 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards AIOps in Edge Computing Environments
Feb 12, 2021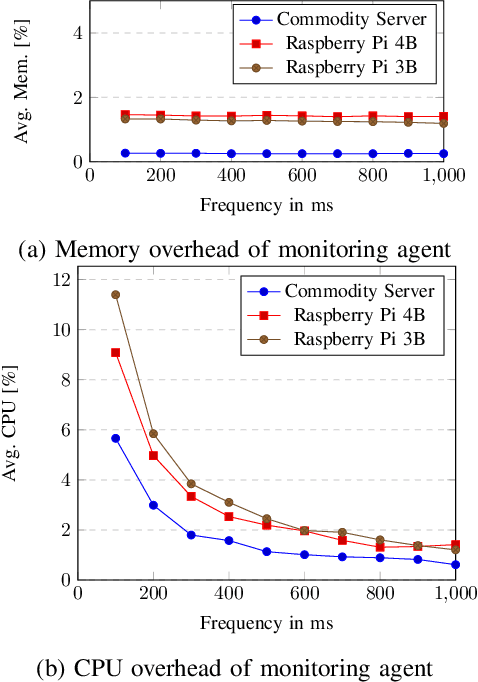
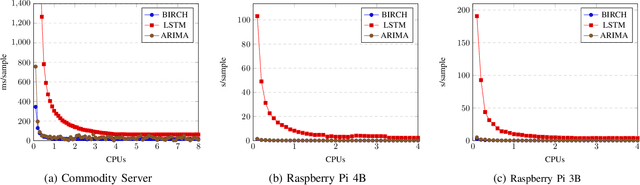
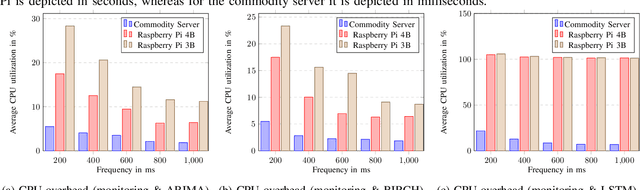
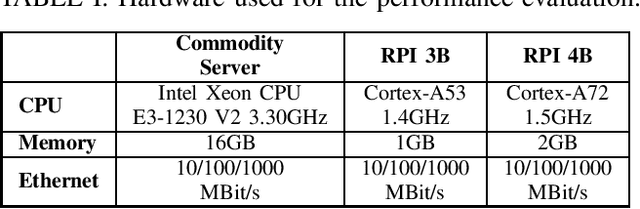
Edge computing was introduced as a technical enabler for the demanding requirements of new network technologies like 5G. It aims to overcome challenges related to centralized cloud computing environments by distributing computational resources to the edge of the network towards the customers. The complexity of the emerging infrastructures increases significantly, together with the ramifications of outages on critical use cases such as self-driving cars or health care. Artificial Intelligence for IT Operations (AIOps) aims to support human operators in managing complex infrastructures by using machine learning methods. This paper describes the system design of an AIOps platform which is applicable in heterogeneous, distributed environments. The overhead of a high-frequency monitoring solution on edge devices is evaluated and performance experiments regarding the applicability of three anomaly detection algorithms on edge devices are conducted. The results show, that it is feasible to collect metrics with a high frequency and simultaneously run specific anomaly detection algorithms directly on edge devices with a reasonable overhead on the resource utilization.
Optimizing Convergence for Iterative Learning of ARIMA for Stationary Time Series
Jan 25, 2021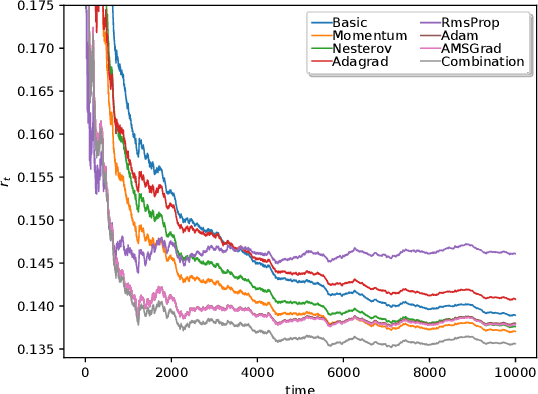
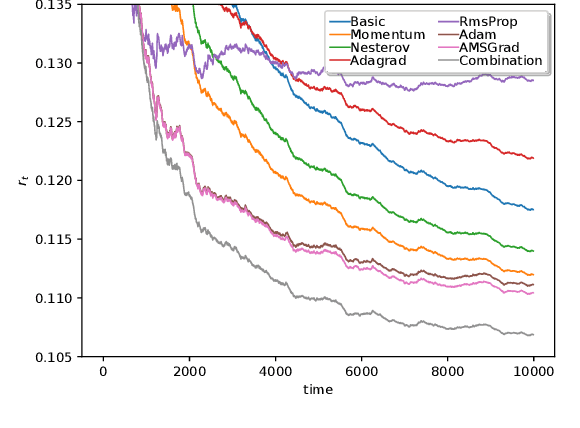
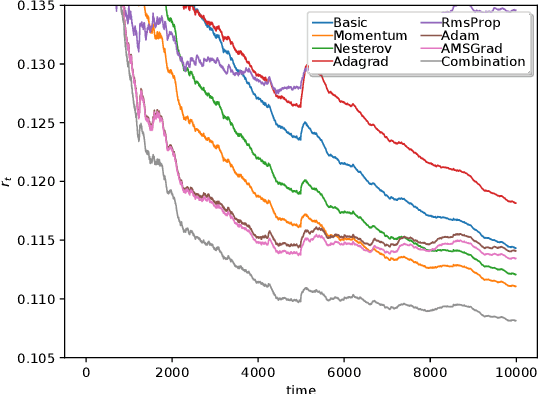
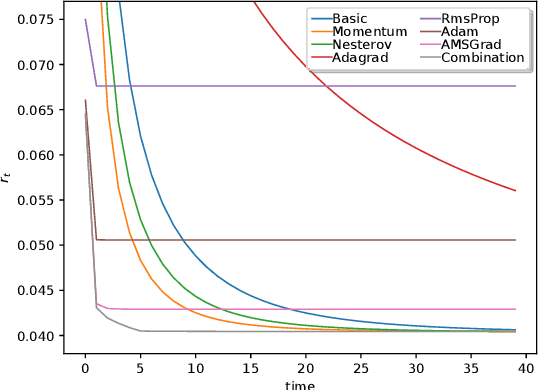
Forecasting of time series in continuous systems becomes an increasingly relevant task due to recent developments in IoT and 5G. The popular forecasting model ARIMA is applied to a large variety of applications for decades. An online variant of ARIMA applies the Online Newton Step in order to learn the underlying process of the time series. This optimization method has pitfalls concerning the computational complexity and convergence. Thus, this work focuses on the computational less expensive Online Gradient Descent optimization method, which became popular for learning of neural networks in recent years. For the iterative training of such models, we propose a new approach combining different Online Gradient Descent learners (such as Adam, AMSGrad, Adagrad, Nesterov) to achieve fast convergence. The evaluation on synthetic data and experimental datasets show that the proposed approach outperforms the existing methods resulting in an overall lower prediction error.
Artificial Intelligence for IT Operations (AIOPS) Workshop White Paper
Jan 15, 2021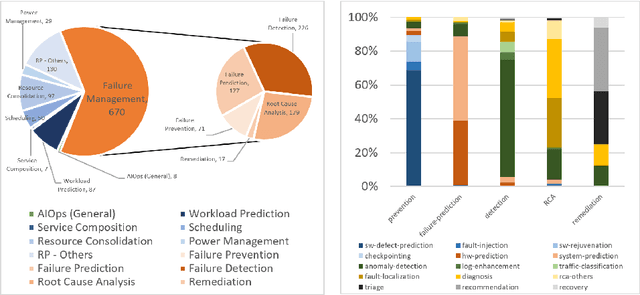
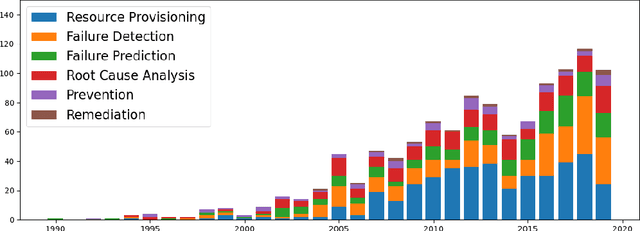
Artificial Intelligence for IT Operations (AIOps) is an emerging interdisciplinary field arising in the intersection between the research areas of machine learning, big data, streaming analytics, and the management of IT operations. AIOps, as a field, is a candidate to produce the future standard for IT operation management. To that end, AIOps has several challenges. First, it needs to combine separate research branches from other research fields like software reliability engineering. Second, novel modelling techniques are needed to understand the dynamics of different systems. Furthermore, it requires to lay out the basis for assessing: time horizons and uncertainty for imminent SLA violations, the early detection of emerging problems, autonomous remediation, decision making, support of various optimization objectives. Moreover, a good understanding and interpretability of these aiding models are important for building trust between the employed tools and the domain experts. Finally, all this will result in faster adoption of AIOps, further increase the interest in this research field and contribute to bridging the gap towards fully-autonomous operating IT systems. The main aim of the AIOPS workshop is to bring together researchers from both academia and industry to present their experiences, results, and work in progress in this field. The workshop aims to strengthen the community and unite it towards the goal of joining the efforts for solving the main challenges the field is currently facing. A consensus and adoption of the principles of openness and reproducibility will boost the research in this emerging area significantly.
The voice of COVID-19: Acoustic correlates of infection
Dec 17, 2020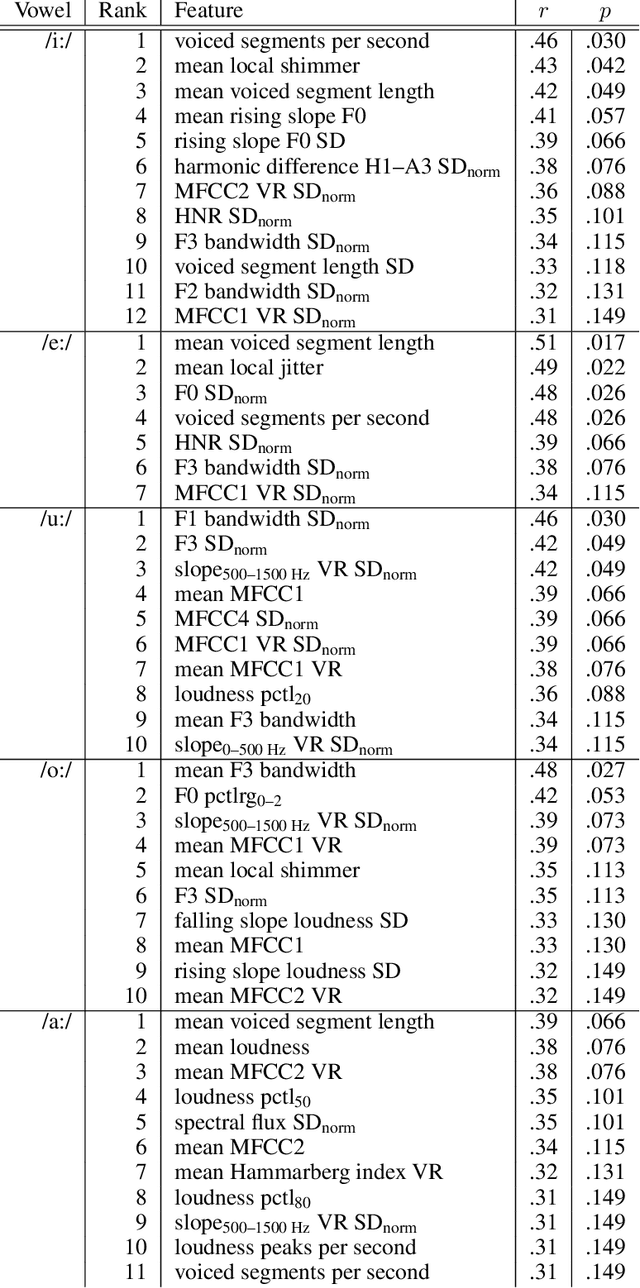
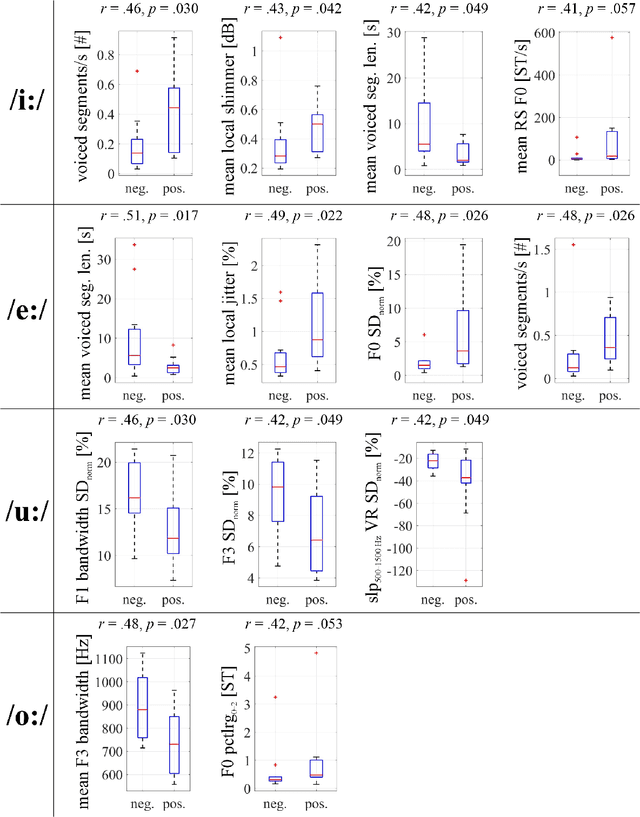
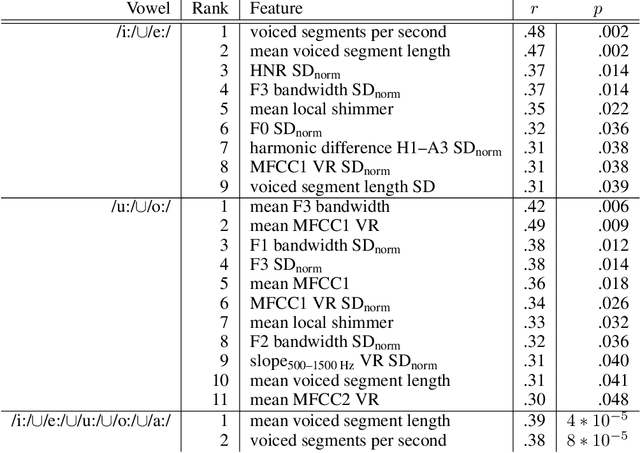
COVID-19 is a global health crisis that has been affecting many aspects of our daily lives throughout the past year. The symptomatology of COVID-19 is heterogeneous with a severity continuum. A considerable proportion of symptoms are related to pathological changes in the vocal system, leading to the assumption that COVID-19 may also affect voice production. For the very first time, the present study aims to investigate voice acoustic correlates of an infection with COVID-19 on the basis of a comprehensive acoustic parameter set. We compare 88 acoustic features extracted from recordings of the vowels /i:/, /e:/, /o:/, /u:/, and /a:/ produced by 11 symptomatic COVID-19 positive and 11 COVID-19 negative German-speaking participants. We employ the Mann-Whitney U test and calculate effect sizes to identify features with the most prominent group differences. The mean voiced segment length and the number of voiced segments per second yield the most important differences across all vowels indicating discontinuities in the pulmonic airstream during phonation in COVID-19 positive participants. Group differences in the front vowels /i:/ and /e:/ are additionally reflected in the variation of the fundamental frequency and the harmonics-to-noise ratio, group differences in back vowels /o:/ and /u:/ in statistics of the Mel-frequency cepstral coefficients and the spectral slope. Findings of this study can be considered an important proof-of-concept contribution for a potential future voice-based identification of individuals infected with COVID-19.
BERT as a Teacher: Contextual Embeddings for Sequence-Level Reward
Mar 05, 2020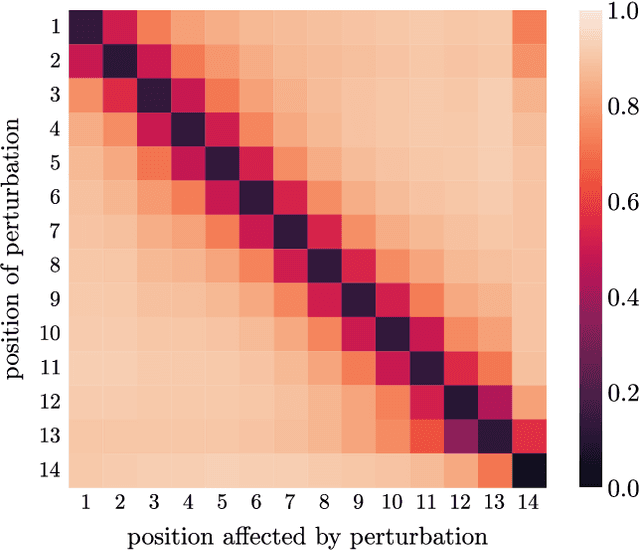

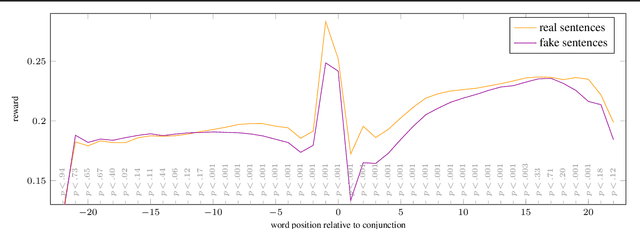

Measuring the quality of a generated sequence against a set of references is a central problem in many learning frameworks, be it to compute a score, to assign a reward, or to perform discrimination. Despite great advances in model architectures, metrics that scale independently of the number of references are still based on n-gram estimates. We show that the underlying operations, counting words and comparing counts, can be lifted to embedding words and comparing embeddings. An in-depth analysis of BERT embeddings shows empirically that contextual embeddings can be employed to capture the required dependencies while maintaining the necessary scalability through appropriate pruning and smoothing techniques. We cast unconditional generation as a reinforcement learning problem and show that our reward function indeed provides a more effective learning signal than n-gram reward in this challenging setting.
Generalization in Generation: A closer look at Exposure Bias
Nov 07, 2019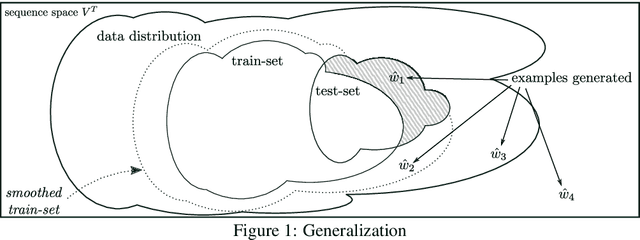
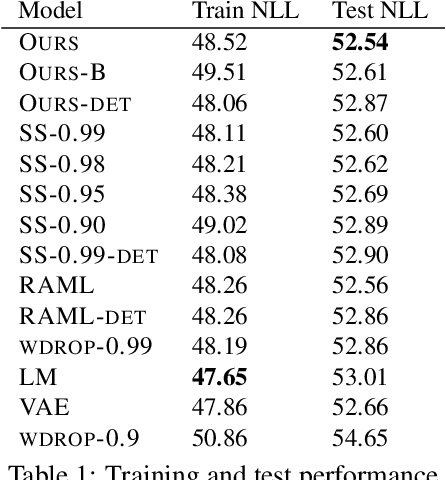
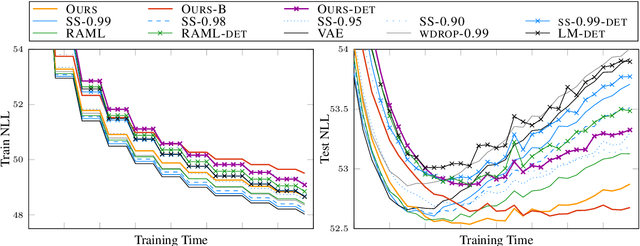
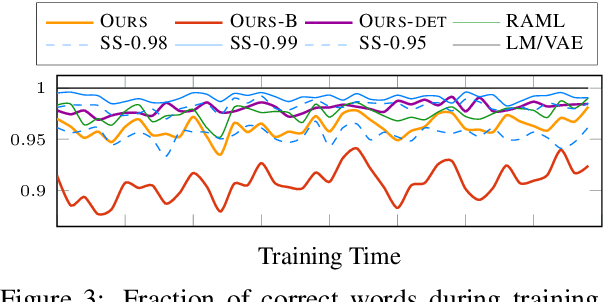
Exposure bias refers to the train-test discrepancy that seemingly arises when an autoregressive generative model uses only ground-truth contexts at training time but generated ones at test time. We separate the contributions of the model and the learning framework to clarify the debate on consequences and review proposed counter-measures. In this light, we argue that generalization is the underlying property to address and propose unconditional generation as its fundamental benchmark. Finally, we combine latent variable modeling with a recent formulation of exploration in reinforcement learning to obtain a rigorous handling of true and generated contexts. Results on language modeling and variational sentence auto-encoding confirm the model's generalization capability.
Autoregressive Text Generation Beyond Feedback Loops
Aug 30, 2019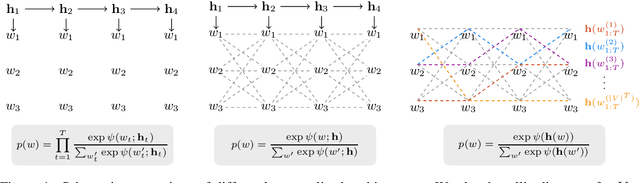
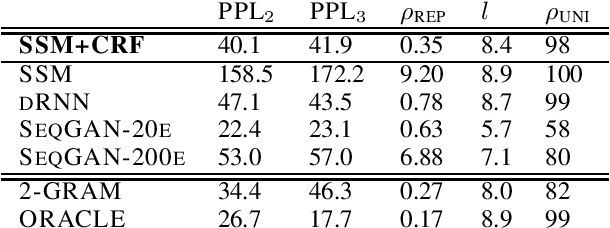
Autoregressive state transitions, where predictions are conditioned on past predictions, are the predominant choice for both deterministic and stochastic sequential models. However, autoregressive feedback exposes the evolution of the hidden state trajectory to potential biases from well-known train-test discrepancies. In this paper, we combine a latent state space model with a CRF observation model. We argue that such autoregressive observation models form an interesting middle ground that expresses local correlations on the word level but keeps the state evolution non-autoregressive. On unconditional sentence generation we show performance improvements compared to RNN and GAN baselines while avoiding some prototypical failure modes of autoregressive models.
Deep State Space Models for Unconditional Word Generation
Oct 28, 2018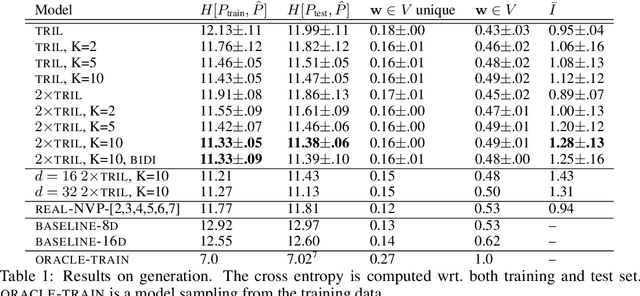


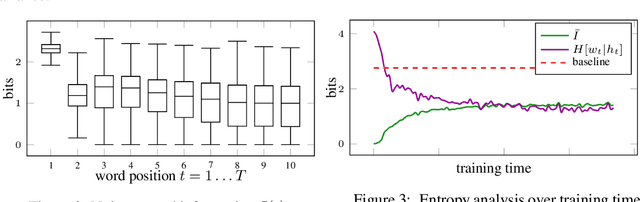
Autoregressive feedback is considered a necessity for successful unconditional text generation using stochastic sequence models. However, such feedback is known to introduce systematic biases into the training process and it obscures a principle of generation: committing to global information and forgetting local nuances. We show that a non-autoregressive deep state space model with a clear separation of global and local uncertainty can be built from only two ingredients: An independent noise source and a deterministic transition function. Recent advances on flow-based variational inference can be used to train an evidence lower-bound without resorting to annealing, auxiliary losses or similar measures. The result is a highly interpretable generative model on par with comparable auto-regressive models on the task of word generation.
Grand Challenge: Real-time Destination and ETA Prediction for Maritime Traffic
Oct 12, 2018In this paper, we present our approach for solving the DEBS Grand Challenge 2018. The challenge asks to provide a prediction for (i) a destination and the (ii) arrival time of ships in a streaming-fashion using Geo-spatial data in the maritime context. Novel aspects of our approach include the use of ensemble learning based on Random Forest, Gradient Boosting Decision Trees (GBDT), XGBoost Trees and Extremely Randomized Trees (ERT) in order to provide a prediction for a destination while for the arrival time, we propose the use of Feed-forward Neural Networks. In our evaluation, we were able to achieve an accuracy of 97% for the port destination classification problem and 90% (in mins) for the ETA prediction.
BrainSlug: Transparent Acceleration of Deep Learning Through Depth-First Parallelism
Apr 23, 2018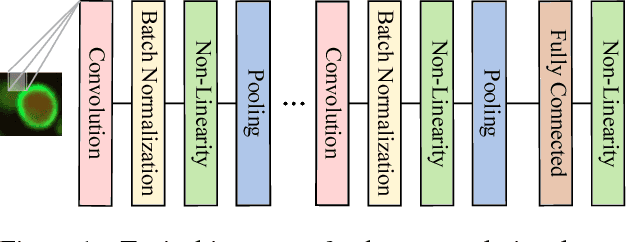
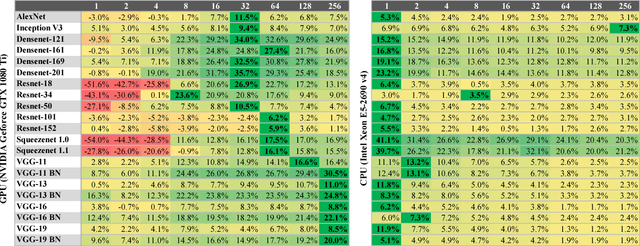
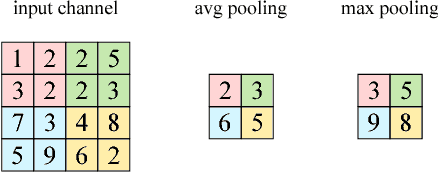
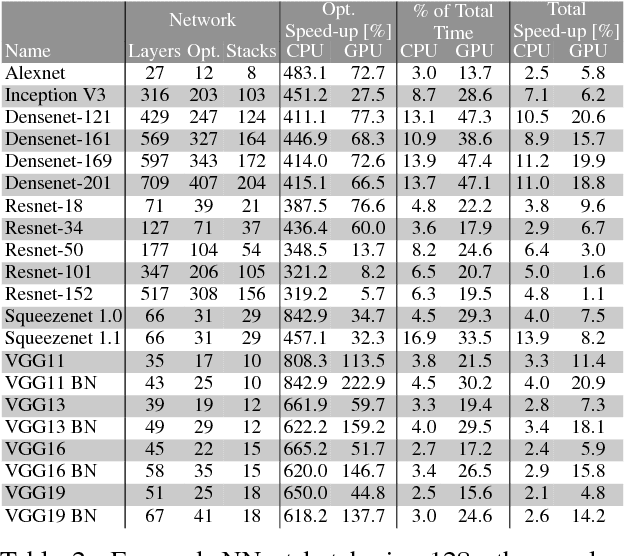
Neural network frameworks such as PyTorch and TensorFlow are the workhorses of numerous machine learning applications ranging from object recognition to machine translation. While these frameworks are versatile and straightforward to use, the training of and inference in deep neural networks is resource (energy, compute, and memory) intensive. In contrast to recent works focusing on algorithmic enhancements, we introduce BrainSlug, a framework that transparently accelerates neural network workloads by changing the default layer-by-layer processing to a depth-first approach, reducing the amount of data required by the computations and thus improving the performance of the available hardware caches. BrainSlug achieves performance improvements of up to 41.1% on CPUs and 35.7% on GPUs. These optimizations come at zero cost to the user as they do not require hardware changes and only need tiny adjustments to the software.