 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathCanvas: Intrinsic Visual Chain-of-Thought for Multimodal Mathematical Reasoning
Oct 16, 2025While Large Language Models (LLMs) have excelled in textual reasoning, they struggle with mathematical domains like geometry that intrinsically rely on visual aids. Existing approaches to Visual Chain-of-Thought (VCoT) are often limited by rigid external tools or fail to generate the high-fidelity, strategically-timed diagrams necessary for complex problem-solving. To bridge this gap, we introduce MathCanvas, a comprehensive framework designed to endow unified Large Multimodal Models (LMMs) with intrinsic VCoT capabilities for mathematics. Our approach consists of two phases. First, a Visual Manipulation stage pre-trains the model on a novel 15.2M-pair corpus, comprising 10M caption-to-diagram pairs (MathCanvas-Imagen) and 5.2M step-by-step editing trajectories (MathCanvas-Edit), to master diagram generation and editing. Second, a Strategic Visual-Aided Reasoning stage fine-tunes the model on MathCanvas-Instruct, a new 219K-example dataset of interleaved visual-textual reasoning paths, teaching it when and how to leverage visual aids. To facilitate rigorous evaluation, we introduce MathCanvas-Bench, a challenging benchmark with 3K problems that require models to produce interleaved visual-textual solutions. Our model, BAGEL-Canvas, trained under this framework, achieves an 86% relative improvement over strong LMM baselines on MathCanvas-Bench, demonstrating excellent generalization to other public math benchmarks. Our work provides a complete toolkit-framework, datasets, and benchmark-to unlock complex, human-like visual-aided reasoning in LMMs. Project Page: https://mathcanvas.github.io/
FLUX-Reason-6M & PRISM-Bench: A Million-Scale Text-to-Image Reasoning Dataset and Comprehensive Benchmark
Sep 11, 2025The advancement of open-source text-to-image (T2I) models has been hindered by the absence of large-scale, reasoning-focused datasets and comprehensive evaluation benchmarks, resulting in a performance gap compared to leading closed-source systems. To address this challenge, We introduce FLUX-Reason-6M and PRISM-Bench (Precise and Robust Image Synthesis Measurement Benchmark). FLUX-Reason-6M is a massive dataset consisting of 6 million high-quality FLUX-generated images and 20 million bilingual (English and Chinese) descriptions specifically designed to teach complex reasoning. The image are organized according to six key characteristics: Imagination, Entity, Text rendering, Style, Affection, and Composition, and design explicit Generation Chain-of-Thought (GCoT) to provide detailed breakdowns of image generation steps. The whole data curation takes 15,000 A100 GPU days, providing the community with a resource previously unattainable outside of large industrial labs. PRISM-Bench offers a novel evaluation standard with seven distinct tracks, including a formidable Long Text challenge using GCoT. Through carefully designed prompts, it utilizes advanced vision-language models for nuanced human-aligned assessment of prompt-image alignment and image aesthetics. Our extensive evaluation of 19 leading models on PRISM-Bench reveals critical performance gaps and highlights specific areas requiring improvement. Our dataset, benchmark, and evaluation code are released to catalyze the next wave of reasoning-oriented T2I generation. Project page: https://flux-reason-6m.github.io/ .
T2I-ReasonBench: Benchmarking Reasoning-Informed Text-to-Image Generation
Aug 24, 2025



We propose T2I-ReasonBench, a benchmark evaluating reasoning capabilities of text-to-image (T2I) models. It consists of four dimensions: Idiom Interpretation, Textual Image Design, Entity-Reasoning and Scientific-Reasoning. We propose a two-stage evaluation protocol to assess the reasoning accuracy and image quality. We benchmark various T2I generation models, and provide comprehensive analysis on their performances.
GoT-R1: Unleashing Reasoning Capability of MLLM for Visual Generation with Reinforcement Learning
May 22, 2025Visual generation models have made remarkable progress in creating realistic images from text prompts, yet struggle with complex prompts that specify multiple objects with precise spatial relationships and attributes. Effective handling of such prompts requires explicit reasoning about the semantic content and spatial layout. We present GoT-R1, a framework that applies reinforcement learning to enhance semantic-spatial reasoning in visual generation. Building upon the Generation Chain-of-Thought approach, GoT-R1 enables models to autonomously discover effective reasoning strategies beyond predefined templates through carefully designed reinforcement learning. To achieve this, we propose a dual-stage multi-dimensional reward framework that leverages MLLMs to evaluate both the reasoning process and final output, enabling effective supervision across the entire generation pipeline. The reward system assesses semantic alignment, spatial accuracy, and visual quality in a unified approach. Experimental results demonstrate significant improvements on T2I-CompBench benchmark, particularly in compositional tasks involving precise spatial relationships and attribute binding. GoT-R1 advances the state-of-the-art in image generation by successfully transferring sophisticated reasoning capabilities to the visual generation domain. To facilitate future research, we make our code and pretrained models publicly available at https://github.com/gogoduan/GoT-R1.
CrossLMM: Decoupling Long Video Sequences from LMMs via Dual Cross-Attention Mechanisms
May 22, 2025The advent of Large Multimodal Models (LMMs) has significantly enhanced Large Language Models (LLMs) to process and interpret diverse data modalities (e.g., image and video). However, as input complexity increases, particularly with long video sequences, the number of required tokens has grown significantly, leading to quadratically computational costs. This has made the efficient compression of video tokens in LMMs, while maintaining performance integrity, a pressing research challenge. In this paper, we introduce CrossLMM, decoupling long video sequences from LMMs via a dual cross-attention mechanism, which substantially reduces visual token quantity with minimal performance degradation. Specifically, we first implement a significant token reduction from pretrained visual encoders through a pooling methodology. Then, within LLM layers, we employ a visual-to-visual cross-attention mechanism, wherein the pooled visual tokens function as queries against the original visual token set. This module enables more efficient token utilization while retaining fine-grained informational fidelity. In addition, we introduce a text-to-visual cross-attention mechanism, for which the text tokens are enhanced through interaction with the original visual tokens, enriching the visual comprehension of the text tokens. Comprehensive empirical evaluation demonstrates that our approach achieves comparable or superior performance across diverse video-based LMM benchmarks, despite utilizing substantially fewer computational resources.
SOLVE: Synergy of Language-Vision and End-to-End Networks for Autonomous Driving
May 22, 2025The integration of Vision-Language Models (VLMs) into autonomous driving systems has shown promise in addressing key challenges such as learning complexity, interpretability, and common-sense reasoning. However, existing approaches often struggle with efficient integration and realtime decision-making due to computational demands. In this paper, we introduce SOLVE, an innovative framework that synergizes VLMs with end-to-end (E2E) models to enhance autonomous vehicle planning. Our approach emphasizes knowledge sharing at the feature level through a shared visual encoder, enabling comprehensive interaction between VLM and E2E components. We propose a Trajectory Chain-of-Thought (T-CoT) paradigm, which progressively refines trajectory predictions, reducing uncertainty and improving accuracy. By employing a temporal decoupling strategy, SOLVE achieves efficient cooperation by aligning high-quality VLM outputs with E2E real-time performance. Evaluated on the nuScenes dataset, our method demonstrates significant improvements in trajectory prediction accuracy, paving the way for more robust and reliable autonomous driving systems.
GoT: Unleashing Reasoning Capability of Multimodal Large Language Model for Visual Generation and Editing
Mar 13, 2025Current image generation and editing methods primarily process textual prompts as direct inputs without reasoning about visual composition and explicit operations. We present Generation Chain-of-Thought (GoT), a novel paradigm that enables generation and editing through an explicit language reasoning process before outputting images. This approach transforms conventional text-to-image generation and editing into a reasoning-guided framework that analyzes semantic relationships and spatial arrangements. We define the formulation of GoT and construct large-scale GoT datasets containing over 9M samples with detailed reasoning chains capturing semantic-spatial relationships. To leverage the advantages of GoT, we implement a unified framework that integrates Qwen2.5-VL for reasoning chain generation with an end-to-end diffusion model enhanced by our novel Semantic-Spatial Guidance Module. Experiments show our GoT framework achieves excellent performance on both generation and editing tasks, with significant improvements over baselines. Additionally, our approach enables interactive visual generation, allowing users to explicitly modify reasoning steps for precise image adjustments. GoT pioneers a new direction for reasoning-driven visual generation and editing, producing images that better align with human intent. To facilitate future research, we make our datasets, code, and pretrained models publicly available at https://github.com/rongyaofang/GoT.
StreamChat: Chatting with Streaming Video
Dec 11, 2024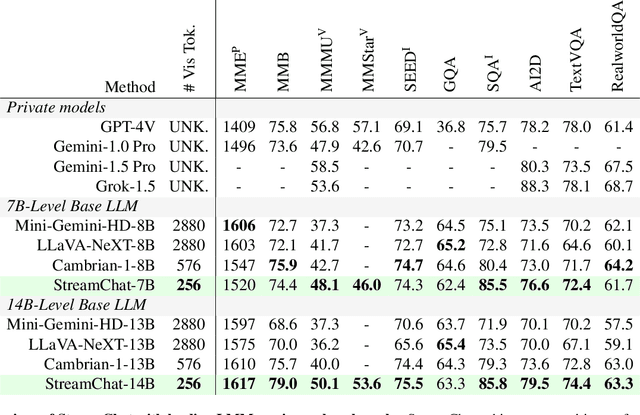
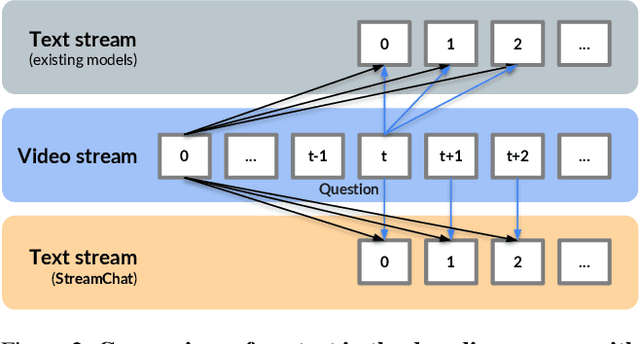

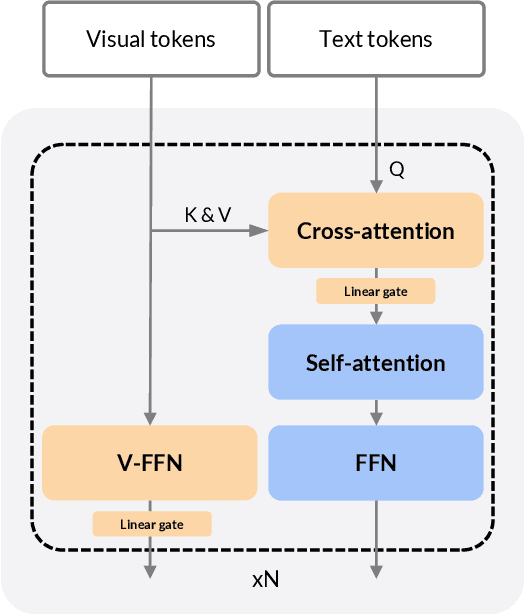
This paper presents StreamChat, a novel approach that enhances the interaction capabilities of Large Multimodal Models (LMMs) with streaming video content. In streaming interaction scenarios, existing methods rely solely on visual information available at the moment a question is posed, resulting in significant delays as the model remains unaware of subsequent changes in the streaming video. StreamChat addresses this limitation by innovatively updating the visual context at each decoding step, ensuring that the model utilizes up-to-date video content throughout the decoding process. Additionally, we introduce a flexible and efficient crossattention-based architecture to process dynamic streaming inputs while maintaining inference efficiency for streaming interactions. Furthermore, we construct a new dense instruction dataset to facilitate the training of streaming interaction models, complemented by a parallel 3D-RoPE mechanism that encodes the relative temporal information of visual and text tokens. Experimental results demonstrate that StreamChat achieves competitive performance on established image and video benchmarks and exhibits superior capabilities in streaming interaction scenarios compared to state-of-the-art video LMM.
PUMA: Empowering Unified MLLM with Multi-granular Visual Generation
Oct 17, 2024



Recent advancements in multimodal foundation models have yielded significant progress in vision-language understanding. Initial attempts have also explored the potential of multimodal large language models (MLLMs) for visual content generation. However, existing works have insufficiently addressed the varying granularity demands of different image generation tasks within a unified MLLM paradigm - from the diversity required in text-to-image generation to the precise controllability needed in image manipulation. In this work, we propose PUMA, emPowering Unified MLLM with Multi-grAnular visual generation. PUMA unifies multi-granular visual features as both inputs and outputs of MLLMs, elegantly addressing the different granularity requirements of various image generation tasks within a unified MLLM framework. Following multimodal pretraining and task-specific instruction tuning, PUMA demonstrates proficiency in a wide range of multimodal tasks. This work represents a significant step towards a truly unified MLLM capable of adapting to the granularity demands of various visual tasks. The code and model will be released in https://github.com/rongyaofang/PUMA.
FouriScale: A Frequency Perspective on Training-Free High-Resolution Image Synthesis
Mar 19, 2024In this study, we delve into the generation of high-resolution images from pre-trained diffusion models, addressing persistent challenges, such as repetitive patterns and structural distortions, that emerge when models are applied beyond their trained resolutions. To address this issue, we introduce an innovative, training-free approach FouriScale from the perspective of frequency domain analysis. We replace the original convolutional layers in pre-trained diffusion models by incorporating a dilation technique along with a low-pass operation, intending to achieve structural consistency and scale consistency across resolutions, respectively. Further enhanced by a padding-then-crop strategy, our method can flexibly handle text-to-image generation of various aspect ratios. By using the FouriScale as guidance, our method successfully balances the structural integrity and fidelity of generated images, achieving an astonishing capacity of arbitrary-size, high-resolution, and high-quality generation. With its simplicity and compatibility, our method can provide valuable insights for future explorations into the synthesis of ultra-high-resolution images. The code will be released at https://github.com/LeonHLJ/FouriScale.