 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFERGI: Automatic Annotation of User Preferences for Text-to-Image Generation from Spontaneous Facial Expression Reaction
Dec 05, 2023Researchers have proposed to use data of human preference feedback to fine-tune text-to-image generative models. However, the scalability of human feedback collection has been limited by its reliance on manual annotation. Therefore, we develop and test a method to automatically annotate user preferences from their spontaneous facial expression reaction to the generated images. We collect a dataset of Facial Expression Reaction to Generated Images (FERGI) and show that the activations of multiple facial action units (AUs) are highly correlated with user evaluations of the generated images. Specifically, AU4 (brow lowerer) is most consistently reflective of negative evaluations of the generated image. This can be useful in two ways. Firstly, we can automatically annotate user preferences between image pairs with substantial difference in AU4 responses to them with an accuracy significantly outperforming state-of-the-art scoring models. Secondly, directly integrating the AU4 responses with the scoring models improves their consistency with human preferences. Additionally, the AU4 response best reflects the user's evaluation of the image fidelity, making it complementary to the state-of-the-art scoring models, which are generally better at reflecting image-text alignment. Finally, this method of automatic annotation with facial expression analysis can be potentially generalized to other generation tasks. The code is available at https://github.com/ShuangquanFeng/FERGI, and the dataset is also available at the same link for research purposes.
Integrating Dependency Tree Into Self-attention for Sentence Representation
Mar 11, 2022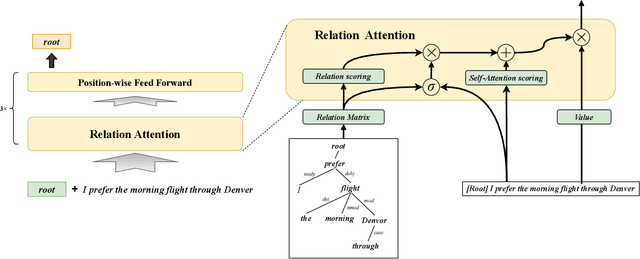



Recent progress on parse tree encoder for sentence representation learning is notable. However, these works mainly encode tree structures recursively, which is not conducive to parallelization. On the other hand, these works rarely take into account the labels of arcs in dependency trees. To address both issues, we propose Dependency-Transformer, which applies a relation-attention mechanism that works in concert with the self-attention mechanism. This mechanism aims to encode the dependency and the spatial positional relations between nodes in the dependency tree of sentences. By a score-based method, we successfully inject the syntax information without affecting Transformer's parallelizability. Our model outperforms or is comparable to the state-of-the-art methods on four tasks for sentence representation and has obvious advantages in computational efficiency.
PathSAGE: Spatial Graph Attention Neural Networks With Random Path Sampling
Mar 11, 2022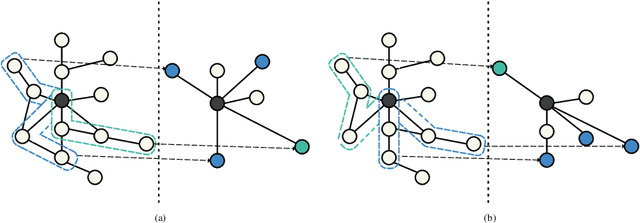

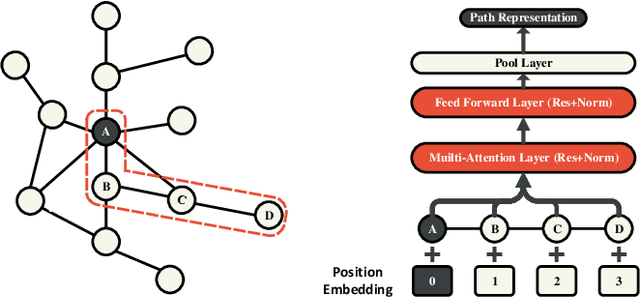

Graph Convolutional Networks (GCNs) achieve great success in non-Euclidean structure data processing recently. In existing studies, deeper layers are used in CCNs to extract deeper features of Euclidean structure data. However, for non-Euclidean structure data, too deep GCNs will confront with problems like "neighbor explosion" and "over-smoothing", it also cannot be applied to large datasets. To address these problems, we propose a model called PathSAGE, which can learn high-order topological information and improve the model's performance by expanding the receptive field. The model randomly samples paths starting from the central node and aggregates them by Transformer encoder. PathSAGE has only one layer of structure to aggregate nodes which avoid those problems above. The results of evaluation shows that our model achieves comparable performance with the state-of-the-art models in inductive learning tasks.