 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtoms of Thought: Universal EEG Representation Learning with Microstates
May 19, 2026Learning universal representations from electroencephalogram (EEG) signals is a cutting-edge approach in the field of neuroinformatics and brain-computer interfaces (BCIs). Conventionally, EEG is treated as a multivariate temporal signal, where time- or frequency-domain features are extracted for representation learning. This paper investigates a simple yet effective EEG representation, i.e., microstates. Microstates represent the building blocks of brain activity patterns at a microscopic time scale. We build a universal microstate tokenizer from a large medical EEG dataset by clustering continuous EEG signals into sequences of discrete microstates. The microstate tokenizer is then adopted universally across a series of downstream tasks, including sleep staging, emotion recognition, and motor imagery classification. Experimental results show that EEG representation learning with microstates outperforms traditional time-domain and frequency-domain features under different models and across different tasks. Further analysis shows that microstates offer greater interpretability and scalability, thereby opening up applications in both cognitive neuroscience and clinical research.
OneDrive: Unified Multi-Paradigm Driving with Vision-Language-Action Models
Apr 20, 2026Vision-Language Models(VLMs) excel at autoregressive text generation, yet end-to-end autonomous driving requires multi-task learning with structured outputs and heterogeneous decoding behaviors, such as autoregressive language generation, parallel object detection and trajectory regression. To accommodate these differences, existing systems typically introduce separate or cascaded decoders, resulting in architectural fragmentation and limited backbone reuse. In this work, we present a unified autonomous driving framework built upon a pretrained VLM, where heterogeneous decoding behaviors are reconciled within a single transformer decoder. We demonstrate that pretrained VLM attention exhibits strong transferability beyond pure language modeling. By organizing visual and structured query tokens within a single causal decoder, structured queries can naturally condition on visual context through the original attention mechanism. Textual and structured outputs share a common attention backbone, enabling stable joint optimization across heterogeneous tasks. Trajectory planning is realized within the same causal LLM decoder by introducing structured trajectory queries. This unified formulation enables planning to share the pretrained attention backbone with images and perception tokens. Extensive experiments on end-to-end autonomous driving benchmarks demonstrate state-of-the-art performance, including 0.28 L2 and 0.18 collision rate on nuScenes open-loop evaluation and competitive results (86.8 PDMS) on NAVSIM closed-loop evaluation. The full model preserves multi-modal generation capability, while an efficient inference mode achieves approximately 40% lower latency. Code and models are available at https://github.com/Z1zyw/OneDrive
sleep2vec: Unified Cross-Modal Alignment for Heterogeneous Nocturnal Biosignals
Feb 14, 2026Tasks ranging from sleep staging to clinical diagnosis traditionally rely on standard polysomnography (PSG) devices, bedside monitors and wearable devices, which capture diverse nocturnal biosignals (e.g., EEG, EOG, ECG, SpO$_2$). However, heterogeneity across devices and frequent sensor dropout pose significant challenges for unified modelling of these multimodal signals. We present \texttt{sleep2vec}, a foundation model for diverse and incomplete nocturnal biosignals that learns a shared representation via cross-modal alignment. \texttt{sleep2vec} is contrastively pre-trained on 42,249 overnight recordings spanning nine modalities using a \textit{Demography, Age, Site \& History-aware InfoNCE} objective that incorporates physiological and acquisition metadata (\textit{e.g.}, age, gender, recording site) to dynamically weight negatives and mitigate cohort-specific shortcuts. On downstream sleep staging and clinical outcome assessment, \texttt{sleep2vec} consistently outperforms strong baselines and remains robust to any subset of available modalities and sensor dropout. We further characterize, to our knowledge for the first time, scaling laws for nocturnal biosignals with respect to modality diversity and model capacity. Together, these results show that unified cross-modal alignment, coupled with principled scaling, enables label-efficient, general-purpose modelling of real-world nocturnal biosignals.
ColaVLA: Leveraging Cognitive Latent Reasoning for Hierarchical Parallel Trajectory Planning in Autonomous Driving
Dec 31, 2025Autonomous driving requires generating safe and reliable trajectories from complex multimodal inputs. Traditional modular pipelines separate perception, prediction, and planning, while recent end-to-end (E2E) systems learn them jointly. Vision-language models (VLMs) further enrich this paradigm by introducing cross-modal priors and commonsense reasoning, yet current VLM-based planners face three key challenges: (i) a mismatch between discrete text reasoning and continuous control, (ii) high latency from autoregressive chain-of-thought decoding, and (iii) inefficient or non-causal planners that limit real-time deployment. We propose ColaVLA, a unified vision-language-action framework that transfers reasoning from text to a unified latent space and couples it with a hierarchical, parallel trajectory decoder. The Cognitive Latent Reasoner compresses scene understanding into compact, decision-oriented meta-action embeddings through ego-adaptive selection and only two VLM forward passes. The Hierarchical Parallel Planner then generates multi-scale, causality-consistent trajectories in a single forward pass. Together, these components preserve the generalization and interpretability of VLMs while enabling efficient, accurate and safe trajectory generation. Experiments on the nuScenes benchmark show that ColaVLA achieves state-of-the-art performance in both open-loop and closed-loop settings with favorable efficiency and robustness.
Foresight in Motion: Reinforcing Trajectory Prediction with Reward Heuristics
Jul 16, 2025



Motion forecasting for on-road traffic agents presents both a significant challenge and a critical necessity for ensuring safety in autonomous driving systems. In contrast to most existing data-driven approaches that directly predict future trajectories, we rethink this task from a planning perspective, advocating a "First Reasoning, Then Forecasting" strategy that explicitly incorporates behavior intentions as spatial guidance for trajectory prediction. To achieve this, we introduce an interpretable, reward-driven intention reasoner grounded in a novel query-centric Inverse Reinforcement Learning (IRL) scheme. Our method first encodes traffic agents and scene elements into a unified vectorized representation, then aggregates contextual features through a query-centric paradigm. This enables the derivation of a reward distribution, a compact yet informative representation of the target agent's behavior within the given scene context via IRL. Guided by this reward heuristic, we perform policy rollouts to reason about multiple plausible intentions, providing valuable priors for subsequent trajectory generation. Finally, we develop a hierarchical DETR-like decoder integrated with bidirectional selective state space models to produce accurate future trajectories along with their associated probabilities. Extensive experiments on the large-scale Argoverse and nuScenes motion forecasting datasets demonstrate that our approach significantly enhances trajectory prediction confidence, achieving highly competitive performance relative to state-of-the-art methods.
SOLVE: Synergy of Language-Vision and End-to-End Networks for Autonomous Driving
May 22, 2025The integration of Vision-Language Models (VLMs) into autonomous driving systems has shown promise in addressing key challenges such as learning complexity, interpretability, and common-sense reasoning. However, existing approaches often struggle with efficient integration and realtime decision-making due to computational demands. In this paper, we introduce SOLVE, an innovative framework that synergizes VLMs with end-to-end (E2E) models to enhance autonomous vehicle planning. Our approach emphasizes knowledge sharing at the feature level through a shared visual encoder, enabling comprehensive interaction between VLM and E2E components. We propose a Trajectory Chain-of-Thought (T-CoT) paradigm, which progressively refines trajectory predictions, reducing uncertainty and improving accuracy. By employing a temporal decoupling strategy, SOLVE achieves efficient cooperation by aligning high-quality VLM outputs with E2E real-time performance. Evaluated on the nuScenes dataset, our method demonstrates significant improvements in trajectory prediction accuracy, paving the way for more robust and reliable autonomous driving systems.
GaussianPainter: Painting Point Cloud into 3D Gaussians with Normal Guidance
Dec 23, 2024



In this paper, we present GaussianPainter, the first method to paint a point cloud into 3D Gaussians given a reference image. GaussianPainter introduces an innovative feed-forward approach to overcome the limitations of time-consuming test-time optimization in 3D Gaussian splatting. Our method addresses a critical challenge in the field: the non-uniqueness problem inherent in the large parameter space of 3D Gaussian splatting. This space, encompassing rotation, anisotropic scales, and spherical harmonic coefficients, introduces the challenge of rendering similar images from substantially different Gaussian fields. As a result, feed-forward networks face instability when attempting to directly predict high-quality Gaussian fields, struggling to converge on consistent parameters for a given output. To address this issue, we propose to estimate a surface normal for each point to determine its Gaussian rotation. This strategy enables the network to effectively predict the remaining Gaussian parameters in the constrained space. We further enhance our approach with an appearance injection module, incorporating reference image appearance into Gaussian fields via a multiscale triplane representation. Our method successfully balances efficiency and fidelity in 3D Gaussian generation, achieving high-quality, diverse, and robust 3D content creation from point clouds in a single forward pass.
SleepNetZero: Zero-Burden Zero-Shot Reliable Sleep Staging With Neural Networks Based on Ballistocardiograms
Oct 30, 2024Sleep monitoring plays a crucial role in maintaining good health, with sleep staging serving as an essential metric in the monitoring process. Traditional methods, utilizing medical sensors like EEG and ECG, can be effective but often present challenges such as unnatural user experience, complex deployment, and high costs. Ballistocardiography~(BCG), a type of piezoelectric sensor signal, offers a non-invasive, user-friendly, and easily deployable alternative for long-term home monitoring. However, reliable BCG-based sleep staging is challenging due to the limited sleep monitoring data available for BCG. A restricted training dataset prevents the model from generalization across populations. Additionally, transferring to BCG faces difficulty ensuring model robustness when migrating from other data sources. To address these issues, we introduce SleepNetZero, a zero-shot learning based approach for sleep staging. To tackle the generalization challenge, we propose a series of BCG feature extraction methods that align BCG components with corresponding respiratory, cardiac, and movement channels in PSG. This allows models to be trained on large-scale PSG datasets that are diverse in population. For the migration challenge, we employ data augmentation techniques, significantly enhancing generalizability. We conducted extensive training and testing on large datasets~(12393 records from 9637 different subjects), achieving an accuracy of 0.803 and a Cohen's Kappa of 0.718. ZeroSleepNet was also deployed in real prototype~(monitoring pads) and tested in actual hospital settings~(265 users), demonstrating an accuracy of 0.697 and a Cohen's Kappa of 0.589. To the best of our knowledge, this work represents the first known reliable BCG-based sleep staging effort and marks a significant step towards in-home health monitoring.
Mozart's Touch: A Lightweight Multi-modal Music Generation Framework Based on Pre-Trained Large Models
May 07, 2024
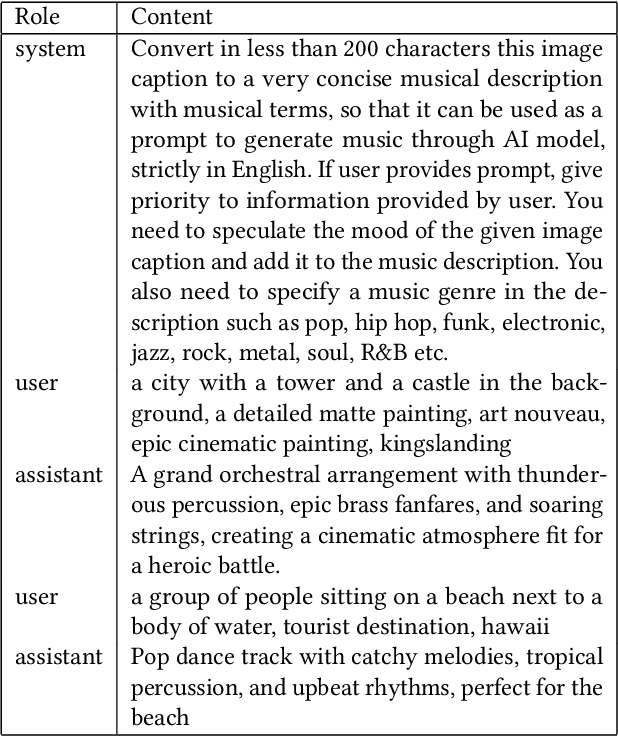

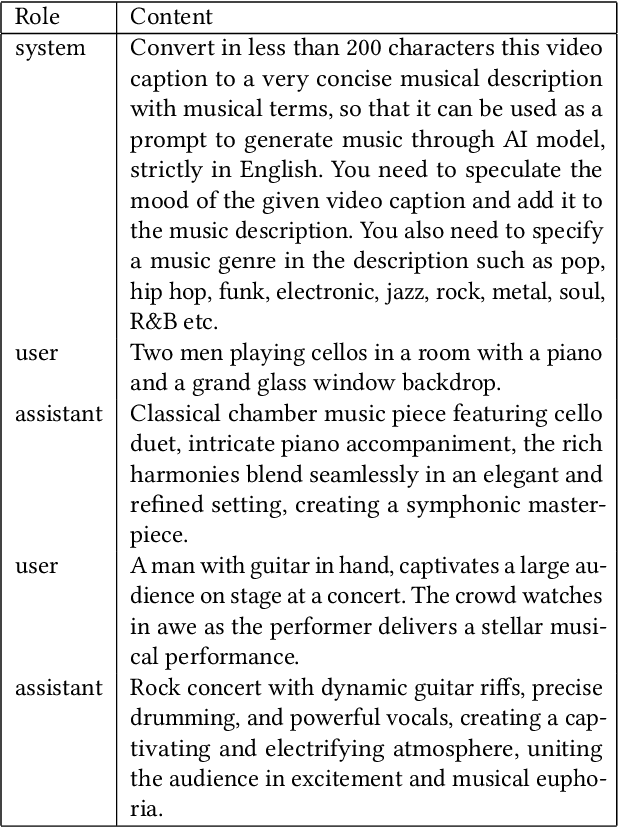
In recent years, AI-Generated Content (AIGC) has witnessed rapid advancements, facilitating the generation of music, images, and other forms of artistic expression across various industries. However, researches on general multi-modal music generation model remain scarce. To fill this gap, we propose a multi-modal music generation framework Mozart's Touch. It could generate aligned music with the cross-modality inputs, such as images, videos and text. Mozart's Touch is composed of three main components: Multi-modal Captioning Module, Large Language Model (LLM) Understanding & Bridging Module, and Music Generation Module. Unlike traditional approaches, Mozart's Touch requires no training or fine-tuning pre-trained models, offering efficiency and transparency through clear, interpretable prompts. We also introduce "LLM-Bridge" method to resolve the heterogeneous representation problems between descriptive texts of different modalities. We conduct a series of objective and subjective evaluations on the proposed model, and results indicate that our model surpasses the performance of current state-of-the-art models. Our codes and examples is availble at: https://github.com/WangTooNaive/MozartsTouch
TrajectoryFormer: 3D Object Tracking Transformer with Predictive Trajectory Hypotheses
Jun 09, 2023



3D multi-object tracking (MOT) is vital for many applications including autonomous driving vehicles and service robots. With the commonly used tracking-by-detection paradigm, 3D MOT has made important progress in recent years. However, these methods only use the detection boxes of the current frame to obtain trajectory-box association results, which makes it impossible for the tracker to recover objects missed by the detector. In this paper, we present TrajectoryFormer, a novel point-cloud-based 3D MOT framework. To recover the missed object by detector, we generates multiple trajectory hypotheses with hybrid candidate boxes, including temporally predicted boxes and current-frame detection boxes, for trajectory-box association. The predicted boxes can propagate object's history trajectory information to the current frame and thus the network can tolerate short-term miss detection of the tracked objects. We combine long-term object motion feature and short-term object appearance feature to create per-hypothesis feature embedding, which reduces the computational overhead for spatial-temporal encoding. Additionally, we introduce a Global-Local Interaction Module to conduct information interaction among all hypotheses and models their spatial relations, leading to accurate estimation of hypotheses. Our TrajectoryFormer achieves state-of-the-art performance on the Waymo 3D MOT benchmarks.