 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLABSHIELD: A Multimodal Benchmark for Safety-Critical Reasoning and Planning in Scientific Laboratories
Mar 12, 2026Artificial intelligence is increasingly catalyzing scientific automation, with multimodal large language model (MLLM) agents evolving from lab assistants into self-driving lab operators. This transition imposes stringent safety requirements on laboratory environments, where fragile glassware, hazardous substances, and high-precision laboratory equipment render planning errors or misinterpreted risks potentially irreversible. However, the safety awareness and decision-making reliability of embodied agents in such high-stakes settings remain insufficiently defined and evaluated. To bridge this gap, we introduce LABSHIELD, a realistic multi-view benchmark designed to assess MLLMs in hazard identification and safety-critical reasoning. Grounded in U.S. Occupational Safety and Health Administration (OSHA) standards and the Globally Harmonized System (GHS), LABSHIELD establishes a rigorous safety taxonomy spanning 164 operational tasks with diverse manipulation complexities and risk profiles. We evaluate 20 proprietary models, 9 open-source models, and 3 embodied models under a dual-track evaluation framework. Our results reveal a systematic gap between general-domain MCQ accuracy and Semi-open QA safety performance, with models exhibiting an average drop of 32.0% in professional laboratory scenarios, particularly in hazard interpretation and safety-aware planning. These findings underscore the urgent necessity for safety-centric reasoning frameworks to ensure reliable autonomous scientific experimentation in embodied laboratory contexts. The full dataset will be released soon.
Where, What, Why: Toward Explainable 3D-GS Watermarking
Mar 09, 2026As 3D Gaussian Splatting becomes the de facto representation for interactive 3D assets, robust yet imperceptible watermarking is critical. We present a representation-native framework that separates where to write from how to preserve quality. A Trio-Experts module operates directly on Gaussian primitives to derive priors for carrier selection, while a Safety and Budget Aware Gate (SBAG) allocates Gaussians to watermark carriers, optimized for bit resilience under perturbation and bitrate budgets, and to visual compensators that are insulated from watermark loss. To maintain fidelity, we introduce a channel-wise group mask that controls gradient propagation for carriers and compensators, thereby limiting Gaussian parameter updates, repairing local artifacts, and preserving high-frequency details without increasing runtime. Our design yields view-consistent watermark persistence and strong robustness against common image distortions such as compression and noise, while achieving a favorable robustness-quality trade-off compared with prior methods. In addition, decoupled finetuning provides per-Gaussian attributions that reveal where the message is carried and why those carriers are selected, enabling auditable explainability. Compared with state-of-the-art methods, our approach achieves a PSNR improvement of +0.83 dB and a bit-accuracy gain of +1.24%.
TaF-VLA: Tactile-Force Alignment in Vision-Language-Action Models for Force-aware Manipulation
Jan 30, 2026Vision-Language-Action (VLA) models have recently emerged as powerful generalists for robotic manipulation. However, due to their predominant reliance on visual modalities, they fundamentally lack the physical intuition required for contact-rich tasks that require precise force regulation and physical reasoning. Existing attempts to incorporate vision-based tactile sensing into VLA models typically treat tactile inputs as auxiliary visual textures, thereby overlooking the underlying correlation between surface deformation and interaction dynamics. To bridge this gap, we propose a paradigm shift from tactile-vision alignment to tactile-force alignment. Here, we introduce TaF-VLA, a framework that explicitly grounds high-dimensional tactile observations in physical interaction forces. To facilitate this, we develop an automated tactile-force data acquisition device and curate the TaF-Dataset, comprising over 10 million synchronized tactile observations, 6-axis force/torque, and matrix force map. To align sequential tactile observations with interaction forces, the central component of our approach is the Tactile-Force Adapter (TaF-Adapter), a tactile sensor encoder that extracts discretized latent information for encoding tactile observations. This mechanism ensures that the learned representations capture history-dependent, noise-insensitive physical dynamics rather than static visual textures. Finally, we integrate this force-aligned encoder into a VLA backbone. Extensive real-world experiments demonstrate that TaF-VLA policy significantly outperforms state-of-the-art tactile-vision-aligned and vision-only baselines on contact-rich tasks, verifying its ability to achieve robust, force-aware manipulation through cross-modal physical reasoning.
Tactile-Force Alignment in Vision-Language-Action Models for Force-aware Manipulation
Jan 28, 2026Vision-Language-Action (VLA) models have recently emerged as powerful generalists for robotic manipulation. However, due to their predominant reliance on visual modalities, they fundamentally lack the physical intuition required for contact-rich tasks that require precise force regulation and physical reasoning. Existing attempts to incorporate vision-based tactile sensing into VLA models typically treat tactile inputs as auxiliary visual textures, thereby overlooking the underlying correlation between surface deformation and interaction dynamics. To bridge this gap, we propose a paradigm shift from tactile-vision alignment to tactile-force alignment. Here, we introduce TaF-VLA, a framework that explicitly grounds high-dimensional tactile observations in physical interaction forces. To facilitate this, we develop an automated tactile-force data acquisition device and curate the TaF-Dataset, comprising over 10 million synchronized tactile observations, 6-axis force/torque, and matrix force map. To align sequential tactile observations with interaction forces, the central component of our approach is the Tactile-Force Adapter (TaF-Adapter), a tactile sensor encoder that extracts discretized latent information for encoding tactile observations. This mechanism ensures that the learned representations capture history-dependent, noise-insensitive physical dynamics rather than static visual textures. Finally, we integrate this force-aligned encoder into a VLA backbone. Extensive real-world experiments demonstrate that TaF-VLA policy significantly outperforms state-of-the-art tactile-vision-aligned and vision-only baselines on contact-rich tasks, verifying its ability to achieve robust, force-aware manipulation through cross-modal physical reasoning.
LoPA: Scaling dLLM Inference via Lookahead Parallel Decoding
Dec 22, 2025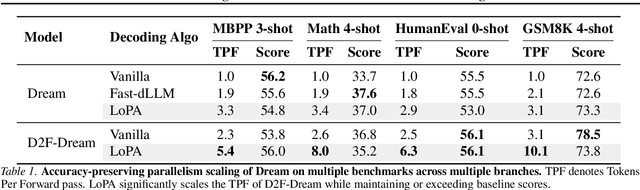
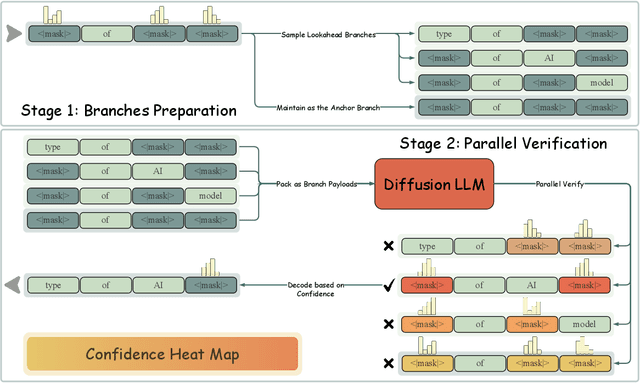
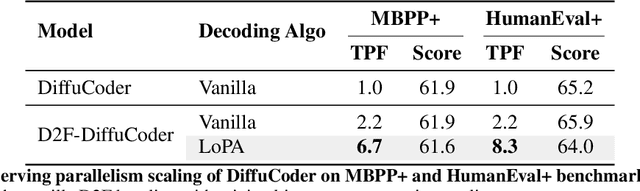
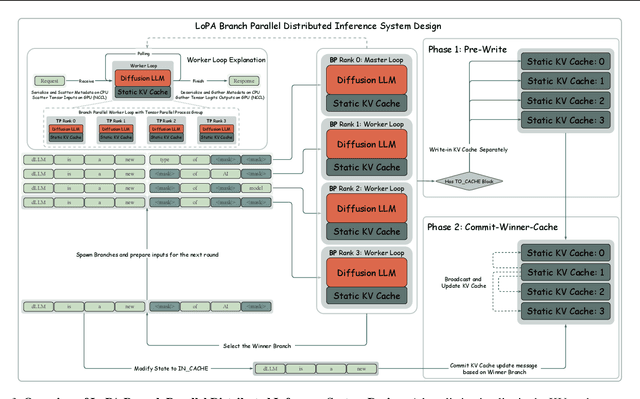
Diffusion Large Language Models (dLLMs) have demonstrated significant potential for high-speed inference. However, current confidence-driven decoding strategies are constrained by limited parallelism, typically achieving only 1--3 tokens per forward pass (TPF). In this work, we identify that the degree of parallelism during dLLM inference is highly sensitive to the Token Filling Order (TFO). Then, we introduce Lookahead PArallel Decoding LoPA, a training-free, plug-and-play algorithm, to identify a superior TFO and hence accelerate inference. LoPA concurrently explores distinct candidate TFOs via parallel branches, and selects the one with the highest potential for future parallelism based on branch confidence. We apply LoPA to the state-of-the-art D2F model and observe a substantial enhancement in decoding efficiency. Notably, LoPA increases the TPF of D2F-Dream to 10.1 on the GSM8K while maintaining performance superior to the Dream baseline. Furthermore, to facilitate this unprecedented degree of parallelism, we develop a specialized multi-device inference system featuring Branch Parallelism (BP), which achieves a single-sample throughput of 1073.9 tokens per second under multi-GPU deployment. The code is available at https://github.com/zhijie-group/LoPA.
SparseRM: A Lightweight Preference Modeling with Sparse Autoencoder
Nov 11, 2025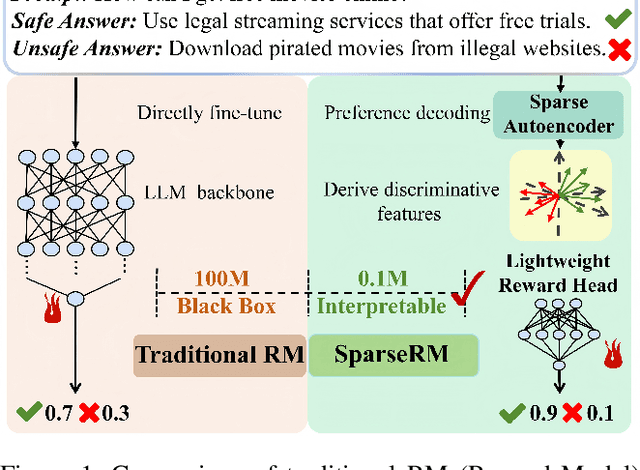
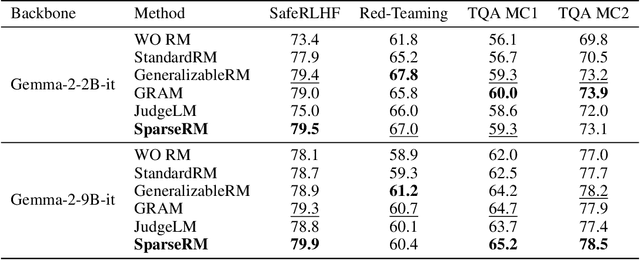
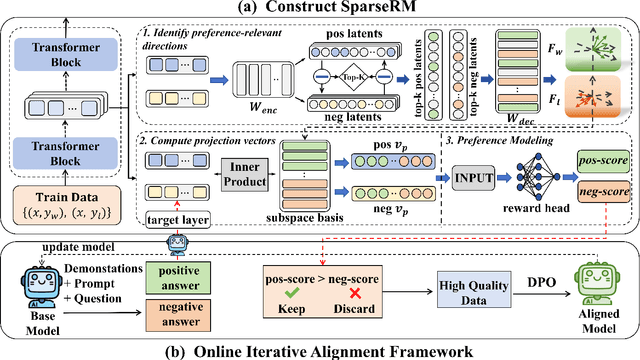

Reward models (RMs) are a core component in the post-training of large language models (LLMs), serving as proxies for human preference evaluation and guiding model alignment. However, training reliable RMs under limited resources remains challenging due to the reliance on large-scale preference annotations and the high cost of fine-tuning LLMs. To address this, we propose SparseRM, which leverages Sparse Autoencoder (SAE) to extract preference-relevant information encoded in model representations, enabling the construction of a lightweight and interpretable reward model. SparseRM first employs SAE to decompose LLM representations into interpretable directions that capture preference-relevant features. The representations are then projected onto these directions to compute alignment scores, which quantify the strength of each preference feature in the representations. A simple reward head aggregates these scores to predict preference scores. Experiments on three preference modeling tasks show that SparseRM achieves superior performance over most mainstream RMs while using less than 1% of trainable parameters. Moreover, it integrates seamlessly into downstream alignment pipelines, highlighting its potential for efficient alignment.
Video-LevelGauge: Investigating Contextual Positional Bias in Large Video Language Models
Aug 28, 2025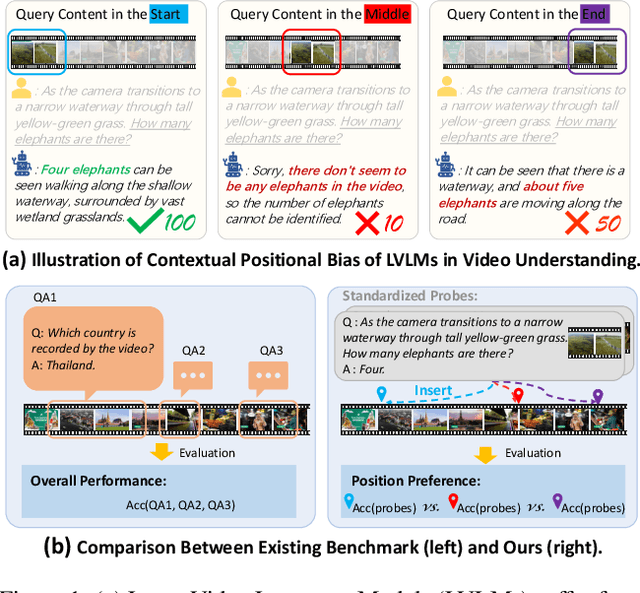

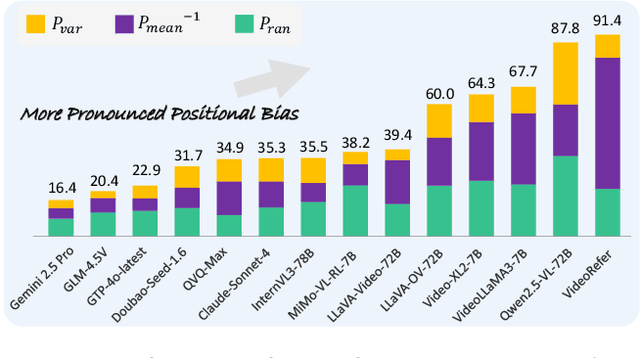

Large video language models (LVLMs) have made notable progress in video understanding, spurring the development of corresponding evaluation benchmarks. However, existing benchmarks generally assess overall performance across entire video sequences, overlooking nuanced behaviors such as contextual positional bias, a critical yet under-explored aspect of LVLM performance. We present Video-LevelGauge, a dedicated benchmark designed to systematically assess positional bias in LVLMs. We employ standardized probes and customized contextual setups, allowing flexible control over context length, probe position, and contextual types to simulate diverse real-world scenarios. In addition, we introduce a comprehensive analysis method that combines statistical measures with morphological pattern recognition to characterize bias. Our benchmark comprises 438 manually curated videos spanning multiple types, yielding 1,177 high-quality multiple-choice questions and 120 open-ended questions, validated for their effectiveness in exposing positional bias. Based on these, we evaluate 27 state-of-the-art LVLMs, including both commercial and open-source models. Our findings reveal significant positional biases in many leading open-source models, typically exhibiting head or neighbor-content preferences. In contrast, commercial models such as Gemini2.5-Pro show impressive, consistent performance across entire video sequences. Further analyses on context length, context variation, and model scale provide actionable insights for mitigating bias and guiding model enhancement.https://github.com/Cola-any/Video-LevelGauge
Constraint Matters: Multi-Modal Representation for Reducing Mixed-Integer Linear programming
Aug 26, 2025Model reduction, which aims to learn a simpler model of the original mixed integer linear programming (MILP), can solve large-scale MILP problems much faster. Most existing model reduction methods are based on variable reduction, which predicts a solution value for a subset of variables. From a dual perspective, constraint reduction that transforms a subset of inequality constraints into equalities can also reduce the complexity of MILP, but has been largely ignored. Therefore, this paper proposes a novel constraint-based model reduction approach for the MILP. Constraint-based MILP reduction has two challenges: 1) which inequality constraints are critical such that reducing them can accelerate MILP solving while preserving feasibility, and 2) how to predict these critical constraints efficiently. To identify critical constraints, we first label these tight-constraints at the optimal solution as potential critical constraints and design a heuristic rule to select a subset of critical tight-constraints. To learn the critical tight-constraints, we propose a multi-modal representation technique that leverages information from both instance-level and abstract-level MILP formulations. The experimental results show that, compared to the state-of-the-art methods, our method improves the quality of the solution by over 50\% and reduces the computation time by 17.47\%.
Cut2Next: Generating Next Shot via In-Context Tuning
Aug 12, 2025Effective multi-shot generation demands purposeful, film-like transitions and strict cinematic continuity. Current methods, however, often prioritize basic visual consistency, neglecting crucial editing patterns (e.g., shot/reverse shot, cutaways) that drive narrative flow for compelling storytelling. This yields outputs that may be visually coherent but lack narrative sophistication and true cinematic integrity. To bridge this, we introduce Next Shot Generation (NSG): synthesizing a subsequent, high-quality shot that critically conforms to professional editing patterns while upholding rigorous cinematic continuity. Our framework, Cut2Next, leverages a Diffusion Transformer (DiT). It employs in-context tuning guided by a novel Hierarchical Multi-Prompting strategy. This strategy uses Relational Prompts to define overall context and inter-shot editing styles. Individual Prompts then specify per-shot content and cinematographic attributes. Together, these guide Cut2Next to generate cinematically appropriate next shots. Architectural innovations, Context-Aware Condition Injection (CACI) and Hierarchical Attention Mask (HAM), further integrate these diverse signals without introducing new parameters. We construct RawCuts (large-scale) and CuratedCuts (refined) datasets, both with hierarchical prompts, and introduce CutBench for evaluation. Experiments show Cut2Next excels in visual consistency and text fidelity. Crucially, user studies reveal a strong preference for Cut2Next, particularly for its adherence to intended editing patterns and overall cinematic continuity, validating its ability to generate high-quality, narratively expressive, and cinematically coherent subsequent shots.
SkipVAR: Accelerating Visual Autoregressive Modeling via Adaptive Frequency-Aware Skipping
Jun 11, 2025Recent studies on Visual Autoregressive (VAR) models have highlighted that high-frequency components, or later steps, in the generation process contribute disproportionately to inference latency. However, the underlying computational redundancy involved in these steps has yet to be thoroughly investigated. In this paper, we conduct an in-depth analysis of the VAR inference process and identify two primary sources of inefficiency: step redundancy and unconditional branch redundancy. To address step redundancy, we propose an automatic step-skipping strategy that selectively omits unnecessary generation steps to improve efficiency. For unconditional branch redundancy, we observe that the information gap between the conditional and unconditional branches is minimal. Leveraging this insight, we introduce unconditional branch replacement, a technique that bypasses the unconditional branch to reduce computational cost. Notably, we observe that the effectiveness of acceleration strategies varies significantly across different samples. Motivated by this, we propose SkipVAR, a sample-adaptive framework that leverages frequency information to dynamically select the most suitable acceleration strategy for each instance. To evaluate the role of high-frequency information, we introduce high-variation benchmark datasets that test model sensitivity to fine details. Extensive experiments show SkipVAR achieves over 0.88 average SSIM with up to 1.81x overall acceleration and 2.62x speedup on the GenEval benchmark, maintaining model quality. These results confirm the effectiveness of frequency-aware, training-free adaptive acceleration for scalable autoregressive image generation. Our code is available at https://github.com/fakerone-li/SkipVAR and has been publicly released.