 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSASep: Saliency-Aware Structured Separation of Geometry and Feature for Open Set Learning on Point Clouds
Jun 16, 2025Recent advancements in deep learning have greatly enhanced 3D object recognition, but most models are limited to closed-set scenarios, unable to handle unknown samples in real-world applications. Open-set recognition (OSR) addresses this limitation by enabling models to both classify known classes and identify novel classes. However, current OSR methods rely on global features to differentiate known and unknown classes, treating the entire object uniformly and overlooking the varying semantic importance of its different parts. To address this gap, we propose Salience-Aware Structured Separation (SASep), which includes (i) a tunable semantic decomposition (TSD) module to semantically decompose objects into important and unimportant parts, (ii) a geometric synthesis strategy (GSS) to generate pseudo-unknown objects by combining these unimportant parts, and (iii) a synth-aided margin separation (SMS) module to enhance feature-level separation by expanding the feature distributions between classes. Together, these components improve both geometric and feature representations, enhancing the model's ability to effectively distinguish known and unknown classes. Experimental results show that SASep achieves superior performance in 3D OSR, outperforming existing state-of-the-art methods.
Fancy123: One Image to High-Quality 3D Mesh Generation via Plug-and-Play Deformation
Nov 25, 2024



Generating 3D meshes from a single image is an important but ill-posed task. Existing methods mainly adopt 2D multiview diffusion models to generate intermediate multiview images, and use the Large Reconstruction Model (LRM) to create the final meshes. However, the multiview images exhibit local inconsistencies, and the meshes often lack fidelity to the input image or look blurry. We propose Fancy123, featuring two enhancement modules and an unprojection operation to address the above three issues, respectively. The appearance enhancement module deforms the 2D multiview images to realign misaligned pixels for better multiview consistency. The fidelity enhancement module deforms the 3D mesh to match the input image. The unprojection of the input image and deformed multiview images onto LRM's generated mesh ensures high clarity, discarding LRM's predicted blurry-looking mesh colors. Extensive qualitative and quantitative experiments verify Fancy123's SoTA performance with significant improvement. Also, the two enhancement modules are plug-and-play and work at inference time, allowing seamless integration into various existing single-image-to-3D methods.
More Text, Less Point: Towards 3D Data-Efficient Point-Language Understanding
Aug 28, 2024
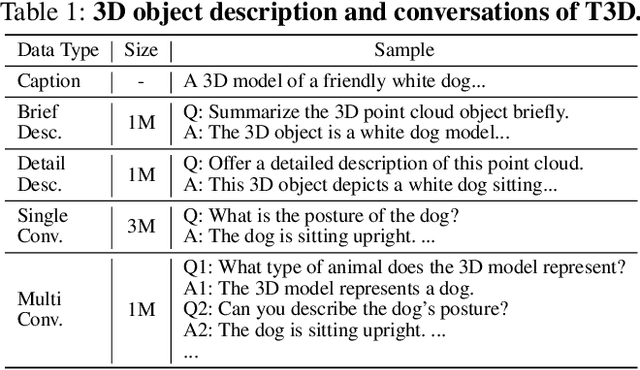
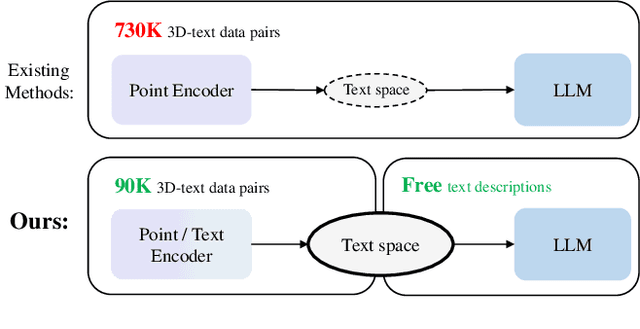
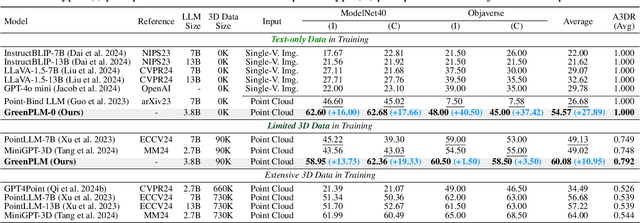
Enabling Large Language Models (LLMs) to comprehend the 3D physical world remains a significant challenge. Due to the lack of large-scale 3D-text pair datasets, the success of LLMs has yet to be replicated in 3D understanding. In this paper, we rethink this issue and propose a new task: 3D Data-Efficient Point-Language Understanding. The goal is to enable LLMs to achieve robust 3D object understanding with minimal 3D point cloud and text data pairs. To address this task, we introduce GreenPLM, which leverages more text data to compensate for the lack of 3D data. First, inspired by using CLIP to align images and text, we utilize a pre-trained point cloud-text encoder to map the 3D point cloud space to the text space. This mapping leaves us to seamlessly connect the text space with LLMs. Once the point-text-LLM connection is established, we further enhance text-LLM alignment by expanding the intermediate text space, thereby reducing the reliance on 3D point cloud data. Specifically, we generate 6M free-text descriptions of 3D objects, and design a three-stage training strategy to help LLMs better explore the intrinsic connections between different modalities. To achieve efficient modality alignment, we design a zero-parameter cross-attention module for token pooling. Extensive experimental results show that GreenPLM requires only 12% of the 3D training data used by existing state-of-the-art models to achieve superior 3D understanding. Remarkably, GreenPLM also achieves competitive performance using text-only data. The code and weights are available at: https://github.com/TangYuan96/GreenPLM.
Building Intelligence Identification System via Large Language Model Watermarking: A Survey and Beyond
Jul 15, 2024



Large Large Language Models (LLMs) are increasingly integrated into diverse industries, posing substantial security risks due to unauthorized replication and misuse. To mitigate these concerns, robust identification mechanisms are widely acknowledged as an effective strategy. Identification systems for LLMs now rely heavily on watermarking technology to manage and protect intellectual property and ensure data security. However, previous studies have primarily concentrated on the basic principles of algorithms and lacked a comprehensive analysis of watermarking theory and practice from the perspective of intelligent identification. To bridge this gap, firstly, we explore how a robust identity recognition system can be effectively implemented and managed within LLMs by various participants using watermarking technology. Secondly, we propose a mathematical framework based on mutual information theory, which systematizes the identification process to achieve more precise and customized watermarking. Additionally, we present a comprehensive evaluation of performance metrics for LLM watermarking, reflecting participant preferences and advancing discussions on its identification applications. Lastly, we outline the existing challenges in current watermarking technologies and theoretical frameworks, and provide directional guidance to address these challenges. Our systematic classification and detailed exposition aim to enhance the comparison and evaluation of various methods, fostering further research and development toward a transparent, secure, and equitable LLM ecosystem.
PointDreamer: Zero-shot 3D Textured Mesh Reconstruction from Colored Point Cloud by 2D Inpainting
Jun 22, 2024Reconstructing textured meshes from colored point clouds is an important but challenging task in 3D graphics and vision. Most existing methods predict colors as implicit functions in 3D or UV space, suffering from blurry textures or the lack of generalization capability. Addressing this, we propose PointDreamer, a novel framework for textured mesh reconstruction from colored point cloud. It produces meshes with enhanced fidelity and clarity by 2D image inpainting, taking advantage of the mature techniques and massive data of 2D vision. Specifically, we first project the input point cloud into 2D space to generate sparse multi-view images, and then inpaint empty pixels utilizing a pre-trained 2D diffusion model. Next, we design a novel Non-Border-First strategy to unproject the colors of the inpainted dense images back to 3D space, thus obtaining the final textured mesh. In this way, our PointDreamer works in a zero-shot manner, requiring no extra training. Extensive qualitative and quantitative experiments on various synthetic and real-scanned datasets show the SoTA performance of PointDreamer, by significantly outperforming baseline methods with 30\% improvement in LPIPS score (from 0.118 to 0.068). Code at: https://github.com/YuQiao0303/PointDreamer.
Investigating Memory Failure Prediction Across CPU Architectures
Jun 08, 2024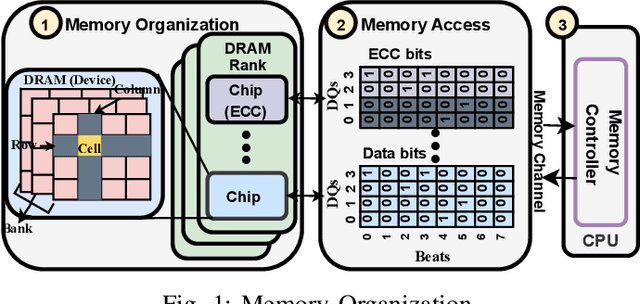
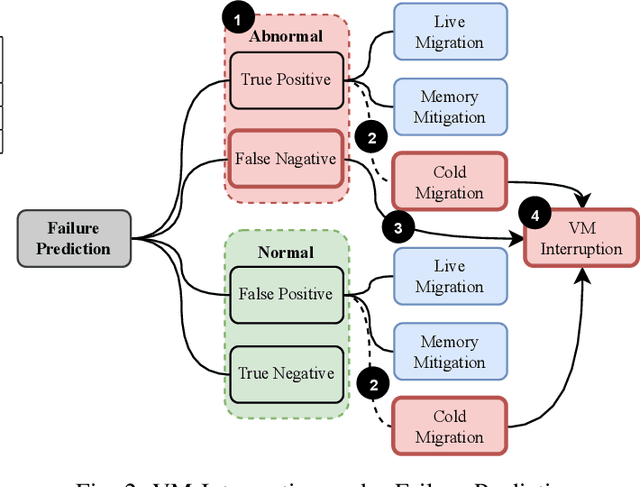
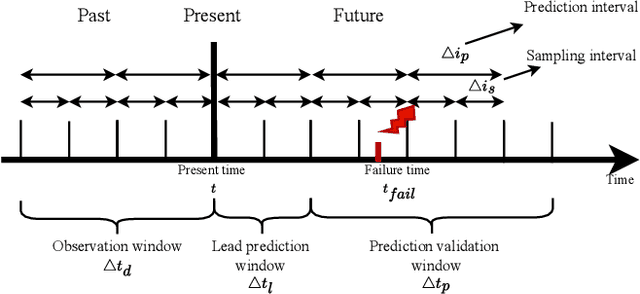
Large-scale datacenters often experience memory failures, where Uncorrectable Errors (UEs) highlight critical malfunction in Dual Inline Memory Modules (DIMMs). Existing approaches primarily utilize Correctable Errors (CEs) to predict UEs, yet they typically neglect how these errors vary between different CPU architectures, especially in terms of Error Correction Code (ECC) applicability. In this paper, we investigate the correlation between CEs and UEs across different CPU architectures, including X86 and ARM. Our analysis identifies unique patterns of memory failure associated with each processor platform. Leveraging Machine Learning (ML) techniques on production datasets, we conduct the memory failure prediction in different processors' platforms, achieving up to 15% improvements in F1-score compared to the existing algorithm. Finally, an MLOps (Machine Learning Operations) framework is provided to consistently improve the failure prediction in the production environment.
MiniGPT-3D: Efficiently Aligning 3D Point Clouds with Large Language Models using 2D Priors
May 02, 2024



Large 2D vision-language models (2D-LLMs) have gained significant attention by bridging Large Language Models (LLMs) with images using a simple projector. Inspired by their success, large 3D point cloud-language models (3D-LLMs) also integrate point clouds into LLMs. However, directly aligning point clouds with LLM requires expensive training costs, typically in hundreds of GPU-hours on A100, which hinders the development of 3D-LLMs. In this paper, we introduce MiniGPT-3D, an efficient and powerful 3D-LLM that achieves multiple SOTA results while training for only 27 hours on one RTX 3090. Specifically, we propose to align 3D point clouds with LLMs using 2D priors from 2D-LLMs, which can leverage the similarity between 2D and 3D visual information. We introduce a novel four-stage training strategy for modality alignment in a cascaded way, and a mixture of query experts module to adaptively aggregate features with high efficiency. Moreover, we utilize parameter-efficient fine-tuning methods LoRA and Norm fine-tuning, resulting in only 47.8M learnable parameters, which is up to 260x fewer than existing methods. Extensive experiments show that MiniGPT-3D achieves SOTA on 3D object classification and captioning tasks, with significantly cheaper training costs. Notably, MiniGPT-3D gains an 8.12 increase on GPT-4 evaluation score for the challenging object captioning task compared to ShapeLLM-13B, while the latter costs 160 total GPU-hours on 8 A800. We are the first to explore the efficient 3D-LLM, offering new insights to the community. Code and weights are available at https://github.com/TangYuan96/MiniGPT-3D.
Exploring Error Bits for Memory Failure Prediction: An In-Depth Correlative Study
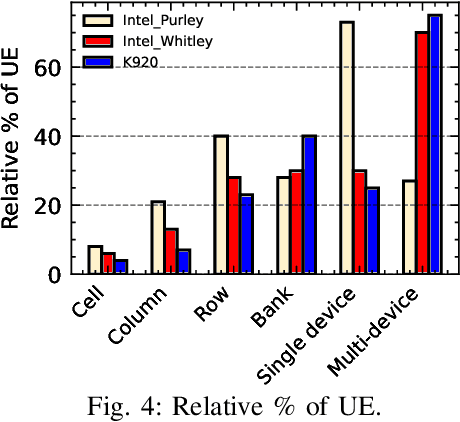
Dec 18, 2023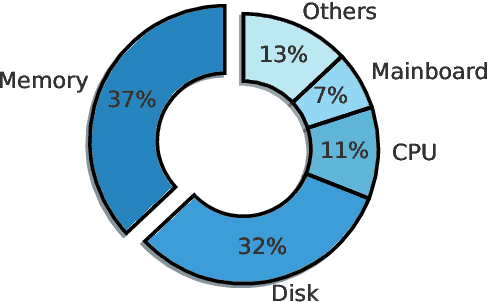
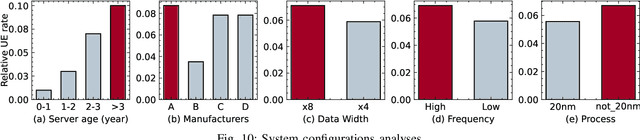
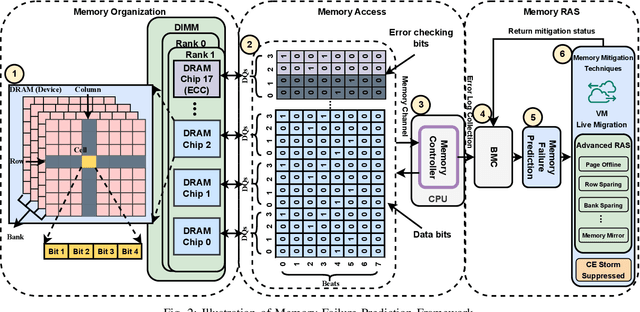
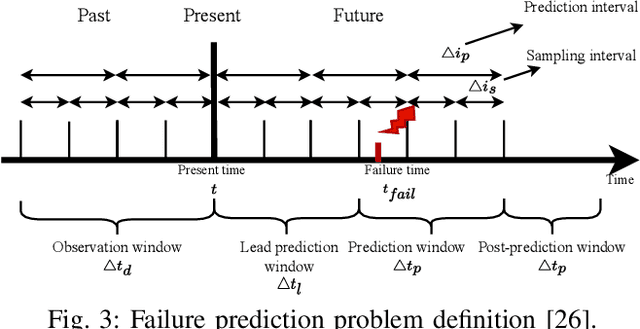
In large-scale datacenters, memory failure is a common cause of server crashes, with Uncorrectable Errors (UEs) being a major indicator of Dual Inline Memory Module (DIMM) defects. Existing approaches primarily focus on predicting UEs using Correctable Errors (CEs), without fully considering the information provided by error bits. However, error bit patterns have a strong correlation with the occurrence of UEs. In this paper, we present a comprehensive study on the correlation between CEs and UEs, specifically emphasizing the importance of spatio-temporal error bit information. Our analysis reveals a strong correlation between spatio-temporal error bits and UE occurrence. Through evaluations using real-world datasets, we demonstrate that our approach significantly improves prediction performance by 15% in F1-score compared to the state-of-the-art algorithms. Overall, our approach effectively reduces the number of virtual machine interruptions caused by UEs by approximately 59%.
* Published at ICCAD 2023
Mimic before Reconstruct: Enhancing Masked Autoencoders with Feature Mimicking
Mar 09, 2023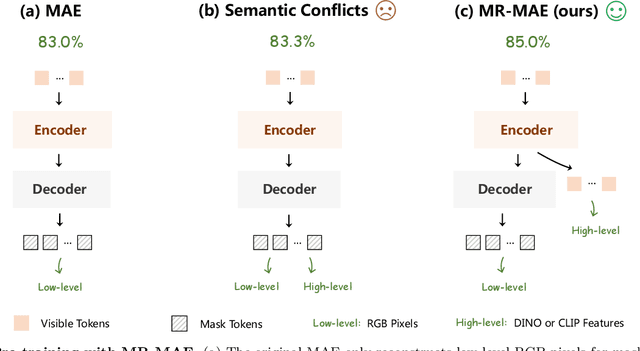
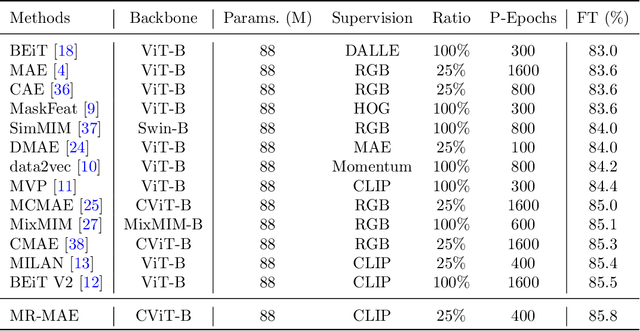
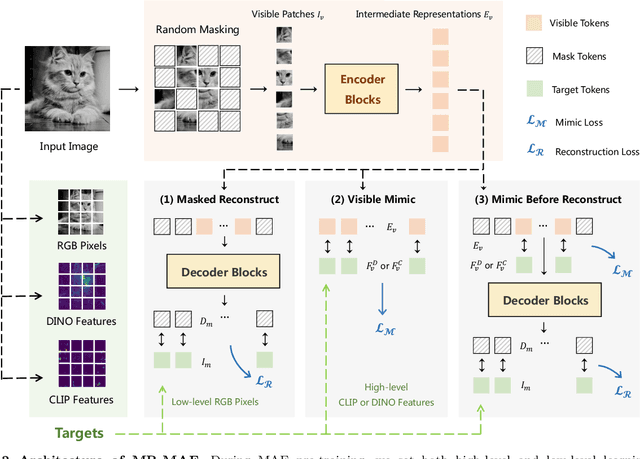
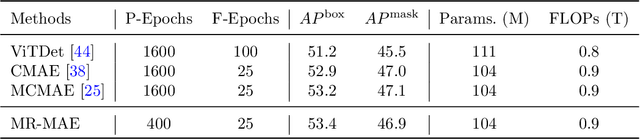
Masked Autoencoders (MAE) have been popular paradigms for large-scale vision representation pre-training. However, MAE solely reconstructs the low-level RGB signals after the decoder and lacks supervision upon high-level semantics for the encoder, thus suffering from sub-optimal learned representations and long pre-training epochs. To alleviate this, previous methods simply replace the pixel reconstruction targets of 75% masked tokens by encoded features from pre-trained image-image (DINO) or image-language (CLIP) contrastive learning. Different from those efforts, we propose to Mimic before Reconstruct for Masked Autoencoders, named as MR-MAE, which jointly learns high-level and low-level representations without interference during pre-training. For high-level semantics, MR-MAE employs a mimic loss over 25% visible tokens from the encoder to capture the pre-trained patterns encoded in CLIP and DINO. For low-level structures, we inherit the reconstruction loss in MAE to predict RGB pixel values for 75% masked tokens after the decoder. As MR-MAE applies high-level and low-level targets respectively at different partitions, the learning conflicts between them can be naturally overcome and contribute to superior visual representations for various downstream tasks. On ImageNet-1K, the MR-MAE base pre-trained for only 400 epochs achieves 85.8% top-1 accuracy after fine-tuning, surpassing the 1600-epoch MAE base by +2.2% and the previous state-of-the-art BEiT V2 base by +0.3%. Code and pre-trained models will be released at https://github.com/Alpha-VL/ConvMAE.
CasFusionNet: A Cascaded Network for Point Cloud Semantic Scene Completion by Dense Feature Fusion
Nov 24, 2022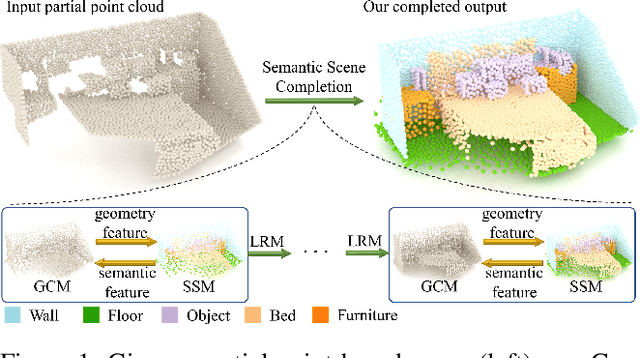
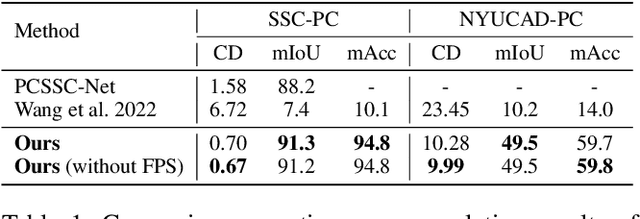
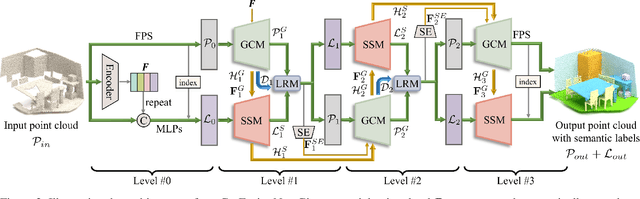
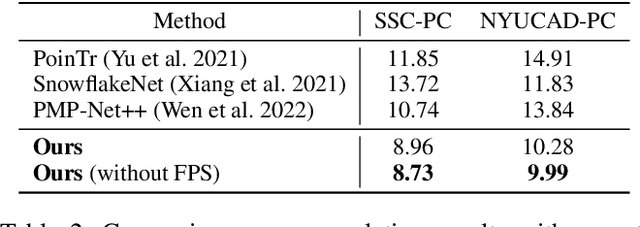
Semantic scene completion (SSC) aims to complete a partial 3D scene and predict its semantics simultaneously. Most existing works adopt the voxel representations, thus suffering from the growth of memory and computation cost as the voxel resolution increases. Though a few works attempt to solve SSC from the perspective of 3D point clouds, they have not fully exploited the correlation and complementarity between the two tasks of scene completion and semantic segmentation. In our work, we present CasFusionNet, a novel cascaded network for point cloud semantic scene completion by dense feature fusion. Specifically, we design (i) a global completion module (GCM) to produce an upsampled and completed but coarse point set, (ii) a semantic segmentation module (SSM) to predict the per-point semantic labels of the completed points generated by GCM, and (iii) a local refinement module (LRM) to further refine the coarse completed points and the associated labels from a local perspective. We organize the above three modules via dense feature fusion in each level, and cascade a total of four levels, where we also employ feature fusion between each level for sufficient information usage. Both quantitative and qualitative results on our compiled two point-based datasets validate the effectiveness and superiority of our CasFusionNet compared to state-of-the-art methods in terms of both scene completion and semantic segmentation. The codes and datasets are available at: https://github.com/JinfengX/CasFusionNet.