 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerona: Robust Infrastructure Fingerprinting for Resource-Efficient Big Data Analytics
Nov 15, 2022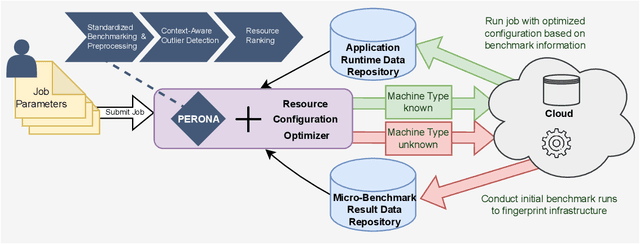
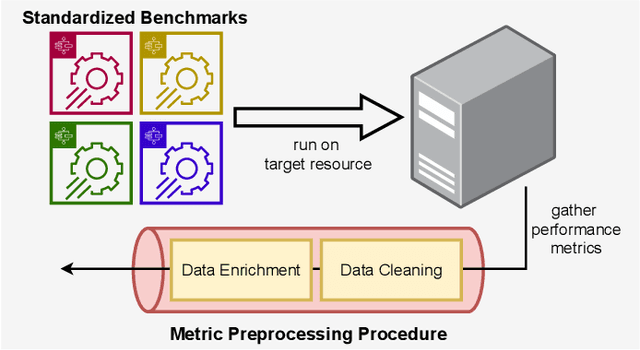
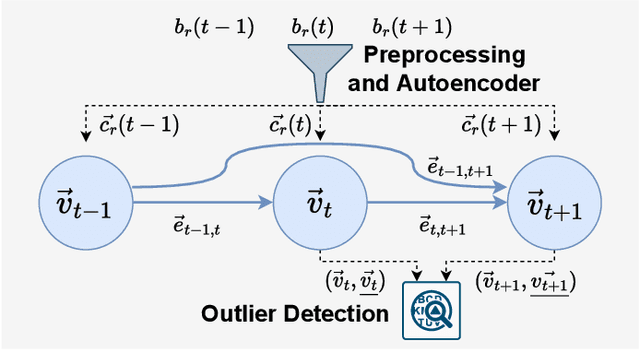
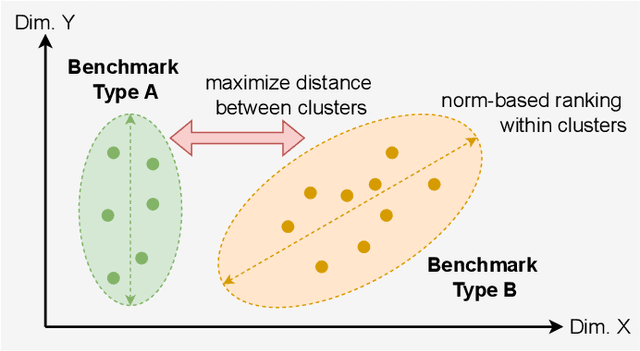
Choosing a good resource configuration for big data analytics applications can be challenging, especially in cloud environments. Automated approaches are desirable as poor decisions can reduce performance and raise costs. The majority of existing automated approaches either build performance models from previous workload executions or conduct iterative resource configuration profiling until a near-optimal solution has been found. In doing so, they only obtain an implicit understanding of the underlying infrastructure, which is difficult to transfer to alternative infrastructures and, thus, profiling and modeling insights are not sustained beyond very specific situations. We present Perona, a novel approach to robust infrastructure fingerprinting for usage in the context of big data analytics. Perona employs common sets and configurations of benchmarking tools for target resources, so that resulting benchmark metrics are directly comparable and ranking is enabled. Insignificant benchmark metrics are discarded by learning a low-dimensional representation of the input metric vector, and previous benchmark executions are taken into consideration for context-awareness as well, allowing to detect resource degradation. We evaluate our approach both on data gathered from our own experiments as well as within related works for resource configuration optimization, demonstrating that Perona captures the characteristics from benchmark runs in a compact manner and produces representations that can be used directly.
On the Potential of Execution Traces for Batch Processing Workload Optimization in Public Clouds
Nov 16, 2021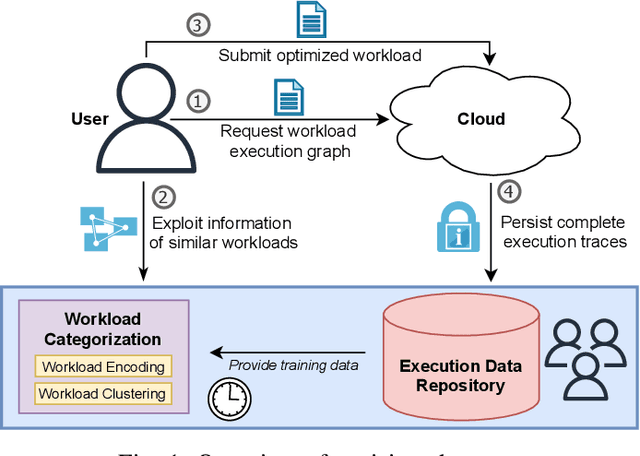
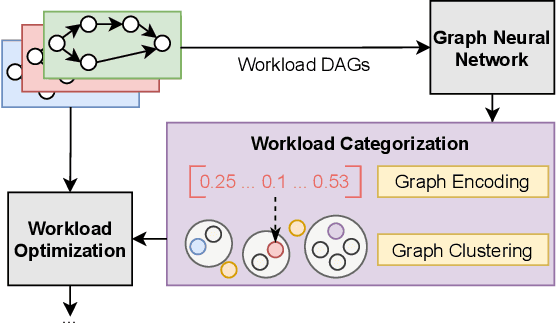
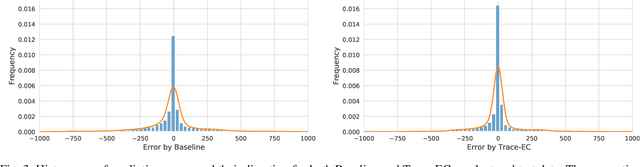
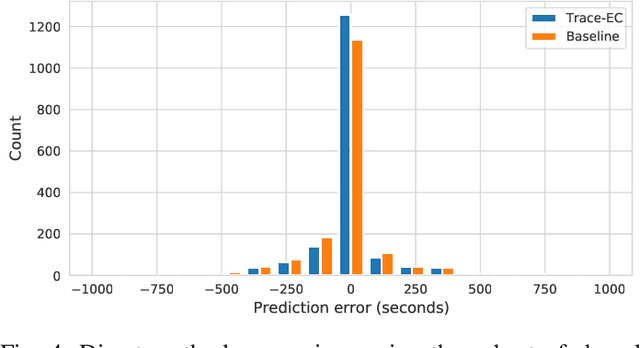
With the growing amount of data, data processing workloads and the management of their resource usage becomes increasingly important. Since managing a dedicated infrastructure is in many situations infeasible or uneconomical, users progressively execute their respective workloads in the cloud. As the configuration of workloads and resources is often challenging, various methods have been proposed that either quickly profile towards a good configuration or determine one based on data from previous runs. Still, performance data to train such methods is often lacking and must be costly collected. In this paper, we propose a collaborative approach for sharing anonymized workload execution traces among users, mining them for general patterns, and exploiting clusters of historical workloads for future optimizations. We evaluate our prototype implementation for mining workload execution graphs on a publicly available trace dataset and demonstrate the predictive value of workload clusters determined through traces only.