 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Silent Data Corruption as a Reliability Challenge in LLM Training
Apr 01, 2026As Large Language Models (LLMs) scale in size and complexity, the consequences of failures during training become increasingly severe. A major challenge arises from Silent Data Corruption (SDC): hardware-induced faults that bypass system-level detection mechanisms. SDC may behave like benign numerical noise, but can also cause harmful gradient corruption that leads to loss spikes, divergence, or stalled progress. This work provides a controlled study of how intermittent SDC affects LLM pretraining. Using targeted fault injection at the level of GPU matrix-multiply instructions, we characterize the sensitivity of different bit positions, kernel functions, and execution stages. Our analysis shows that locally originating faults can produce impactful corruption, including NaN propagation, short-lived spikes in loss, gradient norm, and attention logits, as well as persistent parameter divergence. Building on the observed corruption signatures, we propose a lightweight detection method that identifies potentially harmful parameter updates. Experiments on LLaMA models with 60M, 350M, and 1.3B parameters demonstrate that recomputing the most recent training step upon detection can effectively mitigate the impact of these events.
Distributed LLM Pretraining During Renewable Curtailment Windows: A Feasibility Study
Feb 26, 2026Training large language models (LLMs) requires substantial compute and energy. At the same time, renewable energy sources regularly produce more electricity than the grid can absorb, leading to curtailment, the deliberate reduction of clean generation that would otherwise go to waste. These periods represent an opportunity: if training is aligned with curtailment windows, LLMs can be pretrained using electricity that is both clean and cheap. This technical report presents a system that performs full-parameter LLM training across geo-distributed GPU clusters during regional curtailment windows, elastically switching between local single-site training and federated multi-site synchronization as sites become available or unavailable. Our prototype trains a 561M-parameter transformer model across three clusters using the Flower federated learning framework, with curtailment periods derived from real-world marginal carbon intensity traces. Preliminary results show that curtailment-aware scheduling preserves training quality while reducing operational emissions to 5-12% of single-site baselines.
Efficiency Will Not Lead to Sustainable Reasoning AI
Nov 19, 2025AI research is increasingly moving toward complex problem solving, where models are optimized not only for pattern recognition but for multi-step reasoning. Historically, computing's global energy footprint has been stabilized by sustained efficiency gains and natural saturation thresholds in demand. But as efficiency improvements are approaching physical limits, emerging reasoning AI lacks comparable saturation points: performance is no longer limited by the amount of available training data but continues to scale with exponential compute investments in both training and inference. This paper argues that efficiency alone will not lead to sustainable reasoning AI and discusses research and policy directions to embed explicit limits into the optimization and governance of such systems.
What happens when nanochat meets DiLoCo?
Nov 14, 2025Although LLM training is typically centralized with high-bandwidth interconnects and large compute budgets, emerging methods target communication-constrained training in distributed environments. The model trade-offs introduced by this shift remain underexplored, and our goal is to study them. We use the open-source nanochat project, a compact 8K-line full-stack ChatGPT-like implementation containing tokenization, pretraining, fine-tuning, and serving, as a controlled baseline. We implement the DiLoCo algorithm as a lightweight wrapper over nanochat's training loop, performing multiple local steps per worker before synchronization with an outer optimizer, effectively reducing communication by orders of magnitude. This inner-outer training is compared against a standard data-parallel (DDP) setup. Because nanochat is small and inspectable, it enables controlled pipeline adaptations and allows direct comparison with the conventional centralized baseline. DiLoCo achieves stable convergence and competitive loss in pretraining but yields worse MMLU, GSM8K, and HumanEval scores after mid-training and SFT. We discover that using DiLoCo-pretrained weights and running mid- and post-training with DDP fails to recover performance, revealing irreversible representation drift from asynchronous updates that impairs downstream alignment. We provide this implementation as an official fork of nanochat on GitHub.
$β$-GNN: A Robust Ensemble Approach Against Graph Structure Perturbation
Mar 26, 2025
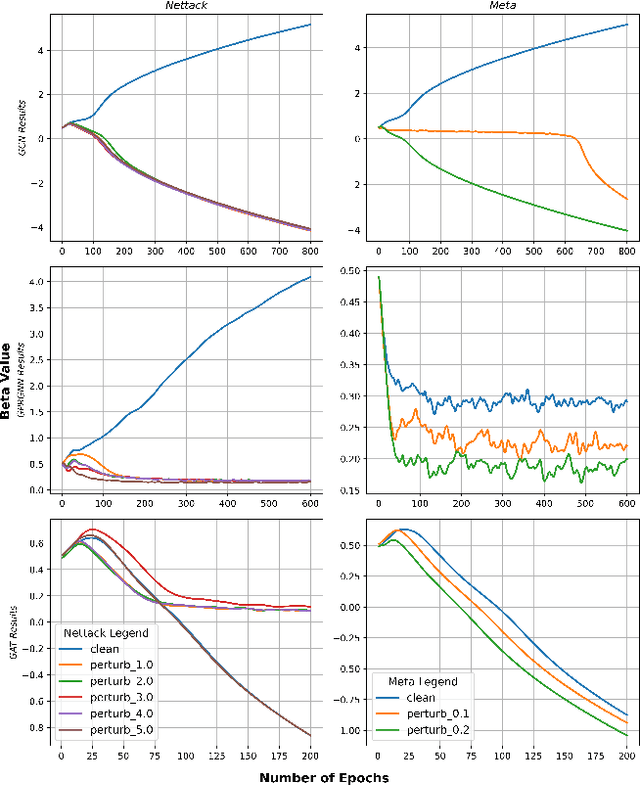
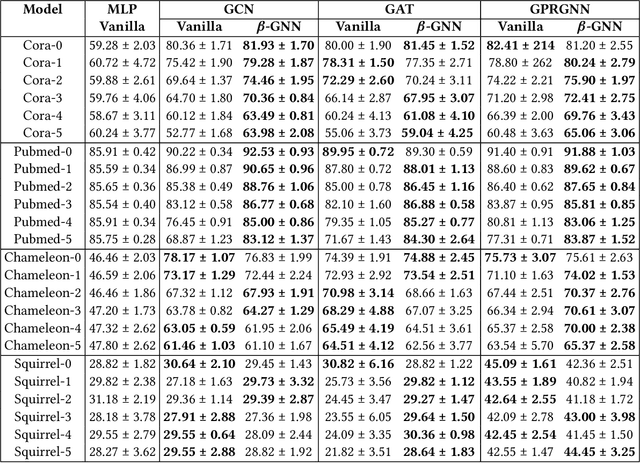
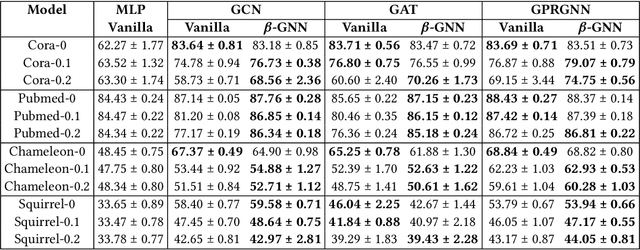
Graph Neural Networks (GNNs) are playing an increasingly important role in the efficient operation and security of computing systems, with applications in workload scheduling, anomaly detection, and resource management. However, their vulnerability to network perturbations poses a significant challenge. We propose $\beta$-GNN, a model enhancing GNN robustness without sacrificing clean data performance. $\beta$-GNN uses a weighted ensemble, combining any GNN with a multi-layer perceptron. A learned dynamic weight, $\beta$, modulates the GNN's contribution. This $\beta$ not only weights GNN influence but also indicates data perturbation levels, enabling proactive mitigation. Experimental results on diverse datasets show $\beta$-GNN's superior adversarial accuracy and attack severity quantification. Crucially, $\beta$-GNN avoids perturbation assumptions, preserving clean data structure and performance.
LogRCA: Log-based Root Cause Analysis for Distributed Services
May 22, 2024To assist IT service developers and operators in managing their increasingly complex service landscapes, there is a growing effort to leverage artificial intelligence in operations. To speed up troubleshooting, log anomaly detection has received much attention in particular, dealing with the identification of log events that indicate the reasons for a system failure. However, faults often propagate extensively within systems, which can result in a large number of anomalies being detected by existing approaches. In this case, it can remain very challenging for users to quickly identify the actual root cause of a failure. We propose LogRCA, a novel method for identifying a minimal set of log lines that together describe a root cause. LogRCA uses a semi-supervised learning approach to deal with rare and unknown errors and is designed to handle noisy data. We evaluated our approach on a large-scale production log data set of 44.3 million log lines, which contains 80 failures, whose root causes were labeled by experts. LogRCA consistently outperforms baselines based on deep learning and statistical analysis in terms of precision and recall to detect candidate root causes. In addition, we investigated the impact of our deployed data balancing approach, demonstrating that it considerably improves performance on rare failures.
Solution Simplex Clustering for Heterogeneous Federated Learning
Mar 05, 2024We tackle a major challenge in federated learning (FL) -- achieving good performance under highly heterogeneous client distributions. The difficulty partially arises from two seemingly contradictory goals: learning a common model by aggregating the information from clients, and learning local personalized models that should be adapted to each local distribution. In this work, we propose Solution Simplex Clustered Federated Learning (SosicFL) for dissolving such contradiction. Based on the recent ideas of learning solution simplices, SosicFL assigns a subregion in a simplex to each client, and performs FL to learn a common solution simplex. This allows the client models to possess their characteristics within the degrees of freedom in the solution simplex, and at the same time achieves the goal of learning a global common model. Our experiments show that SosicFL improves the performance and accelerates the training process for global and personalized FL with minimal computational overhead.
Karasu: A Collaborative Approach to Efficient Cluster Configuration for Big Data Analytics
Aug 22, 2023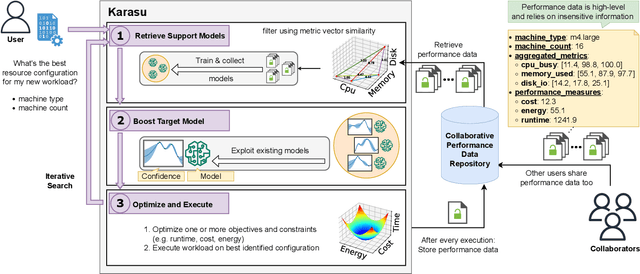
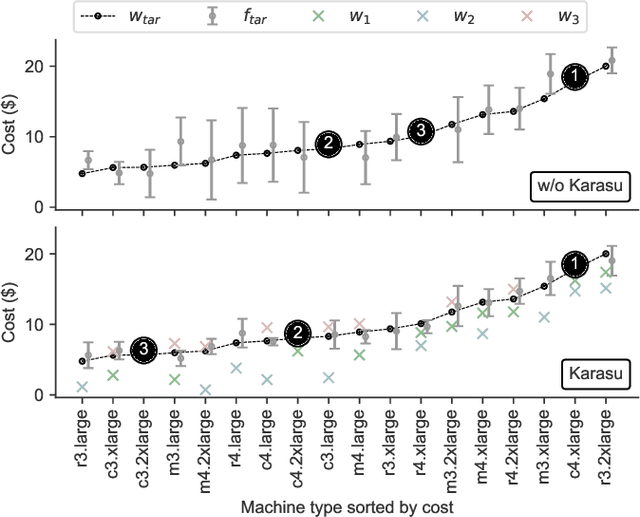
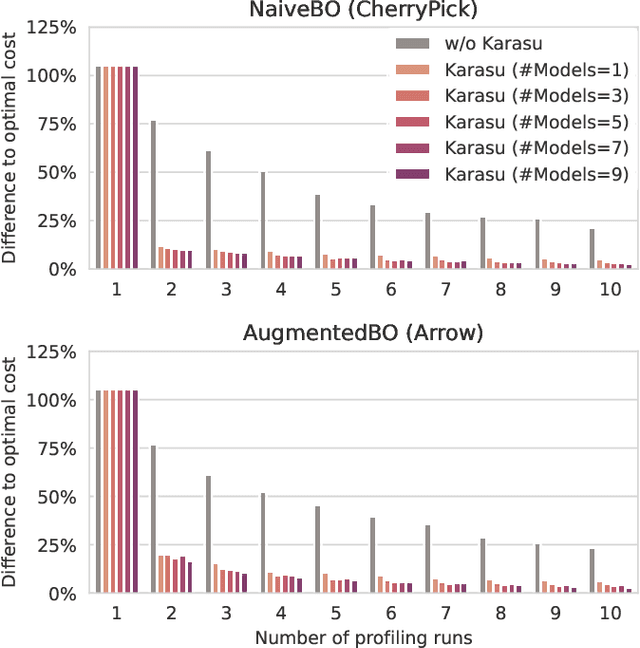
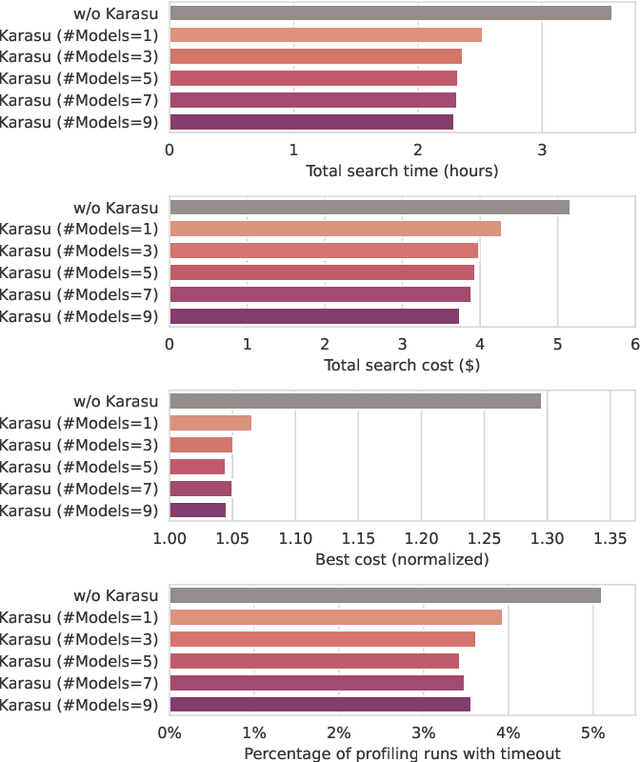
Selecting the right resources for big data analytics jobs is hard because of the wide variety of configuration options like machine type and cluster size. As poor choices can have a significant impact on resource efficiency, cost, and energy usage, automated approaches are gaining popularity. Most existing methods rely on profiling recurring workloads to find near-optimal solutions over time. Due to the cold-start problem, this often leads to lengthy and costly profiling phases. However, big data analytics jobs across users can share many common properties: they often operate on similar infrastructure, using similar algorithms implemented in similar frameworks. The potential in sharing aggregated profiling runs to collaboratively address the cold start problem is largely unexplored. We present Karasu, an approach to more efficient resource configuration profiling that promotes data sharing among users working with similar infrastructures, frameworks, algorithms, or datasets. Karasu trains lightweight performance models using aggregated runtime information of collaborators and combines them into an ensemble method to exploit inherent knowledge of the configuration search space. Moreover, Karasu allows the optimization of multiple objectives simultaneously. Our evaluation is based on performance data from diverse workload executions in a public cloud environment. We show that Karasu is able to significantly boost existing methods in terms of performance, search time, and cost, even when few comparable profiling runs are available that share only partial common characteristics with the target job.
FedZero: Leveraging Renewable Excess Energy in Federated Learning
May 24, 2023Federated Learning (FL) is an emerging machine learning technique that enables distributed model training across data silos or edge devices without data sharing. Yet, FL inevitably introduces inefficiencies compared to centralized model training, which will further increase the already high energy usage and associated carbon emissions of machine learning in the future. Although the scheduling of workloads based on the availability of low-carbon energy has received considerable attention in recent years, it has not yet been investigated in the context of FL. However, FL is a highly promising use case for carbon-aware computing, as training jobs constitute of energy-intensive batch processes scheduled in geo-distributed environments. We propose FedZero, a FL system that operates exclusively on renewable excess energy and spare capacity of compute infrastructure to effectively reduce the training's operational carbon emissions to zero. Based on energy and load forecasts, FedZero leverages the spatio-temporal availability of excess energy by cherry-picking clients for fast convergence and fair participation. Our evaluation, based on real solar and load traces, shows that FedZero converges considerably faster under the mentioned constraints than state-of-the-art approaches, is highly scalable, and is robust against forecasting errors.
PULL: Reactive Log Anomaly Detection Based On Iterative PU Learning
Jan 25, 2023Due to the complexity of modern IT services, failures can be manifold, occur at any stage, and are hard to detect. For this reason, anomaly detection applied to monitoring data such as logs allows gaining relevant insights to improve IT services steadily and eradicate failures. However, existing anomaly detection methods that provide high accuracy often rely on labeled training data, which are time-consuming to obtain in practice. Therefore, we propose PULL, an iterative log analysis method for reactive anomaly detection based on estimated failure time windows provided by monitoring systems instead of labeled data. Our attention-based model uses a novel objective function for weak supervision deep learning that accounts for imbalanced data and applies an iterative learning strategy for positive and unknown samples (PU learning) to identify anomalous logs. Our evaluation shows that PULL consistently outperforms ten benchmark baselines across three different datasets and detects anomalous log messages with an F1-score of more than 0.99 even within imprecise failure time windows.