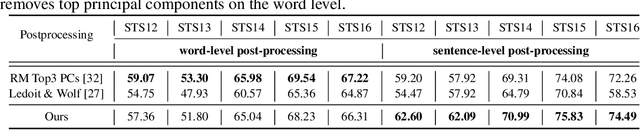
Word embeddings learnt from large corpora have been adopted in various applications in natural language processing and served as the general input representations to learning systems. Recently, a series of post-processing methods have been proposed to boost the performance of word embeddings on similarity comparison and analogy retrieval tasks, and some have been adapted to compose sentence representations. The general hypothesis behind these methods is that by enforcing the embedding space to be more isotropic, the similarity between words can be better expressed. We view these methods as an approach to shrink the covariance/gram matrix, which is estimated by learning word vectors, towards a scaled identity matrix. By optimising an objective in the semi-Riemannian manifold with Centralised Kernel Alignment (CKA), we are able to search for the optimal shrinkage parameter, and provide a post-processing method to smooth the spectrum of learnt word vectors which yields improved performance on downstream tasks.