 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonitoring Emergent Reward Hacking During Generation via Internal Activations
Mar 04, 2026Fine-tuned large language models can exhibit reward-hacking behavior arising from emergent misalignment, which is difficult to detect from final outputs alone. While prior work has studied reward hacking at the level of completed responses, it remains unclear whether such behavior can be identified during generation. We propose an activation-based monitoring approach that detects reward-hacking signals from internal representations as a model generates its response. Our method trains sparse autoencoders on residual stream activations and applies lightweight linear classifiers to produce token-level estimates of reward-hacking activity. Across multiple model families and fine-tuning mixtures, we find that internal activation patterns reliably distinguish reward-hacking from benign behavior, generalize to unseen mixed-policy adapters, and exhibit model-dependent temporal structure during chain-of-thought reasoning. Notably, reward-hacking signals often emerge early, persist throughout reasoning, and can be amplified by increased test-time compute in the form of chain-of-thought prompting under weakly specified reward objectives. These results suggest that internal activation monitoring provides a complementary and earlier signal of emergent misalignment than output-based evaluation, supporting more robust post-deployment safety monitoring for fine-tuned language models.
LogRCA: Log-based Root Cause Analysis for Distributed Services
May 22, 2024To assist IT service developers and operators in managing their increasingly complex service landscapes, there is a growing effort to leverage artificial intelligence in operations. To speed up troubleshooting, log anomaly detection has received much attention in particular, dealing with the identification of log events that indicate the reasons for a system failure. However, faults often propagate extensively within systems, which can result in a large number of anomalies being detected by existing approaches. In this case, it can remain very challenging for users to quickly identify the actual root cause of a failure. We propose LogRCA, a novel method for identifying a minimal set of log lines that together describe a root cause. LogRCA uses a semi-supervised learning approach to deal with rare and unknown errors and is designed to handle noisy data. We evaluated our approach on a large-scale production log data set of 44.3 million log lines, which contains 80 failures, whose root causes were labeled by experts. LogRCA consistently outperforms baselines based on deep learning and statistical analysis in terms of precision and recall to detect candidate root causes. In addition, we investigated the impact of our deployed data balancing approach, demonstrating that it considerably improves performance on rare failures.
Progressing from Anomaly Detection to Automated Log Labeling and Pioneering Root Cause Analysis
Dec 22, 2023The realm of AIOps is transforming IT landscapes with the power of AI and ML. Despite the challenge of limited labeled data, supervised models show promise, emphasizing the importance of leveraging labels for training, especially in deep learning contexts. This study enhances the field by introducing a taxonomy for log anomalies and exploring automated data labeling to mitigate labeling challenges. It goes further by investigating the potential of diverse anomaly detection techniques and their alignment with specific anomaly types. However, the exploration doesn't stop at anomaly detection. The study envisions a future where root cause analysis follows anomaly detection, unraveling the underlying triggers of anomalies. This uncharted territory holds immense potential for revolutionizing IT systems management. In essence, this paper enriches our understanding of anomaly detection, and automated labeling, and sets the stage for transformative root cause analysis. Together, these advances promise more resilient IT systems, elevating operational efficiency and user satisfaction in an ever-evolving technological landscape.
Karasu: A Collaborative Approach to Efficient Cluster Configuration for Big Data Analytics
Aug 22, 2023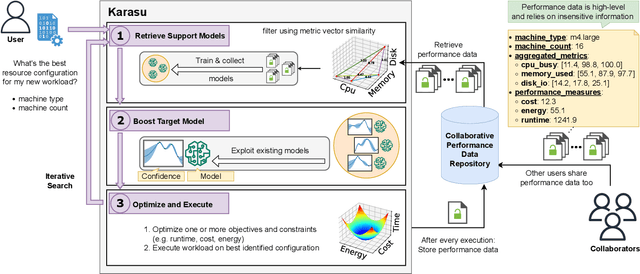
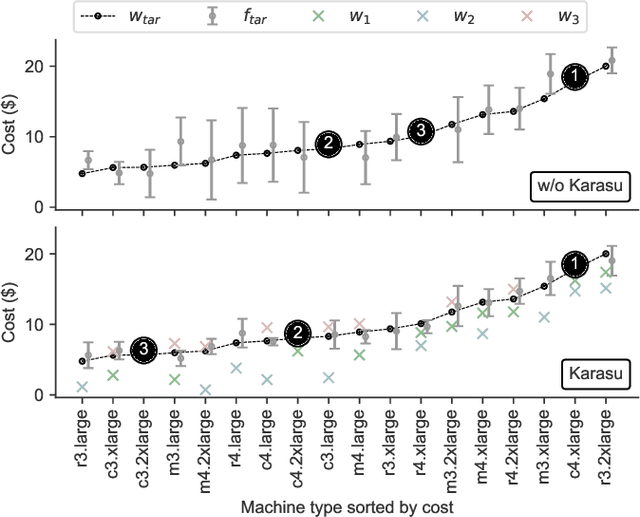
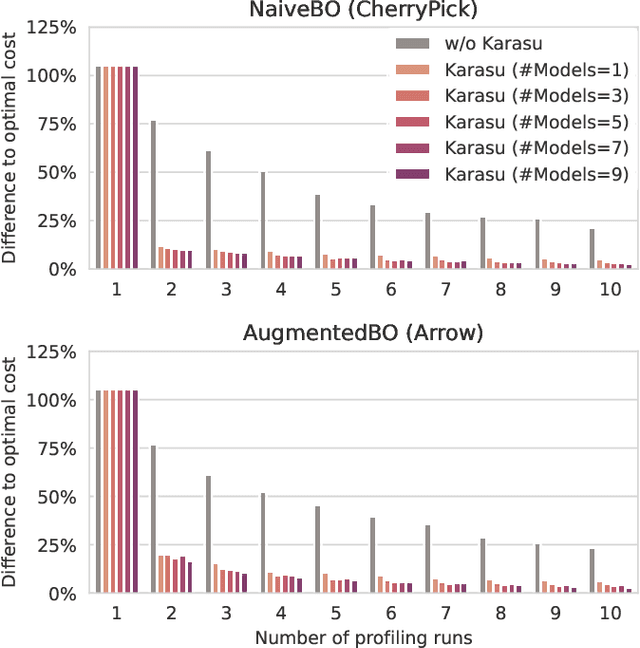
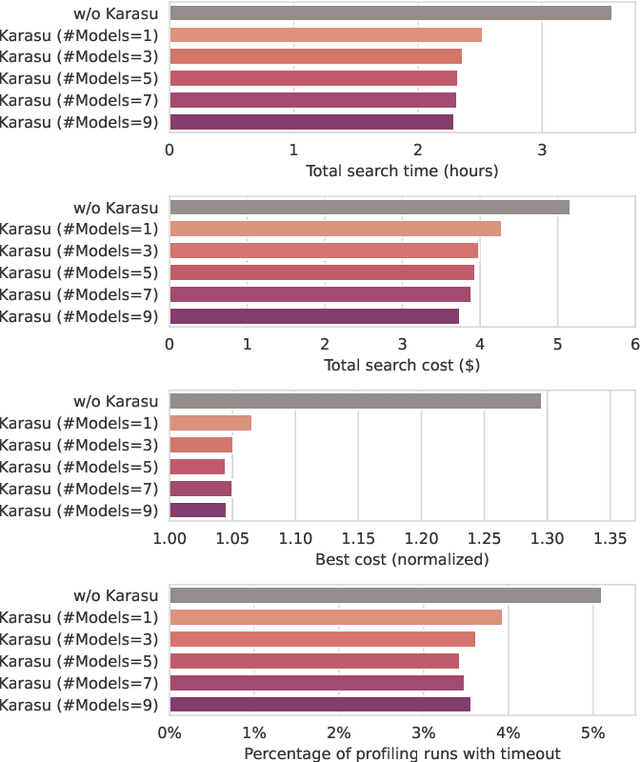
Selecting the right resources for big data analytics jobs is hard because of the wide variety of configuration options like machine type and cluster size. As poor choices can have a significant impact on resource efficiency, cost, and energy usage, automated approaches are gaining popularity. Most existing methods rely on profiling recurring workloads to find near-optimal solutions over time. Due to the cold-start problem, this often leads to lengthy and costly profiling phases. However, big data analytics jobs across users can share many common properties: they often operate on similar infrastructure, using similar algorithms implemented in similar frameworks. The potential in sharing aggregated profiling runs to collaboratively address the cold start problem is largely unexplored. We present Karasu, an approach to more efficient resource configuration profiling that promotes data sharing among users working with similar infrastructures, frameworks, algorithms, or datasets. Karasu trains lightweight performance models using aggregated runtime information of collaborators and combines them into an ensemble method to exploit inherent knowledge of the configuration search space. Moreover, Karasu allows the optimization of multiple objectives simultaneously. Our evaluation is based on performance data from diverse workload executions in a public cloud environment. We show that Karasu is able to significantly boost existing methods in terms of performance, search time, and cost, even when few comparable profiling runs are available that share only partial common characteristics with the target job.
PULL: Reactive Log Anomaly Detection Based On Iterative PU Learning
Jan 25, 2023Due to the complexity of modern IT services, failures can be manifold, occur at any stage, and are hard to detect. For this reason, anomaly detection applied to monitoring data such as logs allows gaining relevant insights to improve IT services steadily and eradicate failures. However, existing anomaly detection methods that provide high accuracy often rely on labeled training data, which are time-consuming to obtain in practice. Therefore, we propose PULL, an iterative log analysis method for reactive anomaly detection based on estimated failure time windows provided by monitoring systems instead of labeled data. Our attention-based model uses a novel objective function for weak supervision deep learning that accounts for imbalanced data and applies an iterative learning strategy for positive and unknown samples (PU learning) to identify anomalous logs. Our evaluation shows that PULL consistently outperforms ten benchmark baselines across three different datasets and detects anomalous log messages with an F1-score of more than 0.99 even within imprecise failure time windows.
A Taxonomy of Anomalies in Log Data
Nov 26, 2021Log data anomaly detection is a core component in the area of artificial intelligence for IT operations. However, the large amount of existing methods makes it hard to choose the right approach for a specific system. A better understanding of different kinds of anomalies, and which algorithms are suitable for detecting them, would support researchers and IT operators. Although a common taxonomy for anomalies already exists, it has not yet been applied specifically to log data, pointing out the characteristics and peculiarities in this domain. In this paper, we present a taxonomy for different kinds of log data anomalies and introduce a method for analyzing such anomalies in labeled datasets. We applied our taxonomy to the three common benchmark datasets Thunderbird, Spirit, and BGL, and trained five state-of-the-art unsupervised anomaly detection algorithms to evaluate their performance in detecting different kinds of anomalies. Our results show, that the most common anomaly type is also the easiest to predict. Moreover, deep learning-based approaches outperform data mining-based approaches in all anomaly types, but especially when it comes to detecting contextual anomalies.
LogLAB: Attention-Based Labeling of Log Data Anomalies via Weak Supervision
Nov 25, 2021With increasing scale and complexity of cloud operations, automated detection of anomalies in monitoring data such as logs will be an essential part of managing future IT infrastructures. However, many methods based on artificial intelligence, such as supervised deep learning models, require large amounts of labeled training data to perform well. In practice, this data is rarely available because labeling log data is expensive, time-consuming, and requires a deep understanding of the underlying system. We present LogLAB, a novel modeling approach for automated labeling of log messages without requiring manual work by experts. Our method relies on estimated failure time windows provided by monitoring systems to produce precise labeled datasets in retrospect. It is based on the attention mechanism and uses a custom objective function for weak supervision deep learning techniques that accounts for imbalanced data. Our evaluation shows that LogLAB consistently outperforms nine benchmark approaches across three different datasets and maintains an F1-score of more than 0.98 even at large failure time windows.
* Paper accepted on ICSOC 2021 and published on springer
On the Potential of Execution Traces for Batch Processing Workload Optimization in Public Clouds
Nov 16, 2021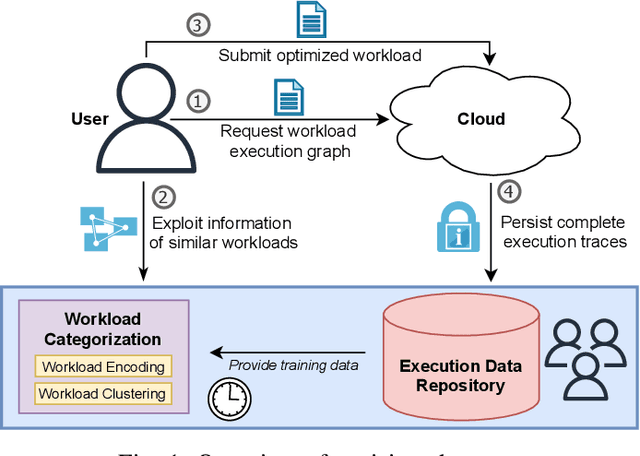
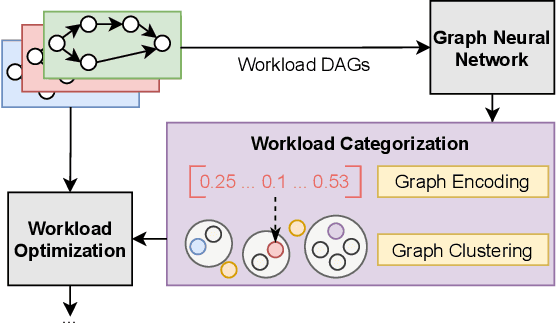
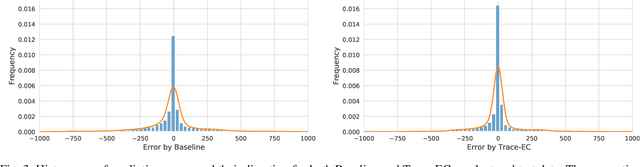
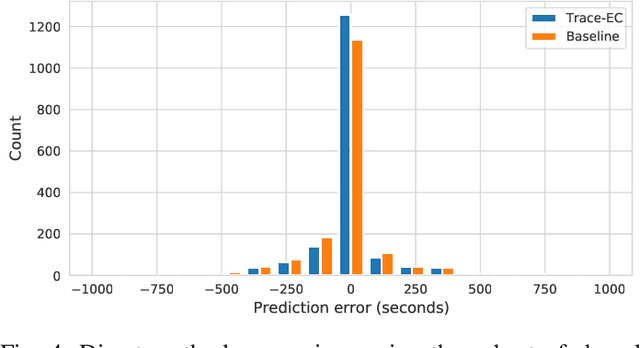
With the growing amount of data, data processing workloads and the management of their resource usage becomes increasingly important. Since managing a dedicated infrastructure is in many situations infeasible or uneconomical, users progressively execute their respective workloads in the cloud. As the configuration of workloads and resources is often challenging, various methods have been proposed that either quickly profile towards a good configuration or determine one based on data from previous runs. Still, performance data to train such methods is often lacking and must be costly collected. In this paper, we propose a collaborative approach for sharing anonymized workload execution traces among users, mining them for general patterns, and exploiting clusters of historical workloads for future optimizations. We evaluate our prototype implementation for mining workload execution graphs on a publicly available trace dataset and demonstrate the predictive value of workload clusters determined through traces only.
A2Log: Attentive Augmented Log Anomaly Detection
Sep 20, 2021Anomaly detection becomes increasingly important for the dependability and serviceability of IT services. As log lines record events during the execution of IT services, they are a primary source for diagnostics. Thereby, unsupervised methods provide a significant benefit since not all anomalies can be known at training time. Existing unsupervised methods need anomaly examples to obtain a suitable decision boundary required for the anomaly detection task. This requirement poses practical limitations. Therefore, we develop A2Log, which is an unsupervised anomaly detection method consisting of two steps: Anomaly scoring and anomaly decision. First, we utilize a self-attention neural network to perform the scoring for each log message. Second, we set the decision boundary based on data augmentation of the available normal training data. The method is evaluated on three publicly available datasets and one industry dataset. We show that our approach outperforms existing methods. Furthermore, we utilize available anomaly examples to set optimal decision boundaries to acquire strong baselines. We show that our approach, which determines decision boundaries without utilizing anomaly examples, can reach scores of the strong baselines.
Bellamy: Reusing Performance Models for Distributed Dataflow Jobs Across Contexts
Jul 29, 2021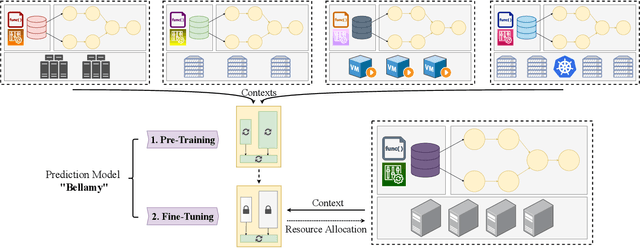
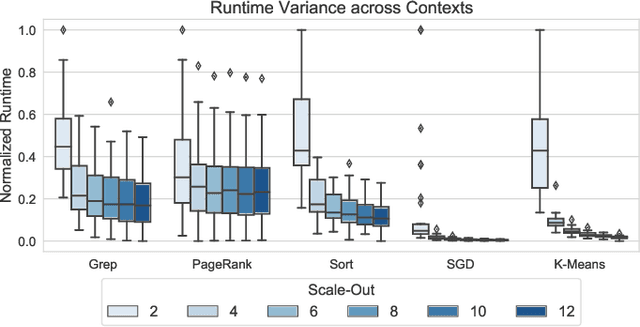
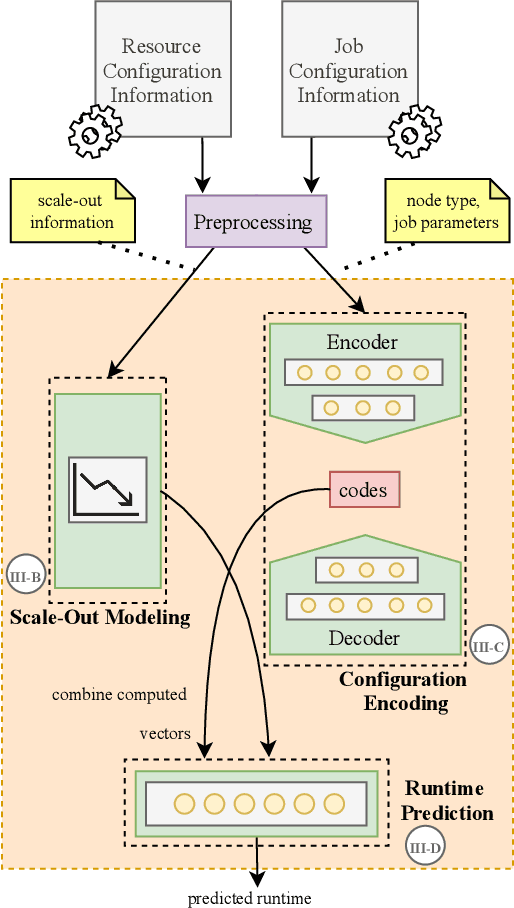
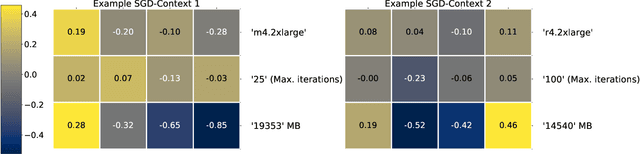
Distributed dataflow systems enable the use of clusters for scalable data analytics. However, selecting appropriate cluster resources for a processing job is often not straightforward. Performance models trained on historical executions of a concrete job are helpful in such situations, yet they are usually bound to a specific job execution context (e.g. node type, software versions, job parameters) due to the few considered input parameters. Even in case of slight context changes, such supportive models need to be retrained and cannot benefit from historical execution data from related contexts. This paper presents Bellamy, a novel modeling approach that combines scale-outs, dataset sizes, and runtimes with additional descriptive properties of a dataflow job. It is thereby able to capture the context of a job execution. Moreover, Bellamy is realizing a two-step modeling approach. First, a general model is trained on all the available data for a specific scalable analytics algorithm, hereby incorporating data from different contexts. Subsequently, the general model is optimized for the specific situation at hand, based on the available data for the concrete context. We evaluate our approach on two publicly available datasets consisting of execution data from various dataflow jobs carried out in different environments, showing that Bellamy outperforms state-of-the-art methods.