 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat happens when nanochat meets DiLoCo?
Nov 14, 2025Although LLM training is typically centralized with high-bandwidth interconnects and large compute budgets, emerging methods target communication-constrained training in distributed environments. The model trade-offs introduced by this shift remain underexplored, and our goal is to study them. We use the open-source nanochat project, a compact 8K-line full-stack ChatGPT-like implementation containing tokenization, pretraining, fine-tuning, and serving, as a controlled baseline. We implement the DiLoCo algorithm as a lightweight wrapper over nanochat's training loop, performing multiple local steps per worker before synchronization with an outer optimizer, effectively reducing communication by orders of magnitude. This inner-outer training is compared against a standard data-parallel (DDP) setup. Because nanochat is small and inspectable, it enables controlled pipeline adaptations and allows direct comparison with the conventional centralized baseline. DiLoCo achieves stable convergence and competitive loss in pretraining but yields worse MMLU, GSM8K, and HumanEval scores after mid-training and SFT. We discover that using DiLoCo-pretrained weights and running mid- and post-training with DDP fails to recover performance, revealing irreversible representation drift from asynchronous updates that impairs downstream alignment. We provide this implementation as an official fork of nanochat on GitHub.
Leveraging Log Instructions in Log-based Anomaly Detection
Jul 07, 2022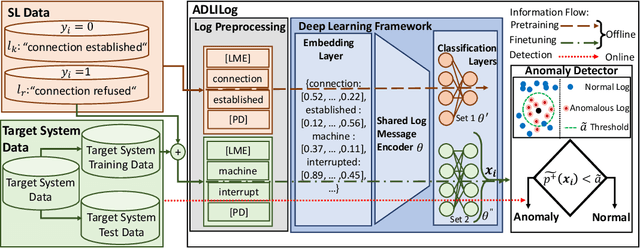
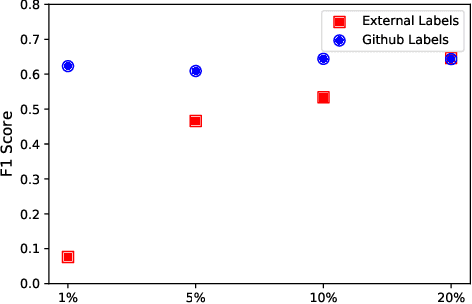
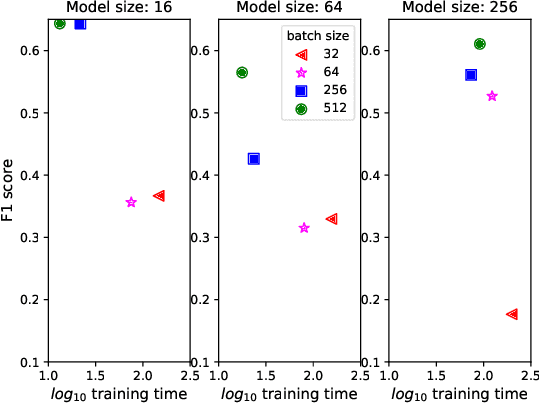

Artificial Intelligence for IT Operations (AIOps) describes the process of maintaining and operating large IT systems using diverse AI-enabled methods and tools for, e.g., anomaly detection and root cause analysis, to support the remediation, optimization, and automatic initiation of self-stabilizing IT activities. The core step of any AIOps workflow is anomaly detection, typically performed on high-volume heterogeneous data such as log messages (logs), metrics (e.g., CPU utilization), and distributed traces. In this paper, we propose a method for reliable and practical anomaly detection from system logs. It overcomes the common disadvantage of related works, i.e., the need for a large amount of manually labeled training data, by building an anomaly detection model with log instructions from the source code of 1000+ GitHub projects. The instructions from diverse systems contain rich and heterogenous information about many different normal and abnormal IT events and serve as a foundation for anomaly detection. The proposed method, named ADLILog, combines the log instructions and the data from the system of interest (target system) to learn a deep neural network model through a two-phase learning procedure. The experimental results show that ADLILog outperforms the related approaches by up to 60% on the F1 score while satisfying core non-functional requirements for industrial deployments such as unsupervised design, efficient model updates, and small model sizes.
Failure Identification from Unstable Log Data using Deep Learning
Apr 06, 2022
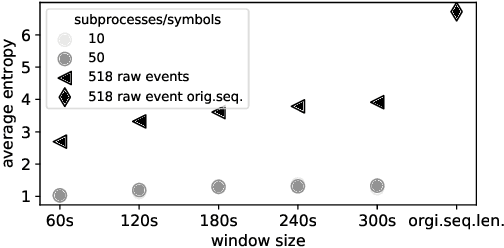
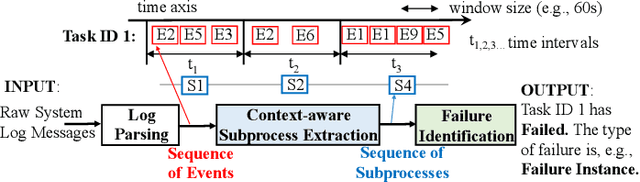
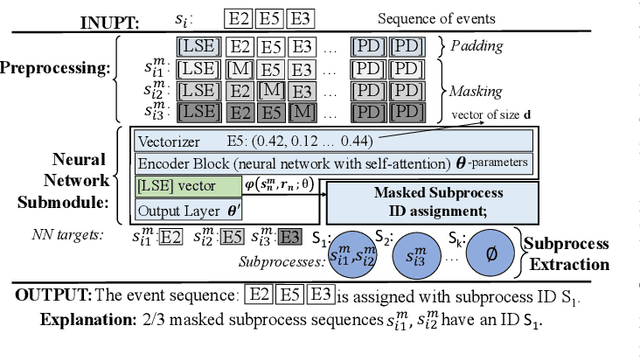
The reliability of cloud platforms is of significant relevance because society increasingly relies on complex software systems running on the cloud. To improve it, cloud providers are automating various maintenance tasks, with failure identification frequently being considered. The precondition for automation is the availability of observability tools, with system logs commonly being used. The focus of this paper is log-based failure identification. This problem is challenging because of the instability of the log data and the incompleteness of the explicit logging failure coverage within the code. To address the two challenges, we present CLog as a method for failure identification. The key idea presented herein based is on our observation that by representing the log data as sequences of subprocesses instead of sequences of log events, the effect of the unstable log data is reduced. CLog introduces a novel subprocess extraction method that uses context-aware neural network and clustering methods to extract meaningful subprocesses. The direct modeling of log event contexts allows the identification of failures with respect to the abrupt context changes, addressing the challenge of insufficient logging failure coverage. Our experimental results demonstrate that the learned subprocesses representations reduce the instability in the input, allowing CLog to outperform the baselines on the failure identification subproblems - 1) failure detection by 9-24% on F1 score and 2) failure type identification by 7% on the macro averaged F1 score. Further analysis shows the existent negative correlation between the instability in the input event sequences and the detection performance in a model-agnostic manner.
Data-Driven Approach for Log Instruction Quality Assessment
Apr 06, 2022
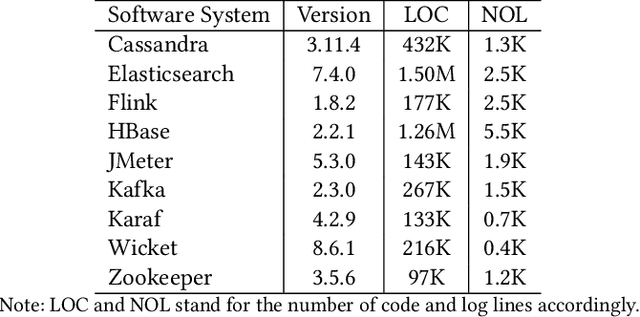

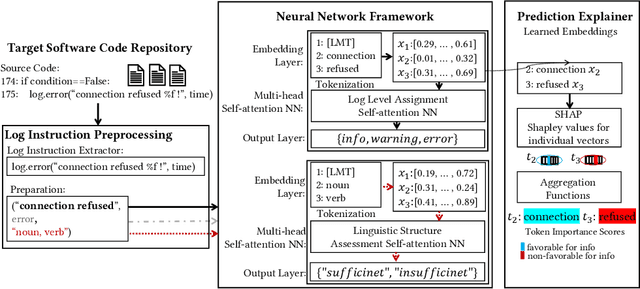
In the current IT world, developers write code while system operators run the code mostly as a black box. The connection between both worlds is typically established with log messages: the developer provides hints to the (unknown) operator, where the cause of an occurred issue is, and vice versa, the operator can report bugs during operation. To fulfil this purpose, developers write log instructions that are structured text commonly composed of a log level (e.g., "info", "error"), static text ("IP {} cannot be reached"), and dynamic variables (e.g. IP {}). However, as opposed to well-adopted coding practices, there are no widely adopted guidelines on how to write log instructions with good quality properties. For example, a developer may assign a high log level (e.g., "error") for a trivial event that can confuse the operator and increase maintenance costs. Or the static text can be insufficient to hint at a specific issue. In this paper, we address the problem of log quality assessment and provide the first step towards its automation. We start with an in-depth analysis of quality log instruction properties in nine software systems and identify two quality properties: 1) correct log level assignment assessing the correctness of the log level, and 2) sufficient linguistic structure assessing the minimal richness of the static text necessary for verbose event description. Based on these findings, we developed a data-driven approach that adapts deep learning methods for each of the two properties. An extensive evaluation on large-scale open-source systems shows that our approach correctly assesses log level assignments with an accuracy of 0.88, and the sufficient linguistic structure with an F1 score of 0.99, outperforming the baselines. Our study shows the potential of the data-driven methods in assessing instructions quality and aid developers in comprehending and writing better code.
A2Log: Attentive Augmented Log Anomaly Detection
Sep 20, 2021Anomaly detection becomes increasingly important for the dependability and serviceability of IT services. As log lines record events during the execution of IT services, they are a primary source for diagnostics. Thereby, unsupervised methods provide a significant benefit since not all anomalies can be known at training time. Existing unsupervised methods need anomaly examples to obtain a suitable decision boundary required for the anomaly detection task. This requirement poses practical limitations. Therefore, we develop A2Log, which is an unsupervised anomaly detection method consisting of two steps: Anomaly scoring and anomaly decision. First, we utilize a self-attention neural network to perform the scoring for each log message. Second, we set the decision boundary based on data augmentation of the available normal training data. The method is evaluated on three publicly available datasets and one industry dataset. We show that our approach outperforms existing methods. Furthermore, we utilize available anomaly examples to set optimal decision boundaries to acquire strong baselines. We show that our approach, which determines decision boundaries without utilizing anomaly examples, can reach scores of the strong baselines.
Robust and Transferable Anomaly Detection in Log Data using Pre-Trained Language Models
Feb 23, 2021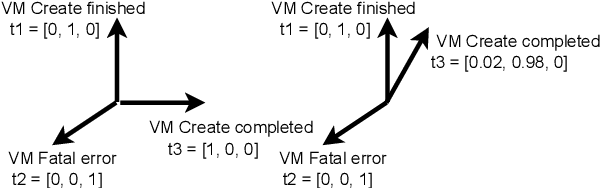
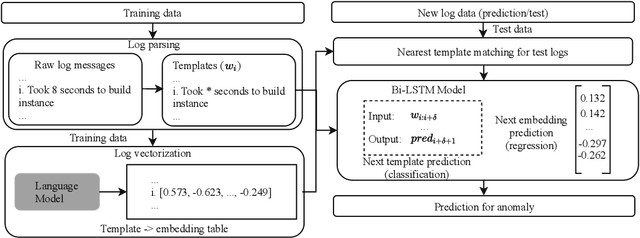
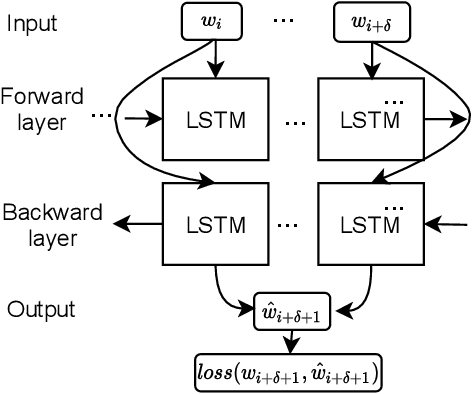

Anomalies or failures in large computer systems, such as the cloud, have an impact on a large number of users that communicate, compute, and store information. Therefore, timely and accurate anomaly detection is necessary for reliability, security, safe operation, and mitigation of losses in these increasingly important systems. Recently, the evolution of the software industry opens up several problems that need to be tackled including (1) addressing the software evolution due software upgrades, and (2) solving the cold-start problem, where data from the system of interest is not available. In this paper, we propose a framework for anomaly detection in log data, as a major troubleshooting source of system information. To that end, we utilize pre-trained general-purpose language models to preserve the semantics of log messages and map them into log vector embeddings. The key idea is that these representations for the logs are robust and less invariant to changes in the logs, and therefore, result in a better generalization of the anomaly detection models. We perform several experiments on a cloud dataset evaluating different language models for obtaining numerical log representations such as BERT, GPT-2, and XL. The robustness is evaluated by gradually altering log messages, to simulate a change in semantics. Our results show that the proposed approach achieves high performance and robustness, which opens up possibilities for future research in this direction.
Autoencoder-based Condition Monitoring and Anomaly Detection Method for Rotating Machines
Jan 27, 2021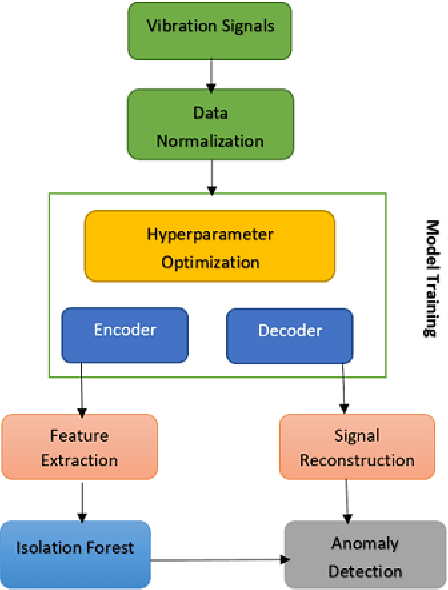
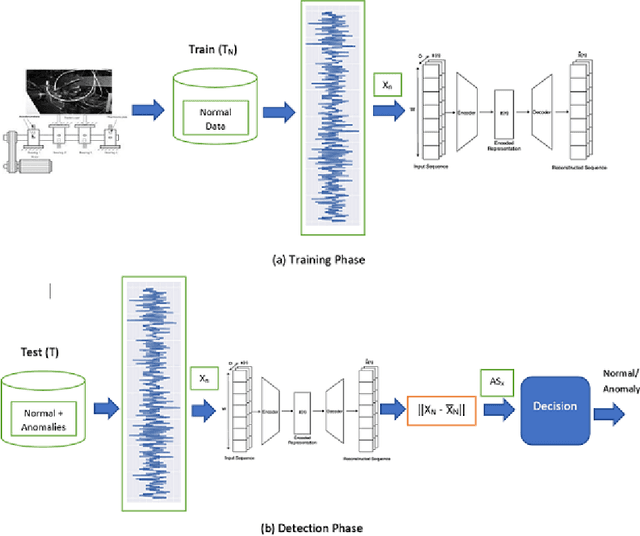
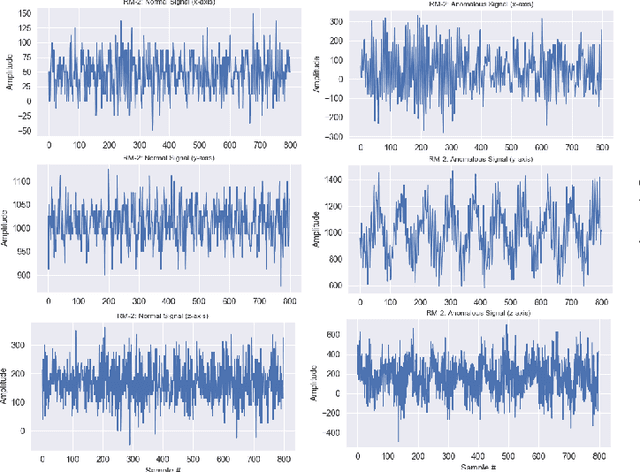
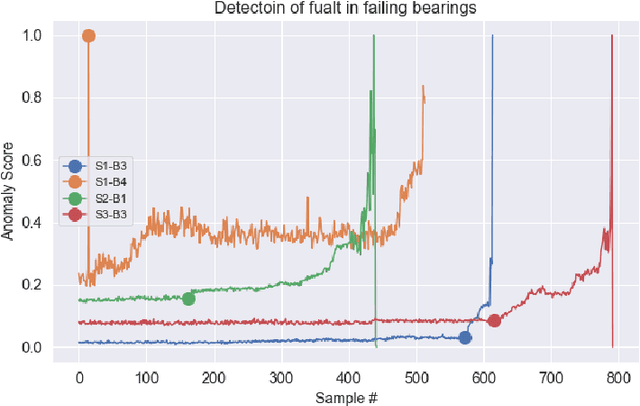
Rotating machines like engines, pumps, or turbines are ubiquitous in modern day societies. Their mechanical parts such as electrical engines, rotors, or bearings are the major components and any failure in them may result in their total shutdown. Anomaly detection in such critical systems is very important to monitor the system's health. As the requirement to obtain a dataset from rotating machines where all possible faults are explicitly labeled is difficult to satisfy, we propose a method that focuses on the normal behavior of the machine instead. We propose an autoencoder model-based method for condition monitoring of rotating machines by using an anomaly detection approach. The method learns the characteristics of a rotating machine using the normal vibration signals to model the healthy state of the machine. A threshold-based approach is then applied to the reconstruction error of unseen data, thus enabling the detection of unseen anomalies. The proposed method can directly extract the salient features from raw vibration signals and eliminate the need for manually engineered features. We demonstrate the effectiveness of the proposed method by employing two rotating machine datasets and the quality of the automatically learned features is compared with a set of handcrafted features by training an Isolation Forest model on either of these two sets. Experimental results on two real-world datasets indicate that our proposed solution gives promising results, achieving an average F1-score of 99.6%.
Artificial Intelligence for IT Operations (AIOPS) Workshop White Paper
Jan 15, 2021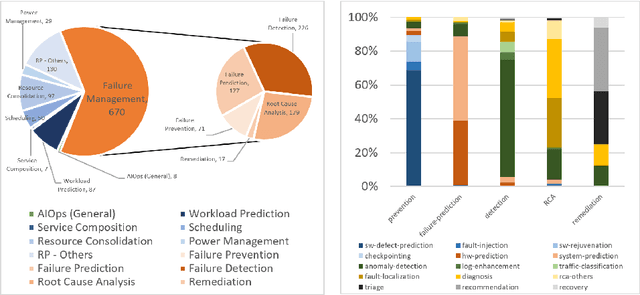
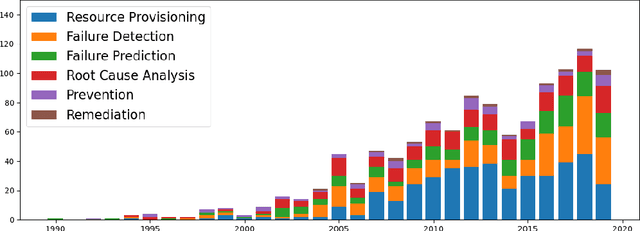
Artificial Intelligence for IT Operations (AIOps) is an emerging interdisciplinary field arising in the intersection between the research areas of machine learning, big data, streaming analytics, and the management of IT operations. AIOps, as a field, is a candidate to produce the future standard for IT operation management. To that end, AIOps has several challenges. First, it needs to combine separate research branches from other research fields like software reliability engineering. Second, novel modelling techniques are needed to understand the dynamics of different systems. Furthermore, it requires to lay out the basis for assessing: time horizons and uncertainty for imminent SLA violations, the early detection of emerging problems, autonomous remediation, decision making, support of various optimization objectives. Moreover, a good understanding and interpretability of these aiding models are important for building trust between the employed tools and the domain experts. Finally, all this will result in faster adoption of AIOps, further increase the interest in this research field and contribute to bridging the gap towards fully-autonomous operating IT systems. The main aim of the AIOPS workshop is to bring together researchers from both academia and industry to present their experiences, results, and work in progress in this field. The workshop aims to strengthen the community and unite it towards the goal of joining the efforts for solving the main challenges the field is currently facing. A consensus and adoption of the principles of openness and reproducibility will boost the research in this emerging area significantly.
Multi-Source Anomaly Detection in Distributed IT Systems
Jan 13, 2021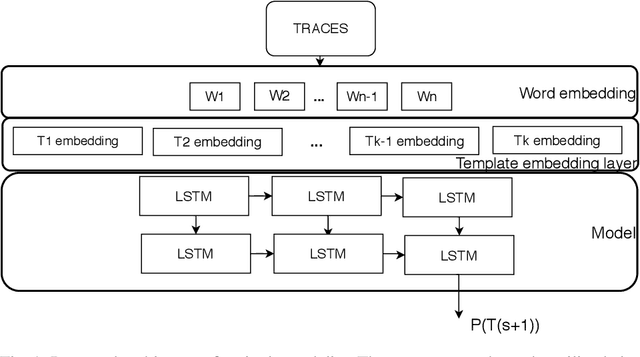
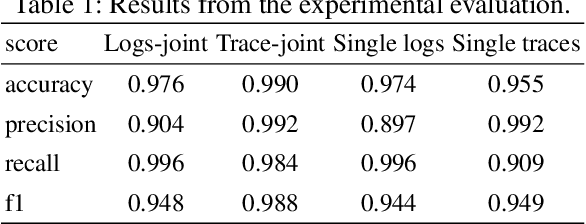
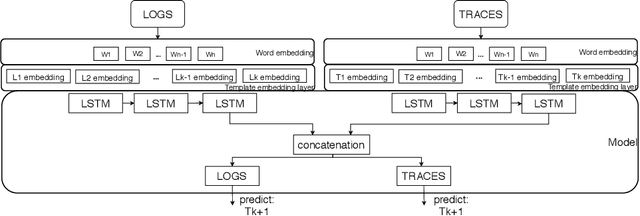
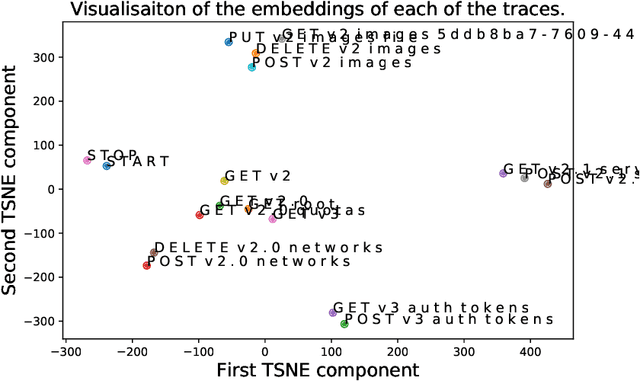
The multi-source data generated by distributed systems, provide a holistic description of the system. Harnessing the joint distribution of the different modalities by a learning model can be beneficial for critical applications for maintenance of the distributed systems. One such important task is the task of anomaly detection where we are interested in detecting the deviation of the current behaviour of the system from the theoretically expected. In this work, we utilize the joint representation from the distributed traces and system log data for the task of anomaly detection in distributed systems. We demonstrate that the joint utilization of traces and logs produced better results compared to the single modality anomaly detection methods. Furthermore, we formalize a learning task - next template prediction NTP, that is used as a generalization for anomaly detection for both logs and distributed trace. Finally, we demonstrate that this formalization allows for the learning of template embedding for both the traces and logs. The joint embeddings can be reused in other applications as good initialization for spans and logs.
Learning more expressive joint distributions in multimodal variational methods
Sep 08, 2020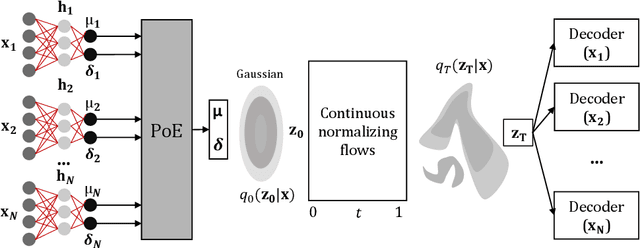

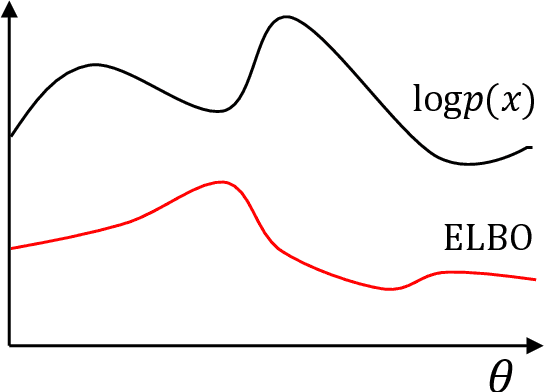

Data often are formed of multiple modalities, which jointly describe the observed phenomena. Modeling the joint distribution of multimodal data requires larger expressive power to capture high-level concepts and provide better data representations. However, multimodal generative models based on variational inference are limited due to the lack of flexibility of the approximate posterior, which is obtained by searching within a known parametric family of distributions. We introduce a method that improves the representational capacity of multimodal variational methods using normalizing flows. It approximates the joint posterior with a simple parametric distribution and subsequently transforms into a more complex one. Through several experiments, we demonstrate that the model improves on state-of-the-art multimodal methods based on variational inference on various computer vision tasks such as colorization, edge and mask detection, and weakly supervised learning. We also show that learning more powerful approximate joint distributions improves the quality of the generated samples. The code of our model is publicly available at https://github.com/SashoNedelkoski/BPFDMVM.