 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Gradient Staleness: Evaluating Distance Metrics for Asynchronous Federated Learning Aggregation
Mar 09, 2026In asynchronous federated learning (FL), client devices send updates to a central server at varying times based on their computational speed, often using stale versions of the global model. This staleness can degrade the convergence and accuracy of the global model. Previous work, such as AsyncFedED, proposed an adaptive aggregation method using Euclidean distance to measure staleness. In this paper, we extend this approach by exploring alternative distance metrics to more accurately capture the effect of gradient staleness. We integrate these metrics into the aggregation process and evaluate their impact on convergence speed, model performance, and training stability under heterogeneous clients and non-IID data settings. Our results demonstrate that certain metrics lead to more robust and efficient asynchronous FL training, offering a stronger foundation for practical deployment.
Monitoring Emergent Reward Hacking During Generation via Internal Activations
Mar 04, 2026Fine-tuned large language models can exhibit reward-hacking behavior arising from emergent misalignment, which is difficult to detect from final outputs alone. While prior work has studied reward hacking at the level of completed responses, it remains unclear whether such behavior can be identified during generation. We propose an activation-based monitoring approach that detects reward-hacking signals from internal representations as a model generates its response. Our method trains sparse autoencoders on residual stream activations and applies lightweight linear classifiers to produce token-level estimates of reward-hacking activity. Across multiple model families and fine-tuning mixtures, we find that internal activation patterns reliably distinguish reward-hacking from benign behavior, generalize to unseen mixed-policy adapters, and exhibit model-dependent temporal structure during chain-of-thought reasoning. Notably, reward-hacking signals often emerge early, persist throughout reasoning, and can be amplified by increased test-time compute in the form of chain-of-thought prompting under weakly specified reward objectives. These results suggest that internal activation monitoring provides a complementary and earlier signal of emergent misalignment than output-based evaluation, supporting more robust post-deployment safety monitoring for fine-tuned language models.
Noise-aware Client Selection for carbon-efficient Federated Learning via Gradient Norm Thresholding
Mar 04, 2026Training large-scale Neural Networks requires substantial computational power and energy. Federated Learning enables distributed model training across geospatially distributed data centers, leveraging renewable energy sources to reduce the carbon footprint of AI training. Various client selection strategies have been developed to align the volatility of renewable energy with stable and fair model training in a federated system. However, due to the privacy-preserving nature of Federated Learning, the quality of data on client devices remains unknown, posing challenges for effective model training. In this paper, we introduce a modular approach on top to state-of-the-art client selection strategies for carbon-efficient Federated Learning. Our method enhances robustness by incorporating a noisy client data filtering, improving both model performance and sustainability in scenarios with unknown data quality. Additionally, we explore the impact of carbon budgets on model convergence, balancing efficiency and sustainability. Through extensive evaluations, we demonstrate that modern client selection strategies based on local client loss tend to select clients with noisy data, ultimately degrading model performance. To address this, we propose a gradient norm thresholding mechanism using probing rounds for more effective client selection and noise detection, contributing to the practical deployment of carbon-efficient Federated Learning.
Distributed LLM Pretraining During Renewable Curtailment Windows: A Feasibility Study
Feb 26, 2026Training large language models (LLMs) requires substantial compute and energy. At the same time, renewable energy sources regularly produce more electricity than the grid can absorb, leading to curtailment, the deliberate reduction of clean generation that would otherwise go to waste. These periods represent an opportunity: if training is aligned with curtailment windows, LLMs can be pretrained using electricity that is both clean and cheap. This technical report presents a system that performs full-parameter LLM training across geo-distributed GPU clusters during regional curtailment windows, elastically switching between local single-site training and federated multi-site synchronization as sites become available or unavailable. Our prototype trains a 561M-parameter transformer model across three clusters using the Flower federated learning framework, with curtailment periods derived from real-world marginal carbon intensity traces. Preliminary results show that curtailment-aware scheduling preserves training quality while reducing operational emissions to 5-12% of single-site baselines.
Efficiency Will Not Lead to Sustainable Reasoning AI
Nov 19, 2025AI research is increasingly moving toward complex problem solving, where models are optimized not only for pattern recognition but for multi-step reasoning. Historically, computing's global energy footprint has been stabilized by sustained efficiency gains and natural saturation thresholds in demand. But as efficiency improvements are approaching physical limits, emerging reasoning AI lacks comparable saturation points: performance is no longer limited by the amount of available training data but continues to scale with exponential compute investments in both training and inference. This paper argues that efficiency alone will not lead to sustainable reasoning AI and discusses research and policy directions to embed explicit limits into the optimization and governance of such systems.
What happens when nanochat meets DiLoCo?
Nov 14, 2025Although LLM training is typically centralized with high-bandwidth interconnects and large compute budgets, emerging methods target communication-constrained training in distributed environments. The model trade-offs introduced by this shift remain underexplored, and our goal is to study them. We use the open-source nanochat project, a compact 8K-line full-stack ChatGPT-like implementation containing tokenization, pretraining, fine-tuning, and serving, as a controlled baseline. We implement the DiLoCo algorithm as a lightweight wrapper over nanochat's training loop, performing multiple local steps per worker before synchronization with an outer optimizer, effectively reducing communication by orders of magnitude. This inner-outer training is compared against a standard data-parallel (DDP) setup. Because nanochat is small and inspectable, it enables controlled pipeline adaptations and allows direct comparison with the conventional centralized baseline. DiLoCo achieves stable convergence and competitive loss in pretraining but yields worse MMLU, GSM8K, and HumanEval scores after mid-training and SFT. We discover that using DiLoCo-pretrained weights and running mid- and post-training with DDP fails to recover performance, revealing irreversible representation drift from asynchronous updates that impairs downstream alignment. We provide this implementation as an official fork of nanochat on GitHub.
Informed Mixing -- Improving Open Set Recognition via Attribution-based Augmentation
May 19, 2025Open set recognition (OSR) is devised to address the problem of detecting novel classes during model inference. Even in recent vision models, this remains an open issue which is receiving increasing attention. Thereby, a crucial challenge is to learn features that are relevant for unseen categories from given data, for which these features might not be discriminative. To facilitate this process and "optimize to learn" more diverse features, we propose GradMix, a data augmentation method that dynamically leverages gradient-based attribution maps of the model during training to mask out already learned concepts. Thus GradMix encourages the model to learn a more complete set of representative features from the same data source. Extensive experiments on open set recognition, close set classification, and out-of-distribution detection reveal that our method can often outperform the state-of-the-art. GradMix can further increase model robustness to corruptions as well as downstream classification performance for self-supervised learning, indicating its benefit for model generalization.
Towards Machine-Generated Code for the Resolution of User Intentions
Apr 24, 2025The growing capabilities of Artificial Intelligence (AI), particularly Large Language Models (LLMs), prompt a reassessment of the interaction mechanisms between users and their devices. Currently, users are required to use a set of high-level applications to achieve their desired results. However, the advent of AI may signal a shift in this regard, as its capabilities have generated novel prospects for user-provided intent resolution through the deployment of model-generated code, which is tantamount to the generation of workflows comprising a multitude of interdependent steps. This development represents a significant progression in the realm of hybrid workflows, where human and artificial intelligence collaborate to address user intentions, with the former responsible for defining these intentions and the latter for implementing the solutions to address them. In this paper, we investigate the feasibility of generating and executing workflows through code generation that results from prompting an LLM with a concrete user intention, such as \emph{Please send my car title to my insurance company}, and a simplified application programming interface for a GUI-less operating system. We provide in-depth analysis and comparison of various user intentions, the resulting code, and its execution. The findings demonstrate a general feasibility of our approach and that the employed LLM, GPT-4o-mini, exhibits remarkable proficiency in the generation of code-oriented workflows in accordance with provided user intentions.
$β$-GNN: A Robust Ensemble Approach Against Graph Structure Perturbation
Mar 26, 2025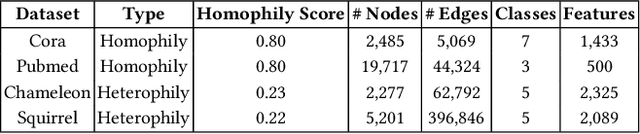
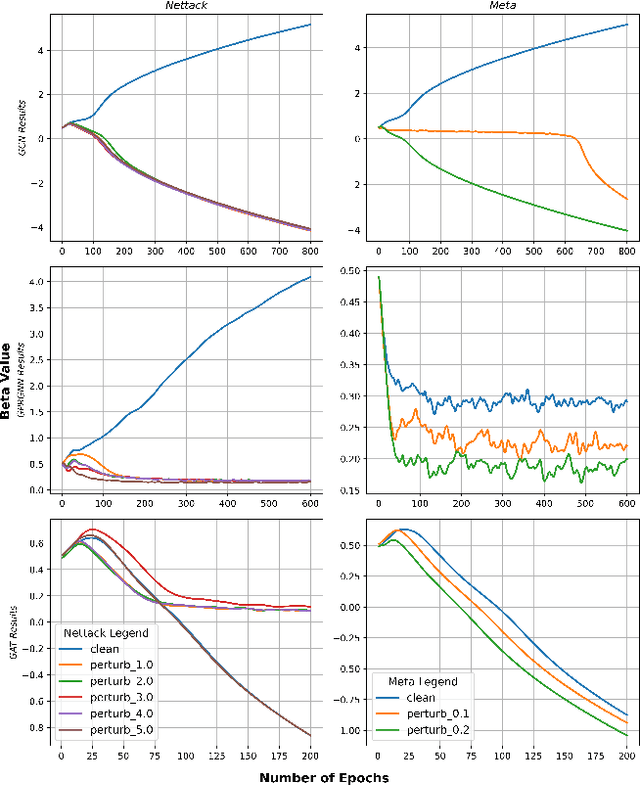
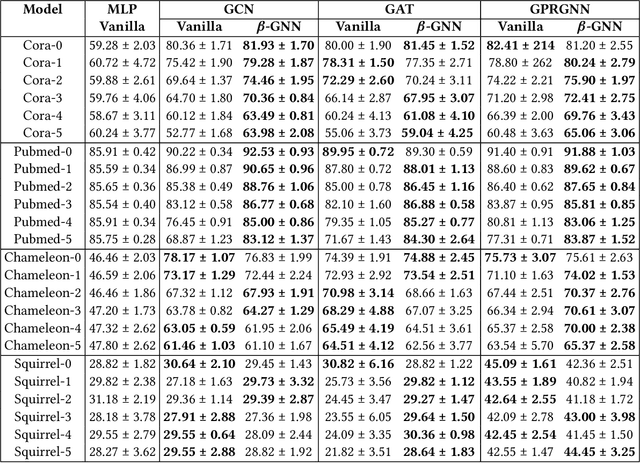
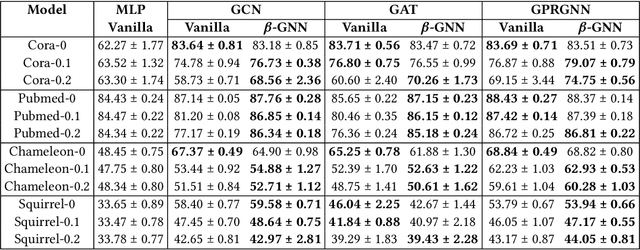
Graph Neural Networks (GNNs) are playing an increasingly important role in the efficient operation and security of computing systems, with applications in workload scheduling, anomaly detection, and resource management. However, their vulnerability to network perturbations poses a significant challenge. We propose $\beta$-GNN, a model enhancing GNN robustness without sacrificing clean data performance. $\beta$-GNN uses a weighted ensemble, combining any GNN with a multi-layer perceptron. A learned dynamic weight, $\beta$, modulates the GNN's contribution. This $\beta$ not only weights GNN influence but also indicates data perturbation levels, enabling proactive mitigation. Experimental results on diverse datasets show $\beta$-GNN's superior adversarial accuracy and attack severity quantification. Crucially, $\beta$-GNN avoids perturbation assumptions, preserving clean data structure and performance.
Investigating Memory Failure Prediction Across CPU Architectures
Jun 08, 2024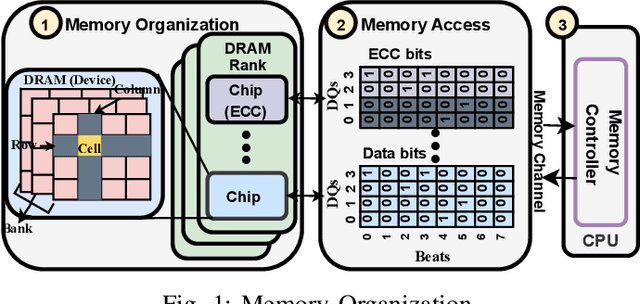
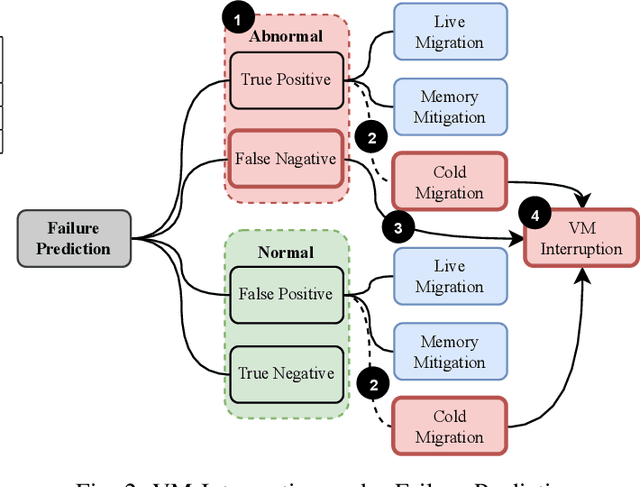
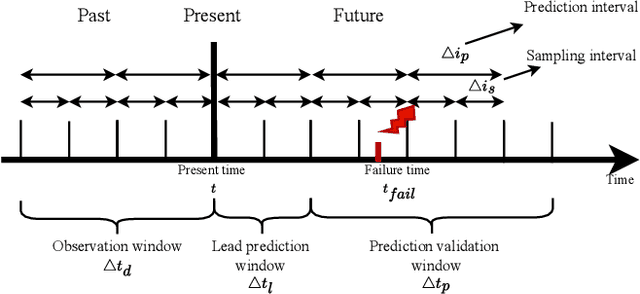
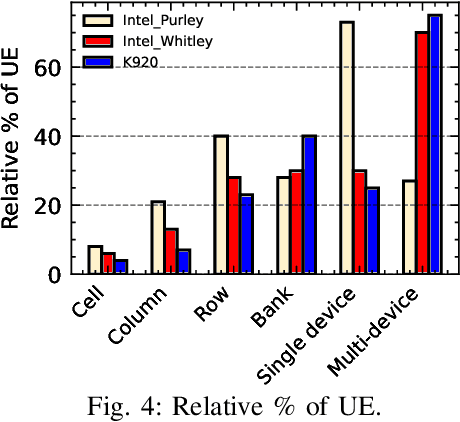
Large-scale datacenters often experience memory failures, where Uncorrectable Errors (UEs) highlight critical malfunction in Dual Inline Memory Modules (DIMMs). Existing approaches primarily utilize Correctable Errors (CEs) to predict UEs, yet they typically neglect how these errors vary between different CPU architectures, especially in terms of Error Correction Code (ECC) applicability. In this paper, we investigate the correlation between CEs and UEs across different CPU architectures, including X86 and ARM. Our analysis identifies unique patterns of memory failure associated with each processor platform. Leveraging Machine Learning (ML) techniques on production datasets, we conduct the memory failure prediction in different processors' platforms, achieving up to 15% improvements in F1-score compared to the existing algorithm. Finally, an MLOps (Machine Learning Operations) framework is provided to consistently improve the failure prediction in the production environment.