 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnel: Context-Aware Dynamic Scaling of Distributed Dataflow Jobs using Graph Propagation
Aug 27, 2021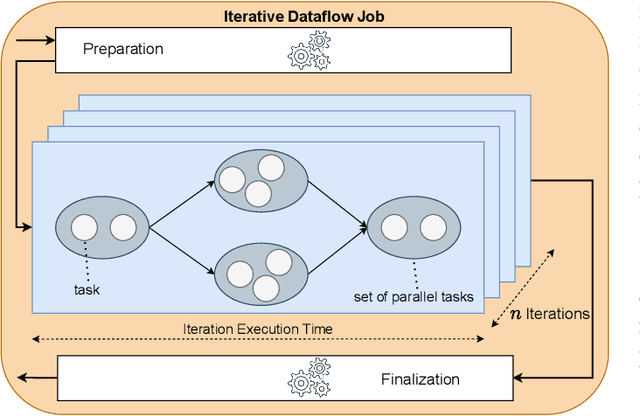

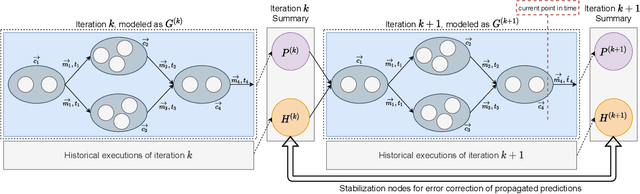
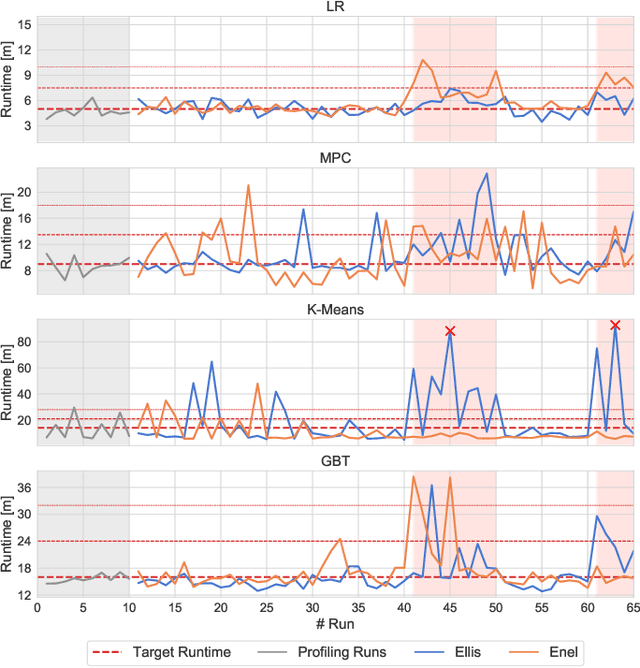
Distributed dataflow systems like Spark and Flink enable the use of clusters for scalable data analytics. While runtime prediction models can be used to initially select appropriate cluster resources given target runtimes, the actual runtime performance of dataflow jobs depends on several factors and varies over time. Yet, in many situations, dynamic scaling can be used to meet formulated runtime targets despite significant performance variance. This paper presents Enel, a novel dynamic scaling approach that uses message propagation on an attributed graph to model dataflow jobs and, thus, allows for deriving effective rescaling decisions. For this, Enel incorporates descriptive properties that capture the respective execution context, considers statistics from individual dataflow tasks, and propagates predictions through the job graph to eventually find an optimized new scale-out. Our evaluation of Enel with four iterative Spark jobs shows that our approach is able to identify effective rescaling actions, reacting for instance to node failures, and can be reused across different execution contexts.
Learning Dependencies in Distributed Cloud Applications to Identify and Localize Anomalies
Mar 09, 2021
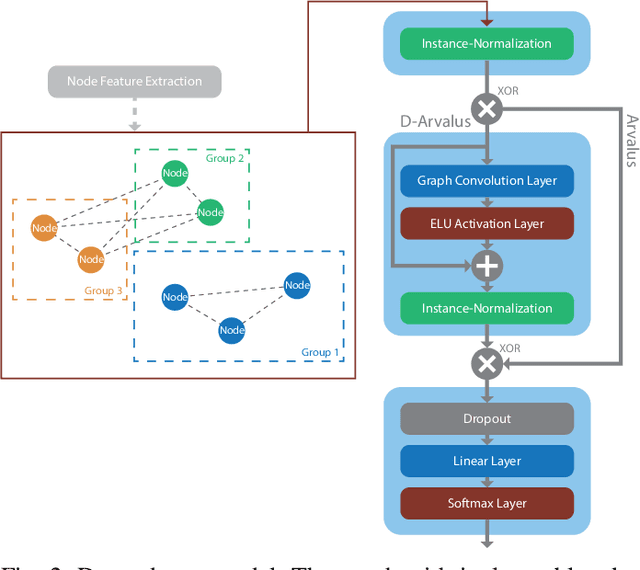
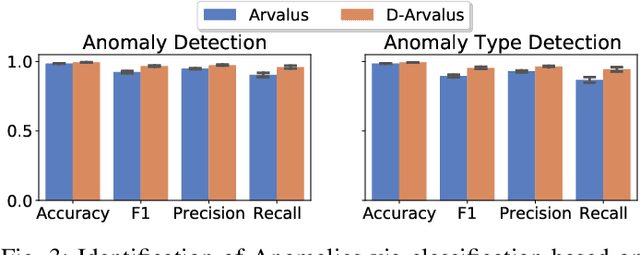
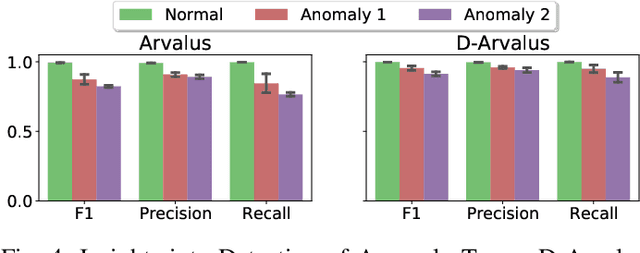
Operation and maintenance of large distributed cloud applications can quickly become unmanageably complex, putting human operators under immense stress when problems occur. Utilizing machine learning for identification and localization of anomalies in such systems supports human experts and enables fast mitigation. However, due to the various inter-dependencies of system components, anomalies do not only affect their origin but propagate through the distributed system. Taking this into account, we present Arvalus and its variant D-Arvalus, a neural graph transformation method that models system components as nodes and their dependencies and placement as edges to improve the identification and localization of anomalies. Given a series of metric KPIs, our method predicts the most likely system state - either normal or an anomaly class - and performs localization when an anomaly is detected. During our experiments, we simulate a distributed cloud application deployment and synthetically inject anomalies. The evaluation shows the generally good prediction performance of Arvalus and reveals the advantage of D-Arvalus which incorporates information about system component dependencies.