 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed LLM Pretraining During Renewable Curtailment Windows: A Feasibility Study
Feb 26, 2026Training large language models (LLMs) requires substantial compute and energy. At the same time, renewable energy sources regularly produce more electricity than the grid can absorb, leading to curtailment, the deliberate reduction of clean generation that would otherwise go to waste. These periods represent an opportunity: if training is aligned with curtailment windows, LLMs can be pretrained using electricity that is both clean and cheap. This technical report presents a system that performs full-parameter LLM training across geo-distributed GPU clusters during regional curtailment windows, elastically switching between local single-site training and federated multi-site synchronization as sites become available or unavailable. Our prototype trains a 561M-parameter transformer model across three clusters using the Flower federated learning framework, with curtailment periods derived from real-world marginal carbon intensity traces. Preliminary results show that curtailment-aware scheduling preserves training quality while reducing operational emissions to 5-12% of single-site baselines.
What happens when nanochat meets DiLoCo?
Nov 14, 2025Although LLM training is typically centralized with high-bandwidth interconnects and large compute budgets, emerging methods target communication-constrained training in distributed environments. The model trade-offs introduced by this shift remain underexplored, and our goal is to study them. We use the open-source nanochat project, a compact 8K-line full-stack ChatGPT-like implementation containing tokenization, pretraining, fine-tuning, and serving, as a controlled baseline. We implement the DiLoCo algorithm as a lightweight wrapper over nanochat's training loop, performing multiple local steps per worker before synchronization with an outer optimizer, effectively reducing communication by orders of magnitude. This inner-outer training is compared against a standard data-parallel (DDP) setup. Because nanochat is small and inspectable, it enables controlled pipeline adaptations and allows direct comparison with the conventional centralized baseline. DiLoCo achieves stable convergence and competitive loss in pretraining but yields worse MMLU, GSM8K, and HumanEval scores after mid-training and SFT. We discover that using DiLoCo-pretrained weights and running mid- and post-training with DDP fails to recover performance, revealing irreversible representation drift from asynchronous updates that impairs downstream alignment. We provide this implementation as an official fork of nanochat on GitHub.
Probabilistic Time Series Forecasting for Adaptive Monitoring in Edge Computing Environments
Nov 24, 2022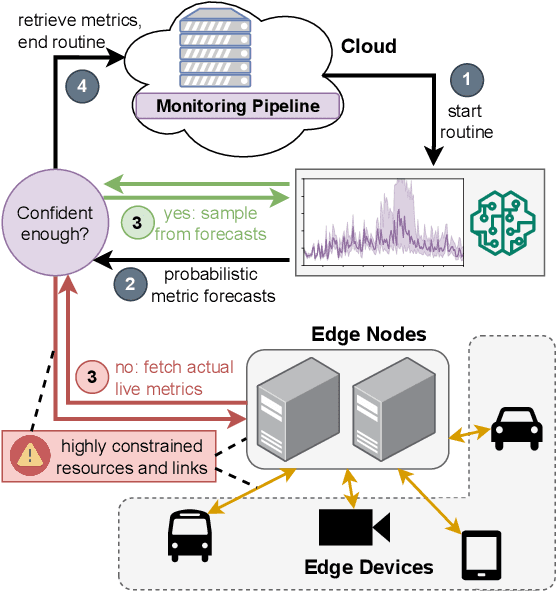



With increasingly more computation being shifted to the edge of the network, monitoring of critical infrastructures, such as intermediate processing nodes in autonomous driving, is further complicated due to the typically resource-constrained environments. In order to reduce the resource overhead on the network link imposed by monitoring, various methods have been discussed that either follow a filtering approach for data-emitting devices or conduct dynamic sampling based on employed prediction models. Still, existing methods are mainly requiring adaptive monitoring on edge devices, which demands device reconfigurations, utilizes additional resources, and limits the sophistication of employed models. In this paper, we propose a sampling-based and cloud-located approach that internally utilizes probabilistic forecasts and hence provides means of quantifying model uncertainties, which can be used for contextualized adaptations of sampling frequencies and consequently relieves constrained network resources. We evaluate our prototype implementation for the monitoring pipeline on a publicly available streaming dataset and demonstrate its positive impact on resource efficiency in a method comparison.
Perona: Robust Infrastructure Fingerprinting for Resource-Efficient Big Data Analytics
Nov 15, 2022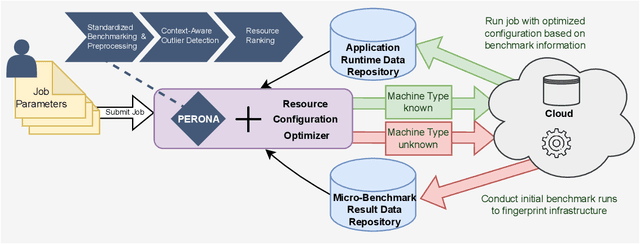
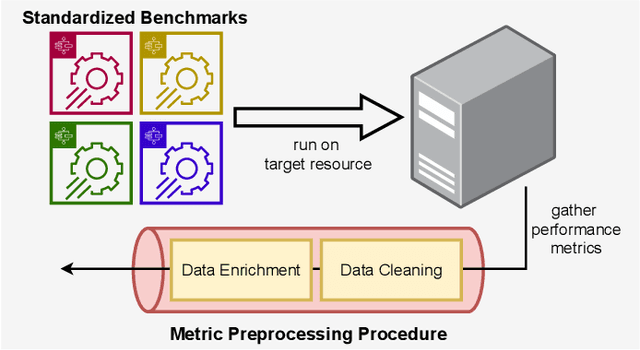
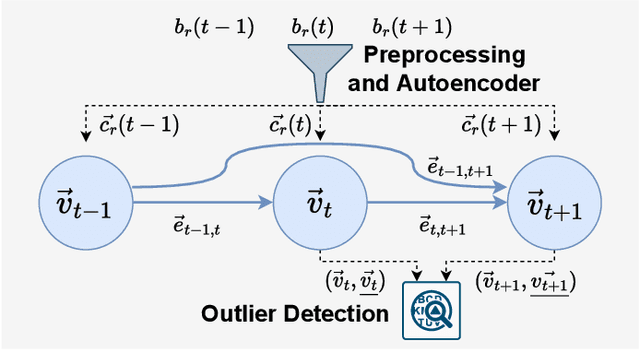
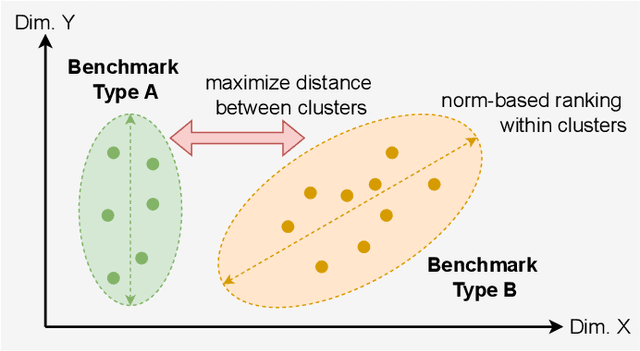
Choosing a good resource configuration for big data analytics applications can be challenging, especially in cloud environments. Automated approaches are desirable as poor decisions can reduce performance and raise costs. The majority of existing automated approaches either build performance models from previous workload executions or conduct iterative resource configuration profiling until a near-optimal solution has been found. In doing so, they only obtain an implicit understanding of the underlying infrastructure, which is difficult to transfer to alternative infrastructures and, thus, profiling and modeling insights are not sustained beyond very specific situations. We present Perona, a novel approach to robust infrastructure fingerprinting for usage in the context of big data analytics. Perona employs common sets and configurations of benchmarking tools for target resources, so that resulting benchmark metrics are directly comparable and ranking is enabled. Insignificant benchmark metrics are discarded by learning a low-dimensional representation of the input metric vector, and previous benchmark executions are taken into consideration for context-awareness as well, allowing to detect resource degradation. We evaluate our approach both on data gathered from our own experiments as well as within related works for resource configuration optimization, demonstrating that Perona captures the characteristics from benchmark runs in a compact manner and produces representations that can be used directly.
Federated Learning for Autoencoder-based Condition Monitoring in the Industrial Internet of Things
Nov 14, 2022Enabled by the increasing availability of sensor data monitored from production machinery, condition monitoring and predictive maintenance methods are key pillars for an efficient and robust manufacturing production cycle in the Industrial Internet of Things. The employment of machine learning models to detect and predict deteriorating behavior by analyzing a variety of data collected across several industrial environments shows promising results in recent works, yet also often requires transferring the sensor data to centralized servers located in the cloud. Moreover, although collaborating and sharing knowledge between industry sites yields large benefits, especially in the area of condition monitoring, it is often prohibited due to data privacy issues. To tackle this situation, we propose an Autoencoder-based Federated Learning method utilizing vibration sensor data from rotating machines, that allows for a distributed training on edge devices, located on-premise and close to the monitored machines. Preserving data privacy and at the same time exonerating possibly unreliable network connections of remote sites, our approach enables knowledge transfer across organizational boundaries, without sharing the monitored data. We conducted an evaluation utilizing two real-world datasets as well as multiple testbeds and the results indicate that our method enables a competitive performance compared to previous results, while significantly reducing the resource and network utilization.
Towards AIOps in Edge Computing Environments
Feb 12, 2021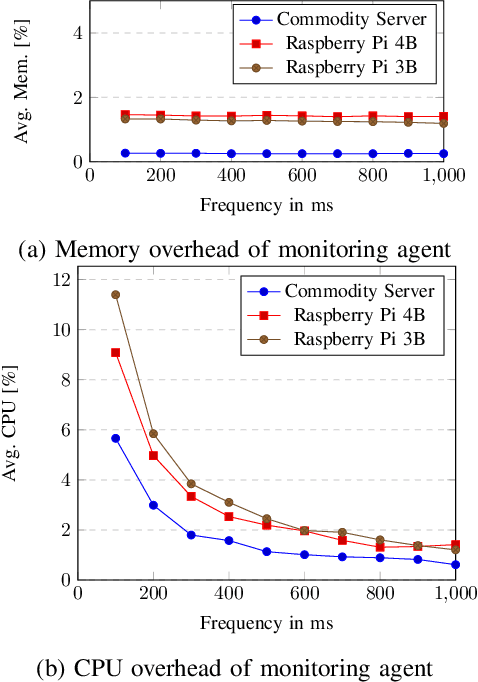
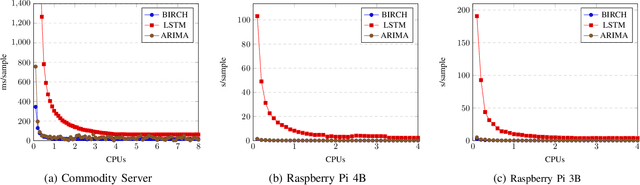
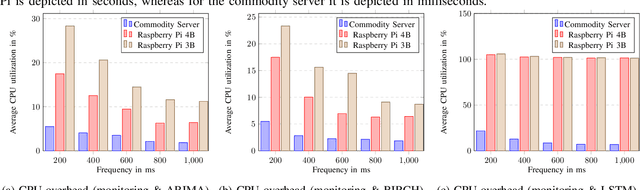
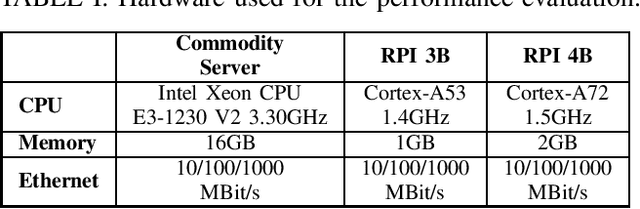
Edge computing was introduced as a technical enabler for the demanding requirements of new network technologies like 5G. It aims to overcome challenges related to centralized cloud computing environments by distributing computational resources to the edge of the network towards the customers. The complexity of the emerging infrastructures increases significantly, together with the ramifications of outages on critical use cases such as self-driving cars or health care. Artificial Intelligence for IT Operations (AIOps) aims to support human operators in managing complex infrastructures by using machine learning methods. This paper describes the system design of an AIOps platform which is applicable in heterogeneous, distributed environments. The overhead of a high-frequency monitoring solution on edge devices is evaluated and performance experiments regarding the applicability of three anomaly detection algorithms on edge devices are conducted. The results show, that it is feasible to collect metrics with a high frequency and simultaneously run specific anomaly detection algorithms directly on edge devices with a reasonable overhead on the resource utilization.
Artificial Intelligence for IT Operations (AIOPS) Workshop White Paper
Jan 15, 2021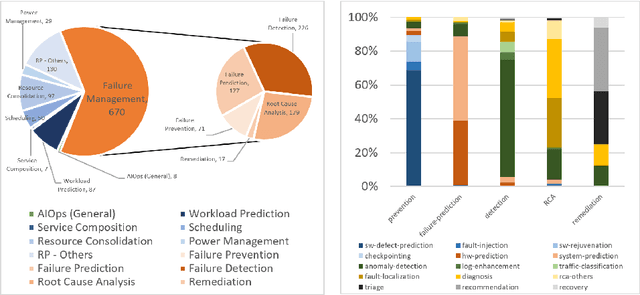
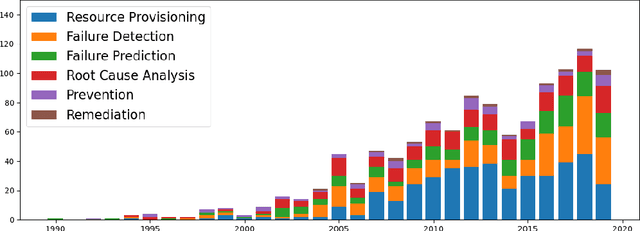
Artificial Intelligence for IT Operations (AIOps) is an emerging interdisciplinary field arising in the intersection between the research areas of machine learning, big data, streaming analytics, and the management of IT operations. AIOps, as a field, is a candidate to produce the future standard for IT operation management. To that end, AIOps has several challenges. First, it needs to combine separate research branches from other research fields like software reliability engineering. Second, novel modelling techniques are needed to understand the dynamics of different systems. Furthermore, it requires to lay out the basis for assessing: time horizons and uncertainty for imminent SLA violations, the early detection of emerging problems, autonomous remediation, decision making, support of various optimization objectives. Moreover, a good understanding and interpretability of these aiding models are important for building trust between the employed tools and the domain experts. Finally, all this will result in faster adoption of AIOps, further increase the interest in this research field and contribute to bridging the gap towards fully-autonomous operating IT systems. The main aim of the AIOPS workshop is to bring together researchers from both academia and industry to present their experiences, results, and work in progress in this field. The workshop aims to strengthen the community and unite it towards the goal of joining the efforts for solving the main challenges the field is currently facing. A consensus and adoption of the principles of openness and reproducibility will boost the research in this emerging area significantly.