 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagpie: Automatically Tuning Static Parameters for Distributed File Systems using Deep Reinforcement Learning
Jul 22, 2022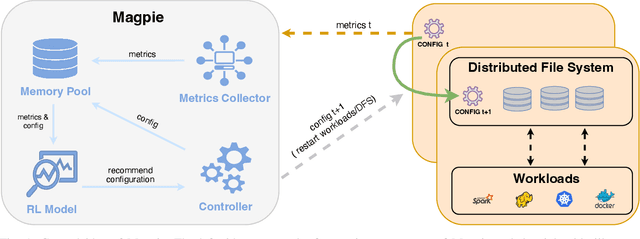
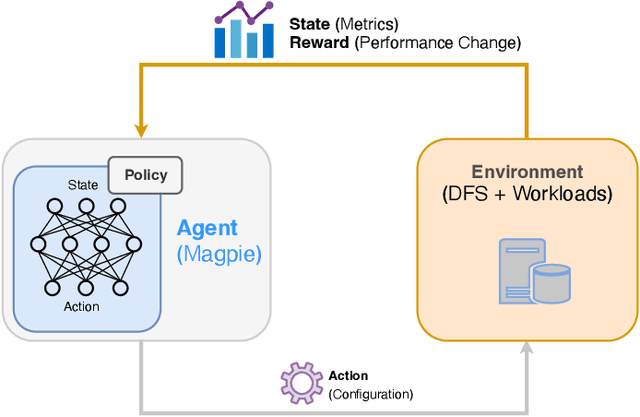
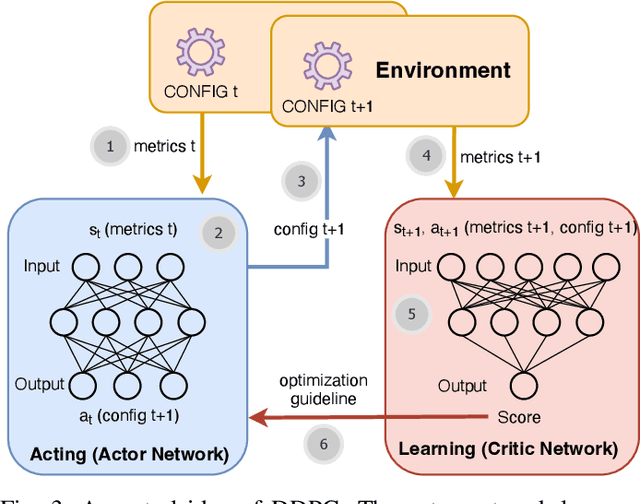
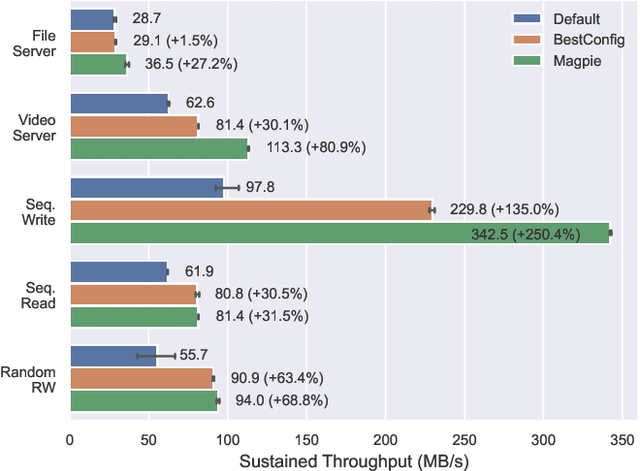
Distributed file systems are widely used nowadays, yet using their default configurations is often not optimal. At the same time, tuning configuration parameters is typically challenging and time-consuming. It demands expertise and tuning operations can also be expensive. This is especially the case for static parameters, where changes take effect only after a restart of the system or workloads. We propose a novel approach, Magpie, which utilizes deep reinforcement learning to tune static parameters by strategically exploring and exploiting configuration parameter spaces. To boost the tuning of the static parameters, our method employs both server and client metrics of distributed file systems to understand the relationship between static parameters and performance. Our empirical evaluation results show that Magpie can noticeably improve the performance of the distributed file system Lustre, where our approach on average achieves 91.8% throughput gains against default configuration after tuning towards single performance indicator optimization, while it reaches 39.7% more throughput gains against the baseline.
Enel: Context-Aware Dynamic Scaling of Distributed Dataflow Jobs using Graph Propagation
Aug 27, 2021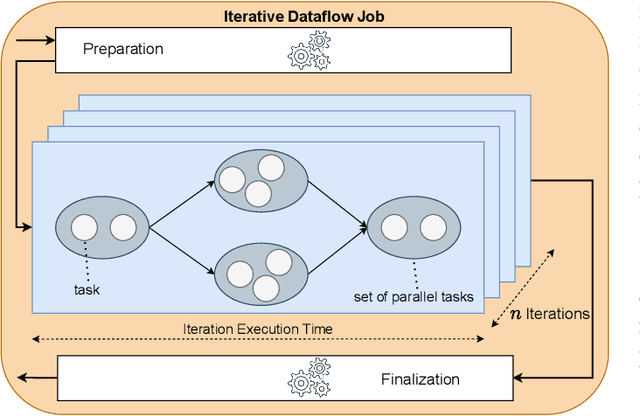

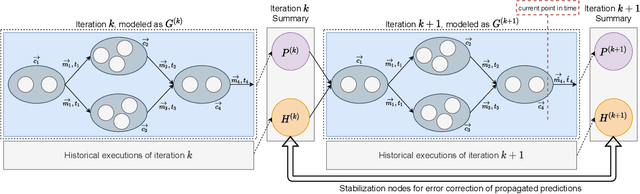
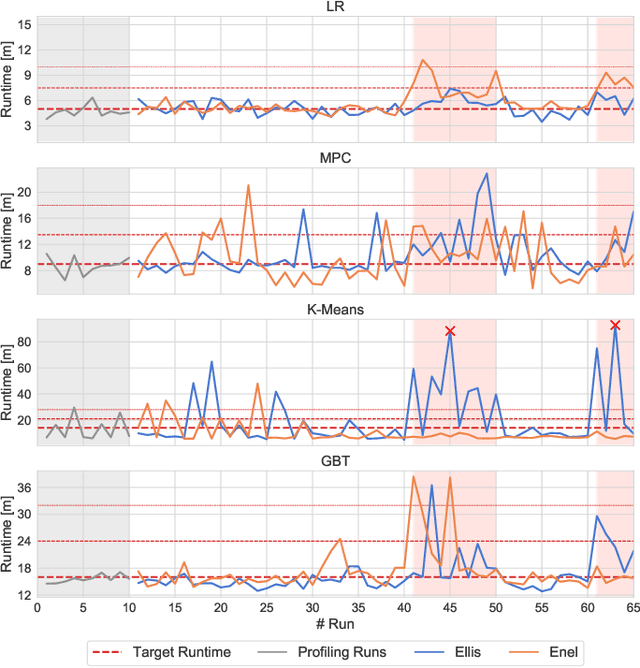
Distributed dataflow systems like Spark and Flink enable the use of clusters for scalable data analytics. While runtime prediction models can be used to initially select appropriate cluster resources given target runtimes, the actual runtime performance of dataflow jobs depends on several factors and varies over time. Yet, in many situations, dynamic scaling can be used to meet formulated runtime targets despite significant performance variance. This paper presents Enel, a novel dynamic scaling approach that uses message propagation on an attributed graph to model dataflow jobs and, thus, allows for deriving effective rescaling decisions. For this, Enel incorporates descriptive properties that capture the respective execution context, considers statistics from individual dataflow tasks, and propagates predictions through the job graph to eventually find an optimized new scale-out. Our evaluation of Enel with four iterative Spark jobs shows that our approach is able to identify effective rescaling actions, reacting for instance to node failures, and can be reused across different execution contexts.
Bellamy: Reusing Performance Models for Distributed Dataflow Jobs Across Contexts
Jul 29, 2021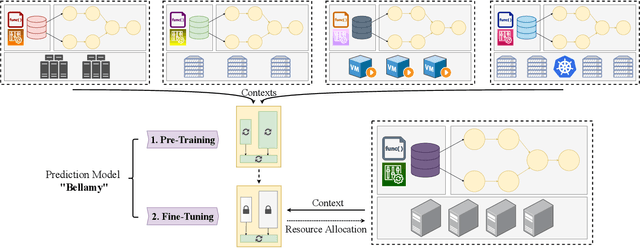
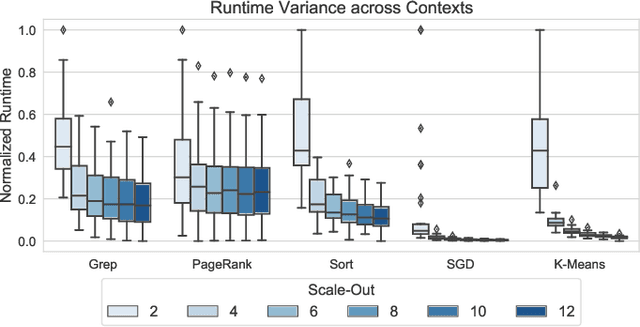
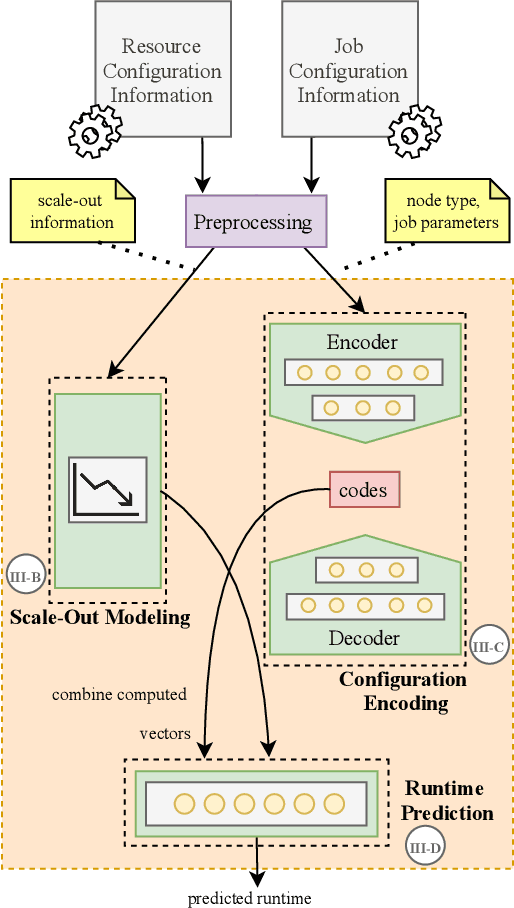
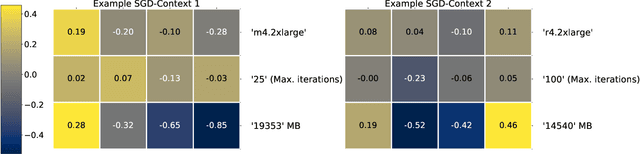
Distributed dataflow systems enable the use of clusters for scalable data analytics. However, selecting appropriate cluster resources for a processing job is often not straightforward. Performance models trained on historical executions of a concrete job are helpful in such situations, yet they are usually bound to a specific job execution context (e.g. node type, software versions, job parameters) due to the few considered input parameters. Even in case of slight context changes, such supportive models need to be retrained and cannot benefit from historical execution data from related contexts. This paper presents Bellamy, a novel modeling approach that combines scale-outs, dataset sizes, and runtimes with additional descriptive properties of a dataflow job. It is thereby able to capture the context of a job execution. Moreover, Bellamy is realizing a two-step modeling approach. First, a general model is trained on all the available data for a specific scalable analytics algorithm, hereby incorporating data from different contexts. Subsequently, the general model is optimized for the specific situation at hand, based on the available data for the concrete context. We evaluate our approach on two publicly available datasets consisting of execution data from various dataflow jobs carried out in different environments, showing that Bellamy outperforms state-of-the-art methods.