 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Dependency Tree Into Self-attention for Sentence Representation
Paper and Code
Mar 11, 2022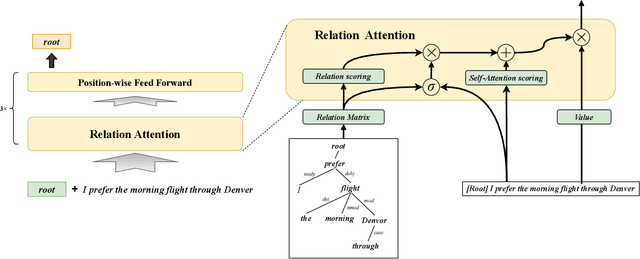



Recent progress on parse tree encoder for sentence representation learning is notable. However, these works mainly encode tree structures recursively, which is not conducive to parallelization. On the other hand, these works rarely take into account the labels of arcs in dependency trees. To address both issues, we propose Dependency-Transformer, which applies a relation-attention mechanism that works in concert with the self-attention mechanism. This mechanism aims to encode the dependency and the spatial positional relations between nodes in the dependency tree of sentences. By a score-based method, we successfully inject the syntax information without affecting Transformer's parallelizability. Our model outperforms or is comparable to the state-of-the-art methods on four tasks for sentence representation and has obvious advantages in computational efficiency.