 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed LLM Pretraining During Renewable Curtailment Windows: A Feasibility Study
Feb 26, 2026Training large language models (LLMs) requires substantial compute and energy. At the same time, renewable energy sources regularly produce more electricity than the grid can absorb, leading to curtailment, the deliberate reduction of clean generation that would otherwise go to waste. These periods represent an opportunity: if training is aligned with curtailment windows, LLMs can be pretrained using electricity that is both clean and cheap. This technical report presents a system that performs full-parameter LLM training across geo-distributed GPU clusters during regional curtailment windows, elastically switching between local single-site training and federated multi-site synchronization as sites become available or unavailable. Our prototype trains a 561M-parameter transformer model across three clusters using the Flower federated learning framework, with curtailment periods derived from real-world marginal carbon intensity traces. Preliminary results show that curtailment-aware scheduling preserves training quality while reducing operational emissions to 5-12% of single-site baselines.
What happens when nanochat meets DiLoCo?
Nov 14, 2025Although LLM training is typically centralized with high-bandwidth interconnects and large compute budgets, emerging methods target communication-constrained training in distributed environments. The model trade-offs introduced by this shift remain underexplored, and our goal is to study them. We use the open-source nanochat project, a compact 8K-line full-stack ChatGPT-like implementation containing tokenization, pretraining, fine-tuning, and serving, as a controlled baseline. We implement the DiLoCo algorithm as a lightweight wrapper over nanochat's training loop, performing multiple local steps per worker before synchronization with an outer optimizer, effectively reducing communication by orders of magnitude. This inner-outer training is compared against a standard data-parallel (DDP) setup. Because nanochat is small and inspectable, it enables controlled pipeline adaptations and allows direct comparison with the conventional centralized baseline. DiLoCo achieves stable convergence and competitive loss in pretraining but yields worse MMLU, GSM8K, and HumanEval scores after mid-training and SFT. We discover that using DiLoCo-pretrained weights and running mid- and post-training with DDP fails to recover performance, revealing irreversible representation drift from asynchronous updates that impairs downstream alignment. We provide this implementation as an official fork of nanochat on GitHub.
Progressing from Anomaly Detection to Automated Log Labeling and Pioneering Root Cause Analysis
Dec 22, 2023The realm of AIOps is transforming IT landscapes with the power of AI and ML. Despite the challenge of limited labeled data, supervised models show promise, emphasizing the importance of leveraging labels for training, especially in deep learning contexts. This study enhances the field by introducing a taxonomy for log anomalies and exploring automated data labeling to mitigate labeling challenges. It goes further by investigating the potential of diverse anomaly detection techniques and their alignment with specific anomaly types. However, the exploration doesn't stop at anomaly detection. The study envisions a future where root cause analysis follows anomaly detection, unraveling the underlying triggers of anomalies. This uncharted territory holds immense potential for revolutionizing IT systems management. In essence, this paper enriches our understanding of anomaly detection, and automated labeling, and sets the stage for transformative root cause analysis. Together, these advances promise more resilient IT systems, elevating operational efficiency and user satisfaction in an ever-evolving technological landscape.
PULL: Reactive Log Anomaly Detection Based On Iterative PU Learning
Jan 25, 2023Due to the complexity of modern IT services, failures can be manifold, occur at any stage, and are hard to detect. For this reason, anomaly detection applied to monitoring data such as logs allows gaining relevant insights to improve IT services steadily and eradicate failures. However, existing anomaly detection methods that provide high accuracy often rely on labeled training data, which are time-consuming to obtain in practice. Therefore, we propose PULL, an iterative log analysis method for reactive anomaly detection based on estimated failure time windows provided by monitoring systems instead of labeled data. Our attention-based model uses a novel objective function for weak supervision deep learning that accounts for imbalanced data and applies an iterative learning strategy for positive and unknown samples (PU learning) to identify anomalous logs. Our evaluation shows that PULL consistently outperforms ten benchmark baselines across three different datasets and detects anomalous log messages with an F1-score of more than 0.99 even within imprecise failure time windows.
Data-Driven Approach for Log Instruction Quality Assessment
Apr 06, 2022
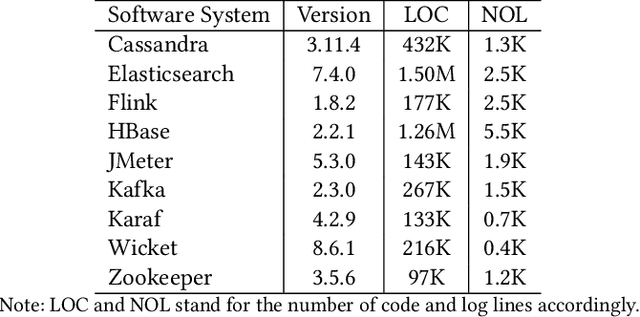

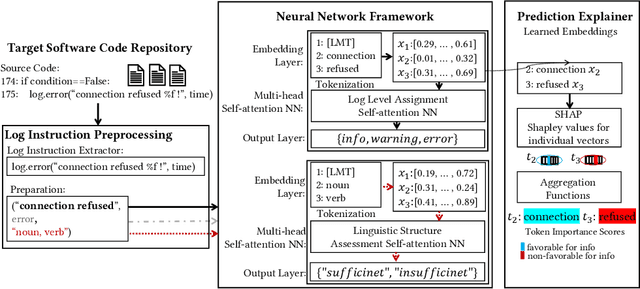
In the current IT world, developers write code while system operators run the code mostly as a black box. The connection between both worlds is typically established with log messages: the developer provides hints to the (unknown) operator, where the cause of an occurred issue is, and vice versa, the operator can report bugs during operation. To fulfil this purpose, developers write log instructions that are structured text commonly composed of a log level (e.g., "info", "error"), static text ("IP {} cannot be reached"), and dynamic variables (e.g. IP {}). However, as opposed to well-adopted coding practices, there are no widely adopted guidelines on how to write log instructions with good quality properties. For example, a developer may assign a high log level (e.g., "error") for a trivial event that can confuse the operator and increase maintenance costs. Or the static text can be insufficient to hint at a specific issue. In this paper, we address the problem of log quality assessment and provide the first step towards its automation. We start with an in-depth analysis of quality log instruction properties in nine software systems and identify two quality properties: 1) correct log level assignment assessing the correctness of the log level, and 2) sufficient linguistic structure assessing the minimal richness of the static text necessary for verbose event description. Based on these findings, we developed a data-driven approach that adapts deep learning methods for each of the two properties. An extensive evaluation on large-scale open-source systems shows that our approach correctly assesses log level assignments with an accuracy of 0.88, and the sufficient linguistic structure with an F1 score of 0.99, outperforming the baselines. Our study shows the potential of the data-driven methods in assessing instructions quality and aid developers in comprehending and writing better code.
LogLAB: Attention-Based Labeling of Log Data Anomalies via Weak Supervision
Nov 25, 2021With increasing scale and complexity of cloud operations, automated detection of anomalies in monitoring data such as logs will be an essential part of managing future IT infrastructures. However, many methods based on artificial intelligence, such as supervised deep learning models, require large amounts of labeled training data to perform well. In practice, this data is rarely available because labeling log data is expensive, time-consuming, and requires a deep understanding of the underlying system. We present LogLAB, a novel modeling approach for automated labeling of log messages without requiring manual work by experts. Our method relies on estimated failure time windows provided by monitoring systems to produce precise labeled datasets in retrospect. It is based on the attention mechanism and uses a custom objective function for weak supervision deep learning techniques that accounts for imbalanced data. Our evaluation shows that LogLAB consistently outperforms nine benchmark approaches across three different datasets and maintains an F1-score of more than 0.98 even at large failure time windows.
* Paper accepted on ICSOC 2021 and published on springer
A2Log: Attentive Augmented Log Anomaly Detection
Sep 20, 2021Anomaly detection becomes increasingly important for the dependability and serviceability of IT services. As log lines record events during the execution of IT services, they are a primary source for diagnostics. Thereby, unsupervised methods provide a significant benefit since not all anomalies can be known at training time. Existing unsupervised methods need anomaly examples to obtain a suitable decision boundary required for the anomaly detection task. This requirement poses practical limitations. Therefore, we develop A2Log, which is an unsupervised anomaly detection method consisting of two steps: Anomaly scoring and anomaly decision. First, we utilize a self-attention neural network to perform the scoring for each log message. Second, we set the decision boundary based on data augmentation of the available normal training data. The method is evaluated on three publicly available datasets and one industry dataset. We show that our approach outperforms existing methods. Furthermore, we utilize available anomaly examples to set optimal decision boundaries to acquire strong baselines. We show that our approach, which determines decision boundaries without utilizing anomaly examples, can reach scores of the strong baselines.
Enel: Context-Aware Dynamic Scaling of Distributed Dataflow Jobs using Graph Propagation
Aug 27, 2021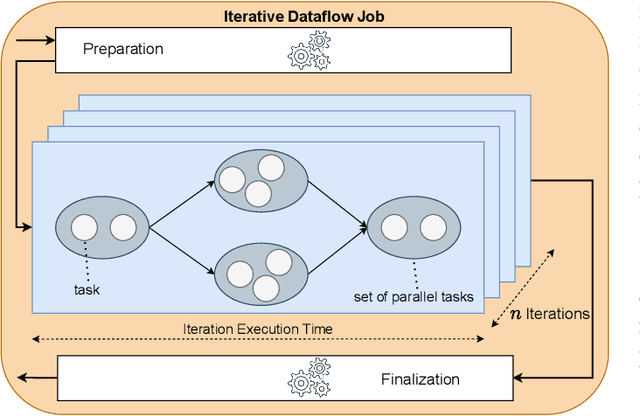

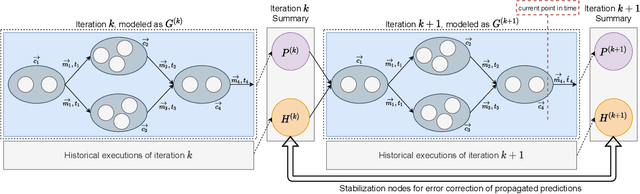
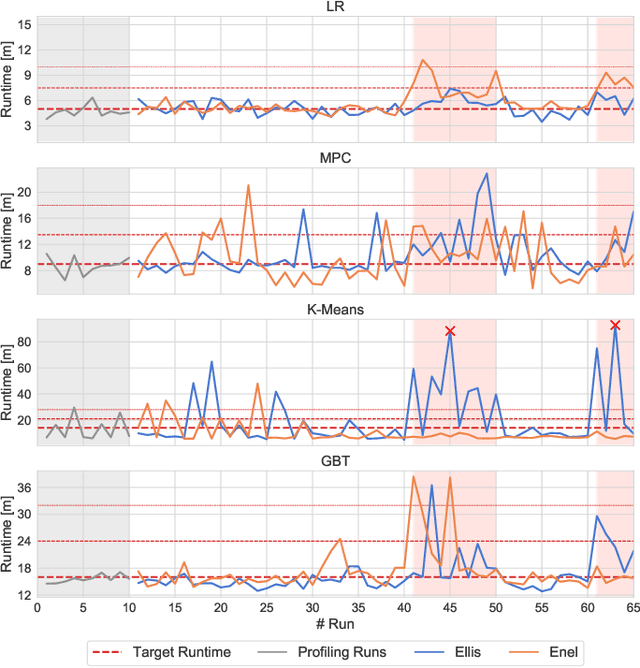
Distributed dataflow systems like Spark and Flink enable the use of clusters for scalable data analytics. While runtime prediction models can be used to initially select appropriate cluster resources given target runtimes, the actual runtime performance of dataflow jobs depends on several factors and varies over time. Yet, in many situations, dynamic scaling can be used to meet formulated runtime targets despite significant performance variance. This paper presents Enel, a novel dynamic scaling approach that uses message propagation on an attributed graph to model dataflow jobs and, thus, allows for deriving effective rescaling decisions. For this, Enel incorporates descriptive properties that capture the respective execution context, considers statistics from individual dataflow tasks, and propagates predictions through the job graph to eventually find an optimized new scale-out. Our evaluation of Enel with four iterative Spark jobs shows that our approach is able to identify effective rescaling actions, reacting for instance to node failures, and can be reused across different execution contexts.
Bellamy: Reusing Performance Models for Distributed Dataflow Jobs Across Contexts
Jul 29, 2021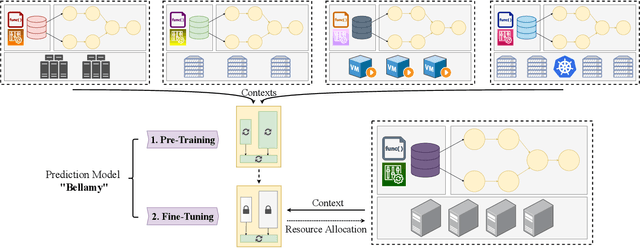
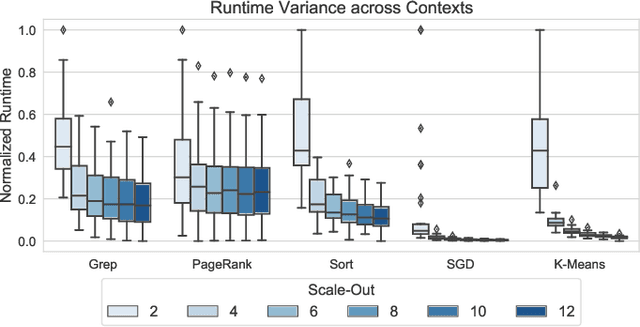
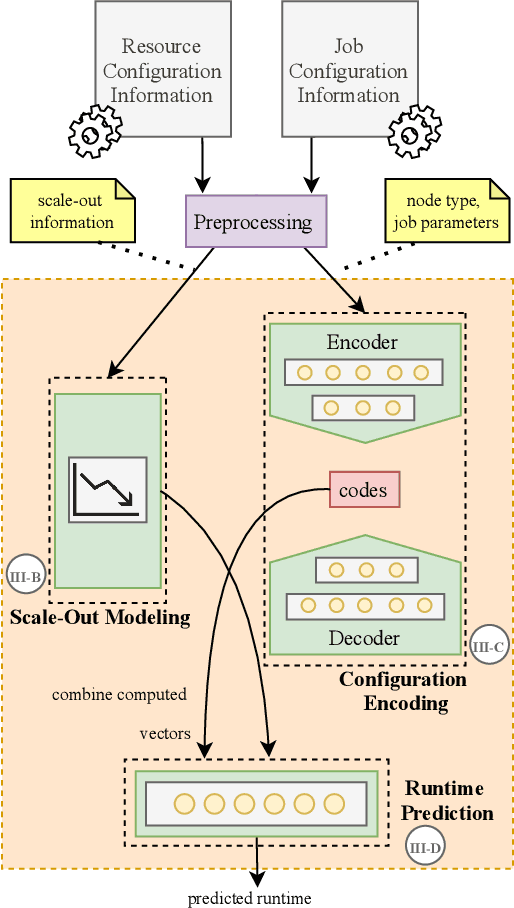
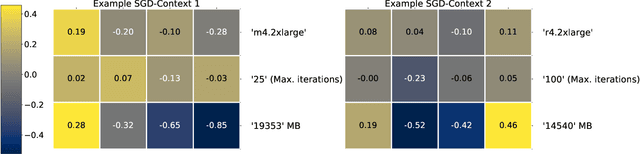
Distributed dataflow systems enable the use of clusters for scalable data analytics. However, selecting appropriate cluster resources for a processing job is often not straightforward. Performance models trained on historical executions of a concrete job are helpful in such situations, yet they are usually bound to a specific job execution context (e.g. node type, software versions, job parameters) due to the few considered input parameters. Even in case of slight context changes, such supportive models need to be retrained and cannot benefit from historical execution data from related contexts. This paper presents Bellamy, a novel modeling approach that combines scale-outs, dataset sizes, and runtimes with additional descriptive properties of a dataflow job. It is thereby able to capture the context of a job execution. Moreover, Bellamy is realizing a two-step modeling approach. First, a general model is trained on all the available data for a specific scalable analytics algorithm, hereby incorporating data from different contexts. Subsequently, the general model is optimized for the specific situation at hand, based on the available data for the concrete context. We evaluate our approach on two publicly available datasets consisting of execution data from various dataflow jobs carried out in different environments, showing that Bellamy outperforms state-of-the-art methods.
Learning Dependencies in Distributed Cloud Applications to Identify and Localize Anomalies
Mar 09, 2021
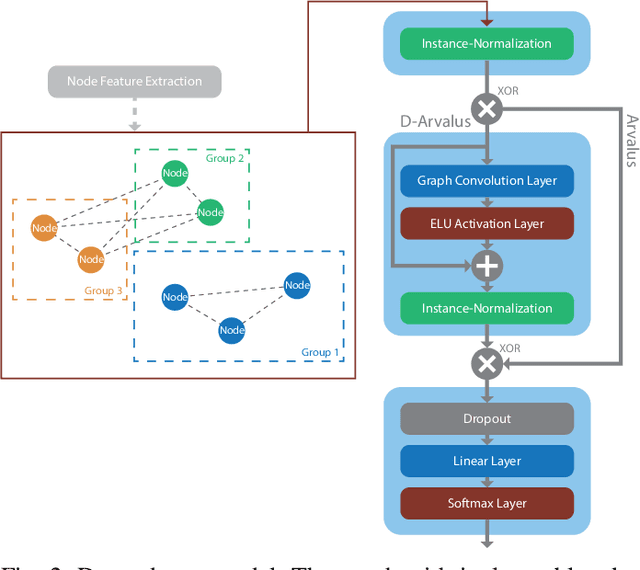
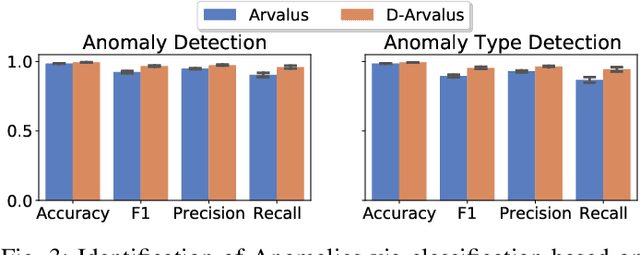
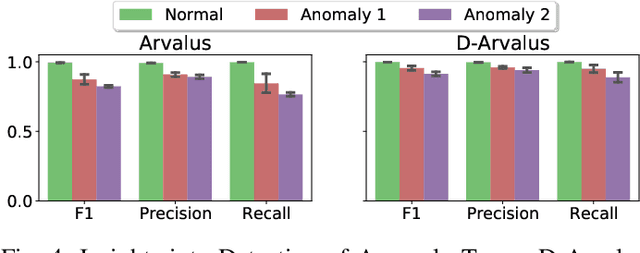
Operation and maintenance of large distributed cloud applications can quickly become unmanageably complex, putting human operators under immense stress when problems occur. Utilizing machine learning for identification and localization of anomalies in such systems supports human experts and enables fast mitigation. However, due to the various inter-dependencies of system components, anomalies do not only affect their origin but propagate through the distributed system. Taking this into account, we present Arvalus and its variant D-Arvalus, a neural graph transformation method that models system components as nodes and their dependencies and placement as edges to improve the identification and localization of anomalies. Given a series of metric KPIs, our method predicts the most likely system state - either normal or an anomaly class - and performs localization when an anomaly is detected. During our experiments, we simulate a distributed cloud application deployment and synthetically inject anomalies. The evaluation shows the generally good prediction performance of Arvalus and reveals the advantage of D-Arvalus which incorporates information about system component dependencies.