 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolution Simplex Clustering for Heterogeneous Federated Learning
Mar 05, 2024We tackle a major challenge in federated learning (FL) -- achieving good performance under highly heterogeneous client distributions. The difficulty partially arises from two seemingly contradictory goals: learning a common model by aggregating the information from clients, and learning local personalized models that should be adapted to each local distribution. In this work, we propose Solution Simplex Clustered Federated Learning (SosicFL) for dissolving such contradiction. Based on the recent ideas of learning solution simplices, SosicFL assigns a subregion in a simplex to each client, and performs FL to learn a common solution simplex. This allows the client models to possess their characteristics within the degrees of freedom in the solution simplex, and at the same time achieves the goal of learning a global common model. Our experiments show that SosicFL improves the performance and accelerates the training process for global and personalized FL with minimal computational overhead.
FedZero: Leveraging Renewable Excess Energy in Federated Learning
May 24, 2023Federated Learning (FL) is an emerging machine learning technique that enables distributed model training across data silos or edge devices without data sharing. Yet, FL inevitably introduces inefficiencies compared to centralized model training, which will further increase the already high energy usage and associated carbon emissions of machine learning in the future. Although the scheduling of workloads based on the availability of low-carbon energy has received considerable attention in recent years, it has not yet been investigated in the context of FL. However, FL is a highly promising use case for carbon-aware computing, as training jobs constitute of energy-intensive batch processes scheduled in geo-distributed environments. We propose FedZero, a FL system that operates exclusively on renewable excess energy and spare capacity of compute infrastructure to effectively reduce the training's operational carbon emissions to zero. Based on energy and load forecasts, FedZero leverages the spatio-temporal availability of excess energy by cherry-picking clients for fast convergence and fair participation. Our evaluation, based on real solar and load traces, shows that FedZero converges considerably faster under the mentioned constraints than state-of-the-art approaches, is highly scalable, and is robust against forecasting errors.
DORA: Exploring outlier representations in Deep Neural Networks
Jun 09, 2022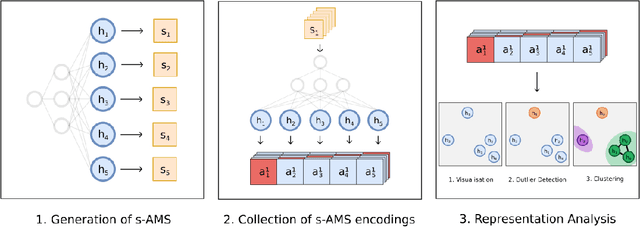
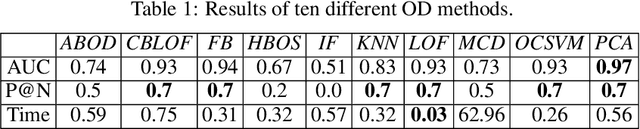
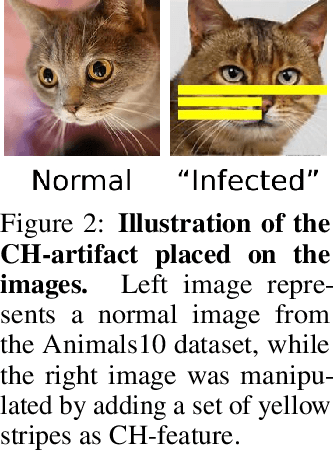
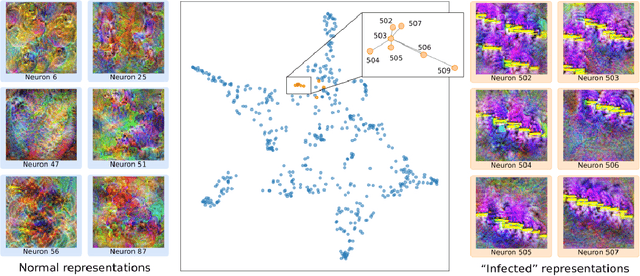
Deep Neural Networks (DNNs) draw their power from the representations they learn. In recent years, however, researchers have found that DNNs, while being incredibly effective in learning complex abstractions, also tend to be infected with artifacts, such as biases, Clever Hanses (CH), or Backdoors, due to spurious correlations inherent in the training data. So far, existing methods for uncovering such artifactual and malicious behavior in trained models focus on finding artifacts in the input data, which requires both availabilities of a data set and human intervention. In this paper, we introduce DORA (Data-agnOstic Representation Analysis): the first automatic data-agnostic method for the detection of potentially infected representations in Deep Neural Networks. We further show that contaminated representations found by DORA can be used to detect infected samples in any given dataset. We qualitatively and quantitatively evaluate the performance of our proposed method in both, controlled toy scenarios, and in real-world settings, where we demonstrate the benefit of DORA in safety-critical applications.
Visualizing the diversity of representations learned by Bayesian neural networks
Jan 26, 2022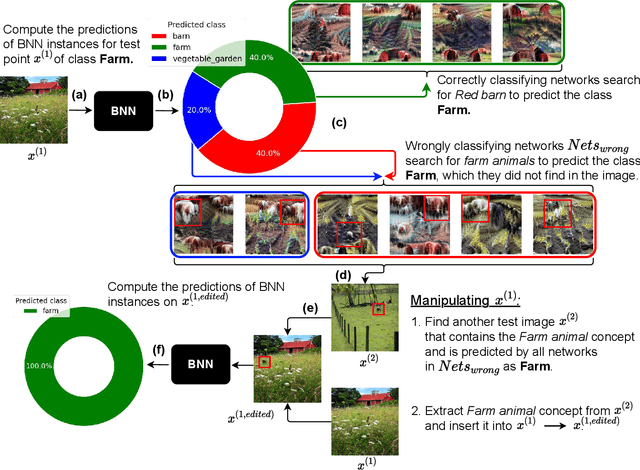
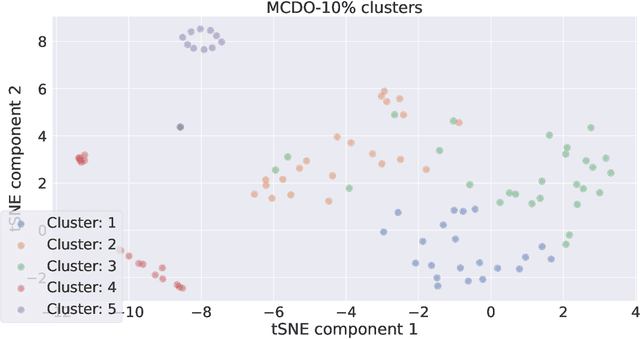


Explainable artificial intelligence (XAI) aims to make learning machines less opaque, and offers researchers and practitioners various tools to reveal the decision-making strategies of neural networks. In this work, we investigate how XAI methods can be used for exploring and visualizing the diversity of feature representations learned by Bayesian neural networks (BNNs). Our goal is to provide a global understanding of BNNs by making their decision-making strategies a) visible and tangible through feature visualizations and b) quantitatively measurable with a distance measure learned by contrastive learning. Our work provides new insights into the posterior distribution in terms of human-understandable feature information with regard to the underlying decision-making strategies. Our main findings are the following: 1) global XAI methods can be applied to explain the diversity of decision-making strategies of BNN instances, 2) Monte Carlo dropout exhibits increased diversity in feature representations compared to the multimodal posterior approximation of MultiSWAG, 3) the diversity of learned feature representations highly correlates with the uncertainty estimates, and 4) the inter-mode diversity of the multimodal posterior decreases as the network width increases, while the intra-mode diversity increases. Our findings are consistent with the recent deep neural networks theory, providing additional intuitions about what the theory implies in terms of humanly understandable concepts.