 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Genetic Evolution of Neural Networks for Optimal SFC Embedding
Dec 10, 2025The reliance of organisations on computer networks is enabled by network programmability, which is typically achieved through Service Function Chaining. These chains virtualise network functions, link them, and programmatically embed them on networking infrastructure. Optimal embedding of Service Function Chains is an NP-hard problem, with three sub-problems, chain composition, virtual network function embedding, and link embedding, that have to be optimised simultaneously, rather than sequentially, for optimal results. Genetic Algorithms have been employed for this, but existing approaches either do not optimise all three sub-problems or do not optimise all three sub-problems simultaneously. We propose a Genetic Algorithm-based approach called GENESIS, which evolves three sine-function-activated Neural Networks, and funnels their output to a Gaussian distribution and an A* algorithm to optimise all three sub-problems simultaneously. We evaluate GENESIS on an emulator across 48 different data centre scenarios and compare its performance to two state-of-the-art Genetic Algorithms and one greedy algorithm. GENESIS produces an optimal solution for 100% of the scenarios, whereas the second-best method optimises only 71% of the scenarios. Moreover, GENESIS is the fastest among all Genetic Algorithms, averaging 15.84 minutes, compared to an average of 38.62 minutes for the second-best Genetic Algorithm.
Karasu: A Collaborative Approach to Efficient Cluster Configuration for Big Data Analytics
Aug 22, 2023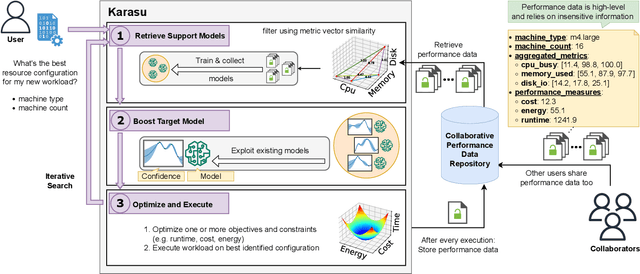
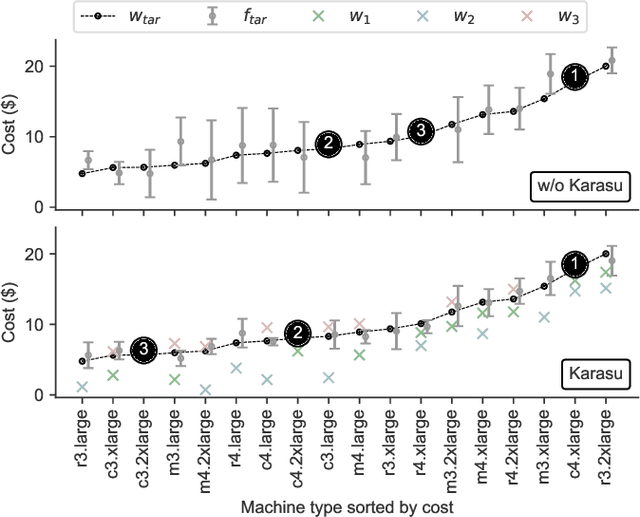
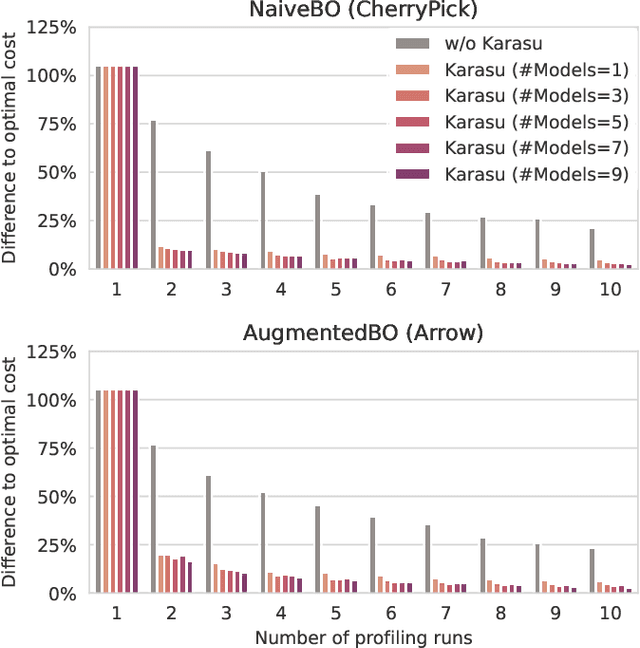
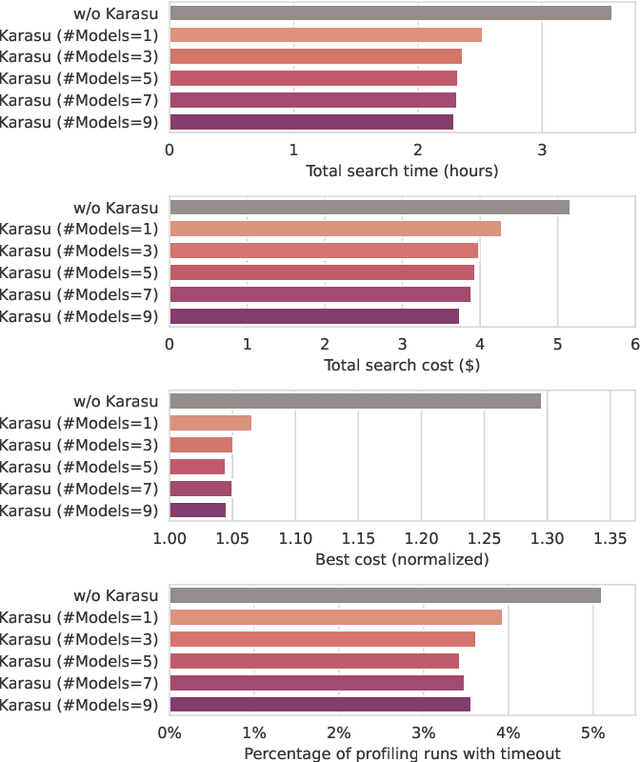
Selecting the right resources for big data analytics jobs is hard because of the wide variety of configuration options like machine type and cluster size. As poor choices can have a significant impact on resource efficiency, cost, and energy usage, automated approaches are gaining popularity. Most existing methods rely on profiling recurring workloads to find near-optimal solutions over time. Due to the cold-start problem, this often leads to lengthy and costly profiling phases. However, big data analytics jobs across users can share many common properties: they often operate on similar infrastructure, using similar algorithms implemented in similar frameworks. The potential in sharing aggregated profiling runs to collaboratively address the cold start problem is largely unexplored. We present Karasu, an approach to more efficient resource configuration profiling that promotes data sharing among users working with similar infrastructures, frameworks, algorithms, or datasets. Karasu trains lightweight performance models using aggregated runtime information of collaborators and combines them into an ensemble method to exploit inherent knowledge of the configuration search space. Moreover, Karasu allows the optimization of multiple objectives simultaneously. Our evaluation is based on performance data from diverse workload executions in a public cloud environment. We show that Karasu is able to significantly boost existing methods in terms of performance, search time, and cost, even when few comparable profiling runs are available that share only partial common characteristics with the target job.
FedZero: Leveraging Renewable Excess Energy in Federated Learning
May 24, 2023Federated Learning (FL) is an emerging machine learning technique that enables distributed model training across data silos or edge devices without data sharing. Yet, FL inevitably introduces inefficiencies compared to centralized model training, which will further increase the already high energy usage and associated carbon emissions of machine learning in the future. Although the scheduling of workloads based on the availability of low-carbon energy has received considerable attention in recent years, it has not yet been investigated in the context of FL. However, FL is a highly promising use case for carbon-aware computing, as training jobs constitute of energy-intensive batch processes scheduled in geo-distributed environments. We propose FedZero, a FL system that operates exclusively on renewable excess energy and spare capacity of compute infrastructure to effectively reduce the training's operational carbon emissions to zero. Based on energy and load forecasts, FedZero leverages the spatio-temporal availability of excess energy by cherry-picking clients for fast convergence and fair participation. Our evaluation, based on real solar and load traces, shows that FedZero converges considerably faster under the mentioned constraints than state-of-the-art approaches, is highly scalable, and is robust against forecasting errors.
Probabilistic Time Series Forecasting for Adaptive Monitoring in Edge Computing Environments
Nov 24, 2022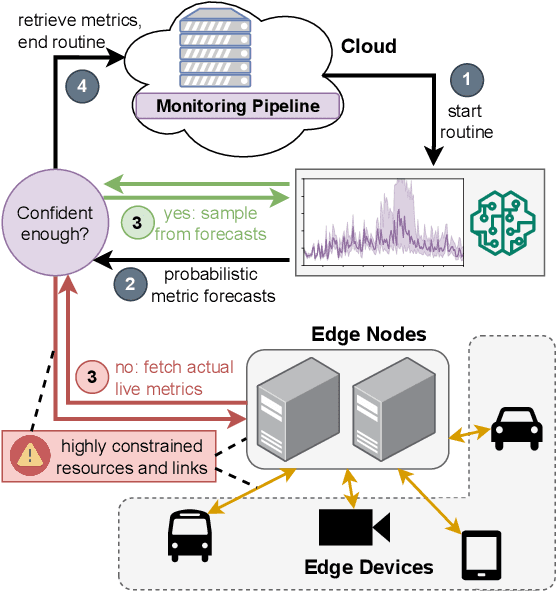



With increasingly more computation being shifted to the edge of the network, monitoring of critical infrastructures, such as intermediate processing nodes in autonomous driving, is further complicated due to the typically resource-constrained environments. In order to reduce the resource overhead on the network link imposed by monitoring, various methods have been discussed that either follow a filtering approach for data-emitting devices or conduct dynamic sampling based on employed prediction models. Still, existing methods are mainly requiring adaptive monitoring on edge devices, which demands device reconfigurations, utilizes additional resources, and limits the sophistication of employed models. In this paper, we propose a sampling-based and cloud-located approach that internally utilizes probabilistic forecasts and hence provides means of quantifying model uncertainties, which can be used for contextualized adaptations of sampling frequencies and consequently relieves constrained network resources. We evaluate our prototype implementation for the monitoring pipeline on a publicly available streaming dataset and demonstrate its positive impact on resource efficiency in a method comparison.
Perona: Robust Infrastructure Fingerprinting for Resource-Efficient Big Data Analytics
Nov 15, 2022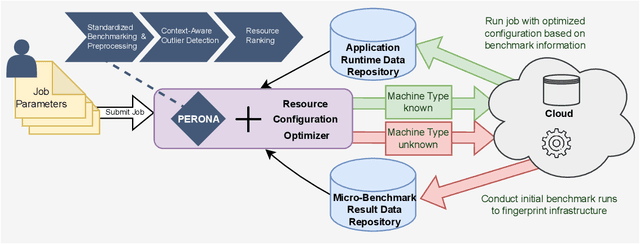
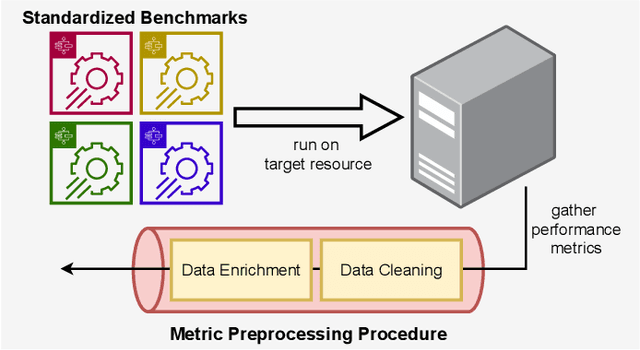
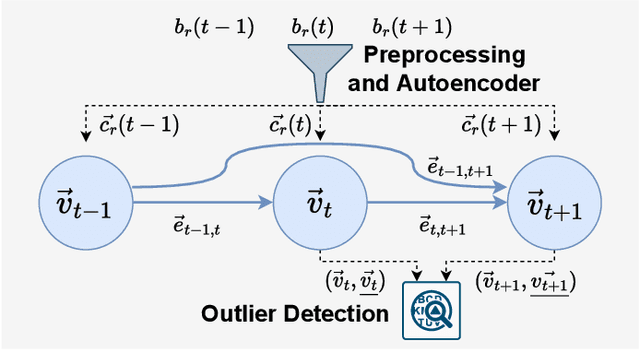
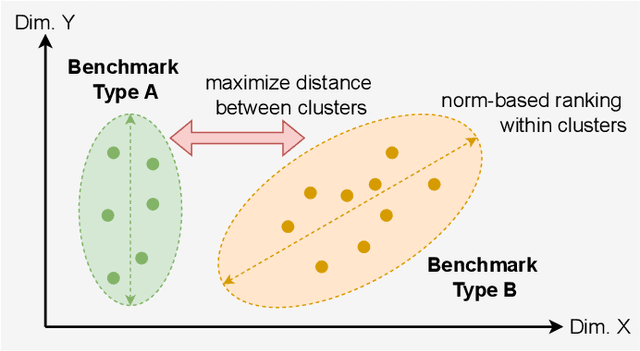
Choosing a good resource configuration for big data analytics applications can be challenging, especially in cloud environments. Automated approaches are desirable as poor decisions can reduce performance and raise costs. The majority of existing automated approaches either build performance models from previous workload executions or conduct iterative resource configuration profiling until a near-optimal solution has been found. In doing so, they only obtain an implicit understanding of the underlying infrastructure, which is difficult to transfer to alternative infrastructures and, thus, profiling and modeling insights are not sustained beyond very specific situations. We present Perona, a novel approach to robust infrastructure fingerprinting for usage in the context of big data analytics. Perona employs common sets and configurations of benchmarking tools for target resources, so that resulting benchmark metrics are directly comparable and ranking is enabled. Insignificant benchmark metrics are discarded by learning a low-dimensional representation of the input metric vector, and previous benchmark executions are taken into consideration for context-awareness as well, allowing to detect resource degradation. We evaluate our approach both on data gathered from our own experiments as well as within related works for resource configuration optimization, demonstrating that Perona captures the characteristics from benchmark runs in a compact manner and produces representations that can be used directly.
Magpie: Automatically Tuning Static Parameters for Distributed File Systems using Deep Reinforcement Learning
Jul 22, 2022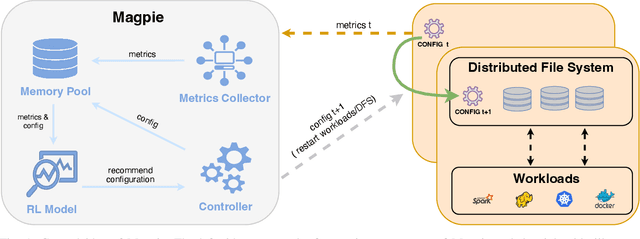
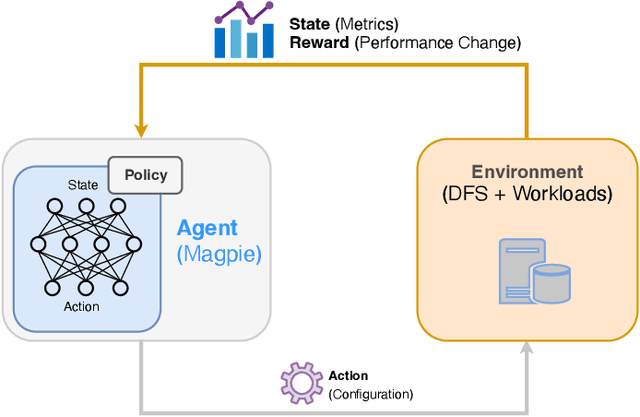
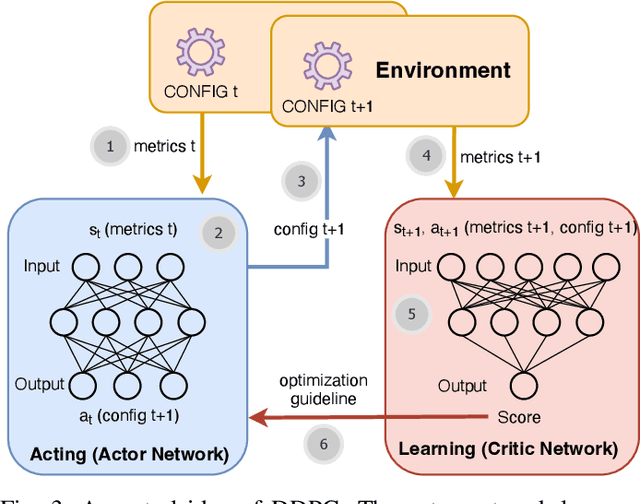
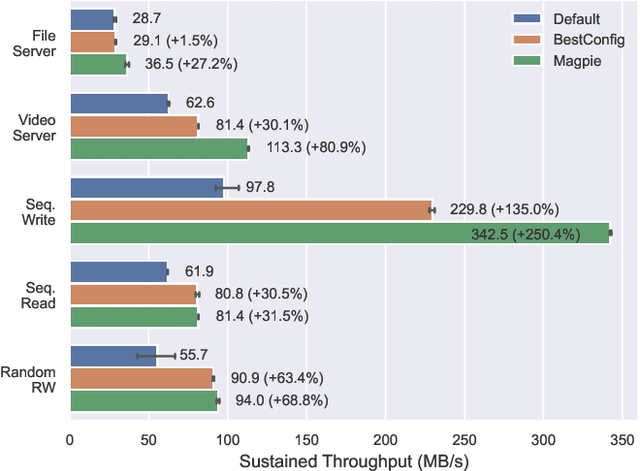
Distributed file systems are widely used nowadays, yet using their default configurations is often not optimal. At the same time, tuning configuration parameters is typically challenging and time-consuming. It demands expertise and tuning operations can also be expensive. This is especially the case for static parameters, where changes take effect only after a restart of the system or workloads. We propose a novel approach, Magpie, which utilizes deep reinforcement learning to tune static parameters by strategically exploring and exploiting configuration parameter spaces. To boost the tuning of the static parameters, our method employs both server and client metrics of distributed file systems to understand the relationship between static parameters and performance. Our empirical evaluation results show that Magpie can noticeably improve the performance of the distributed file system Lustre, where our approach on average achieves 91.8% throughput gains against default configuration after tuning towards single performance indicator optimization, while it reaches 39.7% more throughput gains against the baseline.
On the Potential of Execution Traces for Batch Processing Workload Optimization in Public Clouds
Nov 16, 2021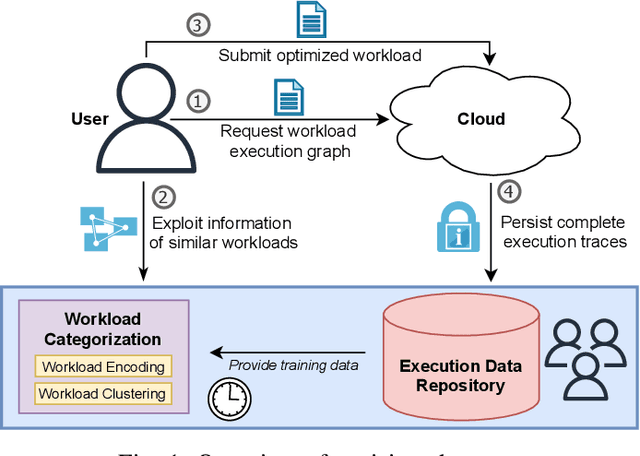
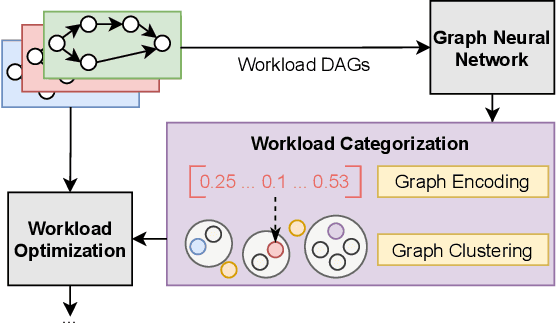
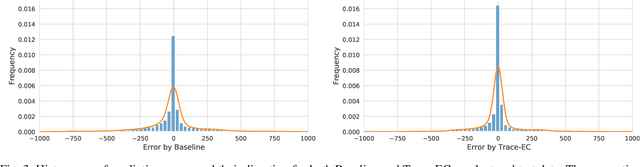
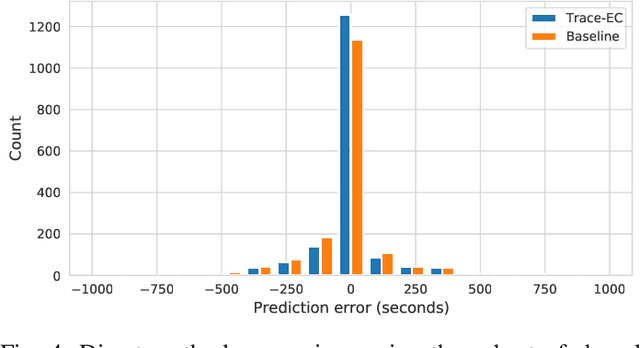
With the growing amount of data, data processing workloads and the management of their resource usage becomes increasingly important. Since managing a dedicated infrastructure is in many situations infeasible or uneconomical, users progressively execute their respective workloads in the cloud. As the configuration of workloads and resources is often challenging, various methods have been proposed that either quickly profile towards a good configuration or determine one based on data from previous runs. Still, performance data to train such methods is often lacking and must be costly collected. In this paper, we propose a collaborative approach for sharing anonymized workload execution traces among users, mining them for general patterns, and exploiting clusters of historical workloads for future optimizations. We evaluate our prototype implementation for mining workload execution graphs on a publicly available trace dataset and demonstrate the predictive value of workload clusters determined through traces only.
Enel: Context-Aware Dynamic Scaling of Distributed Dataflow Jobs using Graph Propagation
Aug 27, 2021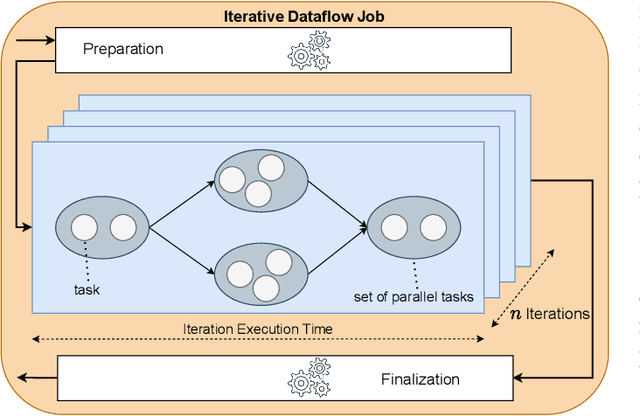

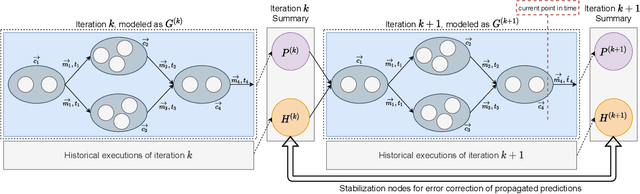
Distributed dataflow systems like Spark and Flink enable the use of clusters for scalable data analytics. While runtime prediction models can be used to initially select appropriate cluster resources given target runtimes, the actual runtime performance of dataflow jobs depends on several factors and varies over time. Yet, in many situations, dynamic scaling can be used to meet formulated runtime targets despite significant performance variance. This paper presents Enel, a novel dynamic scaling approach that uses message propagation on an attributed graph to model dataflow jobs and, thus, allows for deriving effective rescaling decisions. For this, Enel incorporates descriptive properties that capture the respective execution context, considers statistics from individual dataflow tasks, and propagates predictions through the job graph to eventually find an optimized new scale-out. Our evaluation of Enel with four iterative Spark jobs shows that our approach is able to identify effective rescaling actions, reacting for instance to node failures, and can be reused across different execution contexts.
Evaluation of Load Prediction Techniques for Distributed Stream Processing
Aug 10, 2021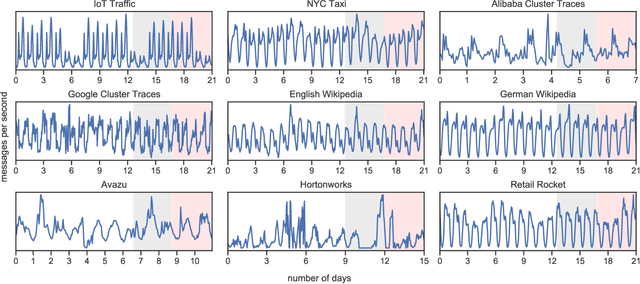
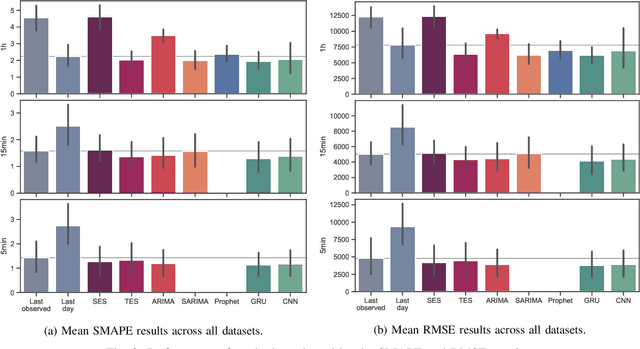
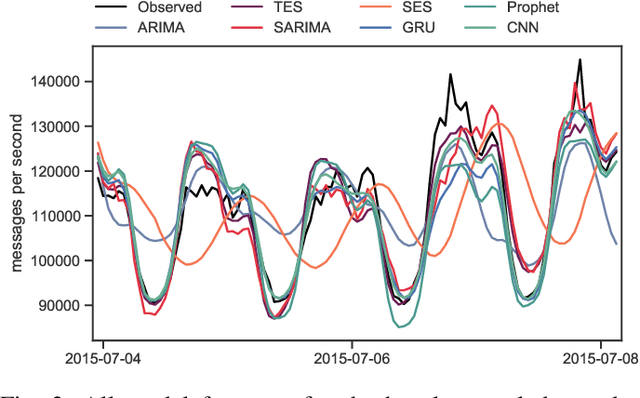
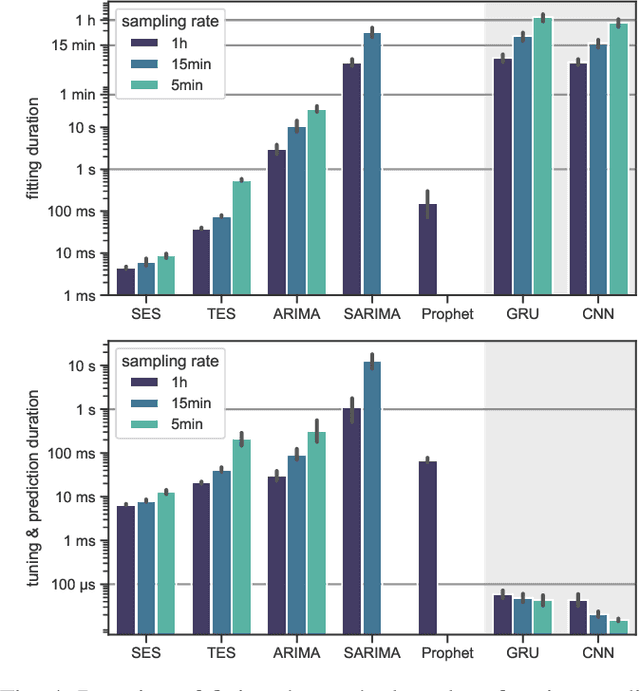
Distributed Stream Processing (DSP) systems enable processing large streams of continuous data to produce results in near to real time. They are an essential part of many data-intensive applications and analytics platforms. The rate at which events arrive at DSP systems can vary considerably over time, which may be due to trends, cyclic, and seasonal patterns within the data streams. A priori knowledge of incoming workloads enables proactive approaches to resource management and optimization tasks such as dynamic scaling, live migration of resources, and the tuning of configuration parameters during run-times, thus leading to a potentially better Quality of Service. In this paper we conduct a comprehensive evaluation of different load prediction techniques for DSP jobs. We identify three use-cases and formulate requirements for making load predictions specific to DSP jobs. Automatically optimized classical and Deep Learning methods are being evaluated on nine different datasets from typical DSP domains, i.e. the IoT, Web 2.0, and cluster monitoring. We compare model performance with respect to overall accuracy and training duration. Our results show that the Deep Learning methods provide the most accurate load predictions for the majority of the evaluated datasets.
Bellamy: Reusing Performance Models for Distributed Dataflow Jobs Across Contexts
Jul 29, 2021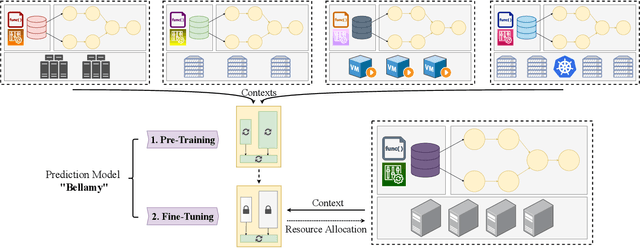
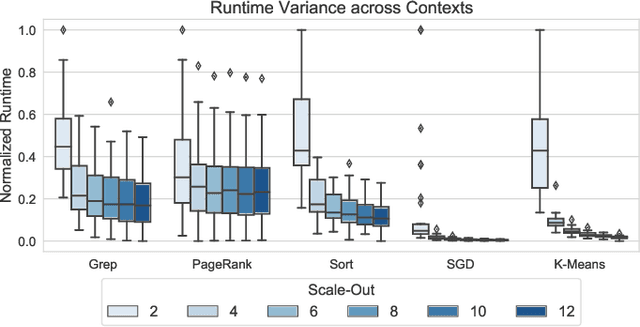
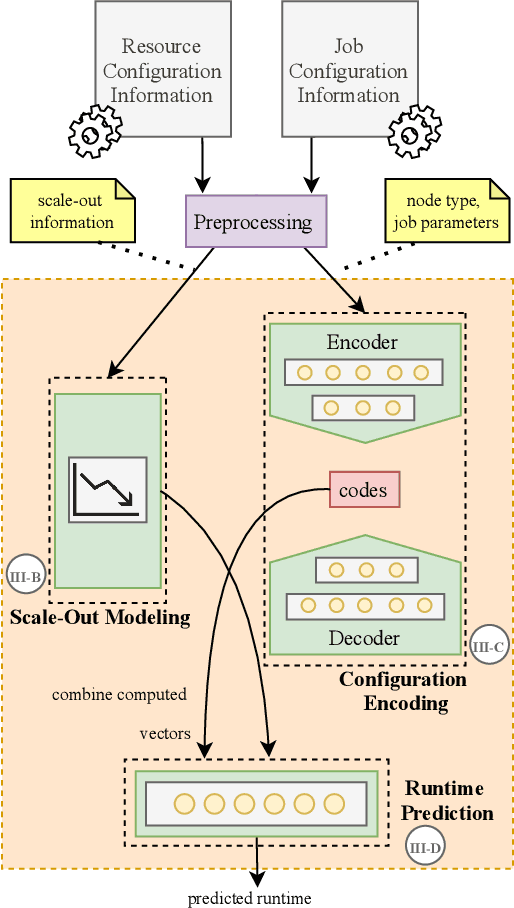
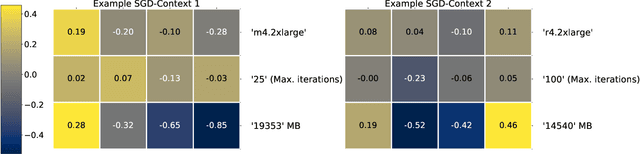
Distributed dataflow systems enable the use of clusters for scalable data analytics. However, selecting appropriate cluster resources for a processing job is often not straightforward. Performance models trained on historical executions of a concrete job are helpful in such situations, yet they are usually bound to a specific job execution context (e.g. node type, software versions, job parameters) due to the few considered input parameters. Even in case of slight context changes, such supportive models need to be retrained and cannot benefit from historical execution data from related contexts. This paper presents Bellamy, a novel modeling approach that combines scale-outs, dataset sizes, and runtimes with additional descriptive properties of a dataflow job. It is thereby able to capture the context of a job execution. Moreover, Bellamy is realizing a two-step modeling approach. First, a general model is trained on all the available data for a specific scalable analytics algorithm, hereby incorporating data from different contexts. Subsequently, the general model is optimized for the specific situation at hand, based on the available data for the concrete context. We evaluate our approach on two publicly available datasets consisting of execution data from various dataflow jobs carried out in different environments, showing that Bellamy outperforms state-of-the-art methods.