 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech-Based Depressive Mood Detection in the Presence of Multiple Sclerosis: A Cross-Corpus and Cross-Lingual Study
Aug 25, 2025



Depression commonly co-occurs with neurodegenerative disorders like Multiple Sclerosis (MS), yet the potential of speech-based Artificial Intelligence for detecting depression in such contexts remains unexplored. This study examines the transferability of speech-based depression detection methods to people with MS (pwMS) through cross-corpus and cross-lingual analysis using English data from the general population and German data from pwMS. Our approach implements supervised machine learning models using: 1) conventional speech and language features commonly used in the field, 2) emotional dimensions derived from a Speech Emotion Recognition (SER) model, and 3) exploratory speech feature analysis. Despite limited data, our models detect depressive mood in pwMS with moderate generalisability, achieving a 66% Unweighted Average Recall (UAR) on a binary task. Feature selection further improved performance, boosting UAR to 74%. Our findings also highlight the relevant role emotional changes have as an indicator of depressive mood in both the general population and within PwMS. This study provides an initial exploration into generalising speech-based depression detection, even in the presence of co-occurring conditions, such as neurodegenerative diseases.
Using voice analysis as an early indicator of risk for depression in young adults
Nov 18, 2024



Increasingly frequent publications in the literature report voice quality differences between depressed patients and controls. Here, we examine the possibility of using voice analysis as an early warning signal for the development of emotion disturbances in young adults. As part of a major interdisciplinary European research project in four countries (ECoWeB), examining the effects of web-based prevention programs to reduce the risk for depression in young adults, we analyzed a large number of acoustic voice characteristics in vocal reports of emotions experienced by the participants on a specific day. We were able to identify a number of significant differences in acoustic cues, particularly with respect to the energy distribution in the voice spectrum, encouraging further research efforts to develop promising non-obtrusive risk indicators in the normal speaking voice. This is particularly important in the case of young adults who are less likely to exhibit standard risk factors for depression such as negative life experiences.
Wav2Small: Distilling Wav2Vec2 to 72K parameters for Low-Resource Speech emotion recognition
Aug 25, 2024Speech Emotion Recognition (SER) needs high computational resources to overcome the challenge of substantial annotator disagreement. Today SER is shifting towards dimensional annotations of arousal, dominance, and valence (A/D/V). Universal metrics as the L2 distance prove unsuitable for evaluating A/D/V accuracy due to non converging consensus of annotator opinions. However, Concordance Correlation Coefficient (CCC) arose as an alternative metric for A/D/V where a model's output is evaluated to match a whole dataset's CCC rather than L2 distances of individual audios. Recent studies have shown that Wav2Vec2.0 / WavLM architectures outputing a float value for each A/D/V dimension achieve today's State-of-the-art (SOTA) CCC on A/D/V. The Wav2Vec2.0 / WavLM family has high computational footprint, but training tiny models using human annotations has been unsuccessful. In this paper we use a large Transformer SOTA A/D/V model as Teacher/Annotator to train 5 student models: 4 MobileNets and our proposed Wav2Small, using only the Teacher's A/D/V predictions instead of human annotations. We chose MobileNet-V4 / MobileNet-V3 as students, as MobileNet has been designed for fast execution times. We propose Wav2Small an architecture designed for minimal parameter number and RAM consumption. Wav2Small with an .onnx (quantized) of only $60KB$ is a potential solution for A/D/V on hearing aids, having only 72K parameters vs 3.12M parameters for MobileNet-V4-Small. The Teacher model we construct sets a new SOTA on the MSP Podcast Test-1 dataset with valence CCC=0.676.
Are you sure? Analysing Uncertainty Quantification Approaches for Real-world Speech Emotion Recognition
Jul 01, 2024Uncertainty Quantification (UQ) is an important building block for the reliable use of neural networks in real-world scenarios, as it can be a useful tool in identifying faulty predictions. Speech emotion recognition (SER) models can suffer from particularly many sources of uncertainty, such as the ambiguity of emotions, Out-of-Distribution (OOD) data or, in general, poor recording conditions. Reliable UQ methods are thus of particular interest as in many SER applications no prediction is better than a faulty prediction. While the effects of label ambiguity on uncertainty are well documented in the literature, we focus our work on an evaluation of UQ methods for SER under common challenges in real-world application, such as corrupted signals, and the absence of speech. We show that simple UQ methods can already give an indication of the uncertainty of a prediction and that training with additional OOD data can greatly improve the identification of such signals.
Testing Speech Emotion Recognition Machine Learning Models
Dec 11, 2023



Machine learning models for speech emotion recognition (SER) can be trained for different tasks and are usually evaluated on the basis of a few available datasets per task. Tasks could include arousal, valence, dominance, emotional categories, or tone of voice. Those models are mainly evaluated in terms of correlation or recall, and always show some errors in their predictions. The errors manifest themselves in model behaviour, which can be very different along different dimensions even if the same recall or correlation is achieved by the model. This paper investigates behavior of speech emotion recognition models with a testing framework which requires models to fulfill conditions in terms of correctness, fairness, and robustness.
Going Retro: Astonishingly Simple Yet Effective Rule-based Prosody Modelling for Speech Synthesis Simulating Emotion Dimensions
Jul 05, 2023We introduce two rule-based models to modify the prosody of speech synthesis in order to modulate the emotion to be expressed. The prosody modulation is based on speech synthesis markup language (SSML) and can be used with any commercial speech synthesizer. The models as well as the optimization result are evaluated against human emotion annotations. Results indicate that with a very simple method both dimensions arousal (.76 UAR) and valence (.43 UAR) can be simulated.
Speech-based Age and Gender Prediction with Transformers
Jun 29, 2023



We report on the curation of several publicly available datasets for age and gender prediction. Furthermore, we present experiments to predict age and gender with models based on a pre-trained wav2vec 2.0. Depending on the dataset, we achieve an MAE between 7.1 years and 10.8 years for age, and at least 91.1% ACC for gender (female, male, child). Compared to a modelling approach built on handcrafted features, our proposed system shows an improvement of 9% UAR for age and 4% UAR for gender. To make our findings reproducible, we release the best performing model to the community as well as the sample lists of the data splits.
audb -- Sharing and Versioning of Audio and Annotation Data in Python
Mar 04, 2023


Driven by the need for larger and more diverse datasets to pre-train and fine-tune increasingly complex machine learning models, the number of datasets is rapidly growing. audb is an open-source Python library that supports versioning and documentation of audio datasets. It aims to provide a standardized and simple user-interface to publish, maintain, and access the annotations and audio files of a dataset. To efficiently store the data on a server, audb automatically resolves dependencies between versions of a dataset and only uploads newly added or altered files when a new version is published. The library supports partial loading of a dataset and local caching for fast access. audb is a lightweight library and can be interfaced from any machine learning library. It supports the management of datasets on a single PC, within a university or company, or within a whole research community. audb is available at https://github.com/audeering/audb.
Probing Speech Emotion Recognition Transformers for Linguistic Knowledge
Apr 01, 2022
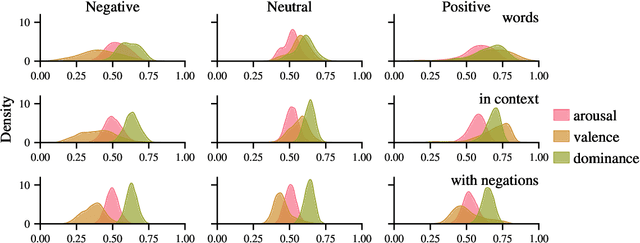
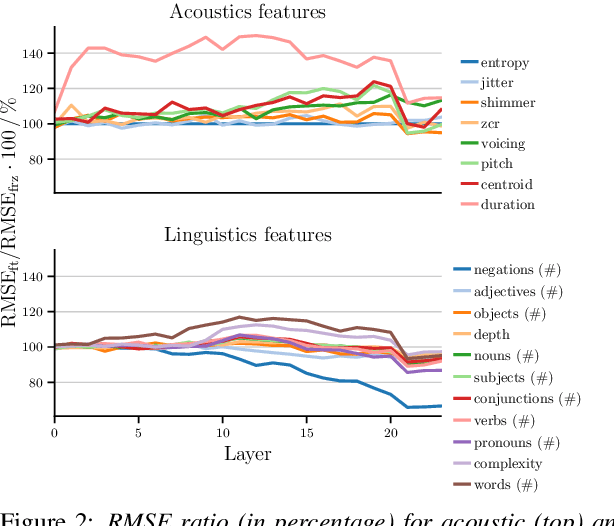
Large, pre-trained neural networks consisting of self-attention layers (transformers) have recently achieved state-of-the-art results on several speech emotion recognition (SER) datasets. These models are typically pre-trained in self-supervised manner with the goal to improve automatic speech recognition performance -- and thus, to understand linguistic information. In this work, we investigate the extent in which this information is exploited during SER fine-tuning. Using a reproducible methodology based on open-source tools, we synthesise prosodically neutral speech utterances while varying the sentiment of the text. Valence predictions of the transformer model are very reactive to positive and negative sentiment content, as well as negations, but not to intensifiers or reducers, while none of those linguistic features impact arousal or dominance. These findings show that transformers can successfully leverage linguistic information to improve their valence predictions, and that linguistic analysis should be included in their testing.
Dawn of the transformer era in speech emotion recognition: closing the valence gap
Mar 16, 2022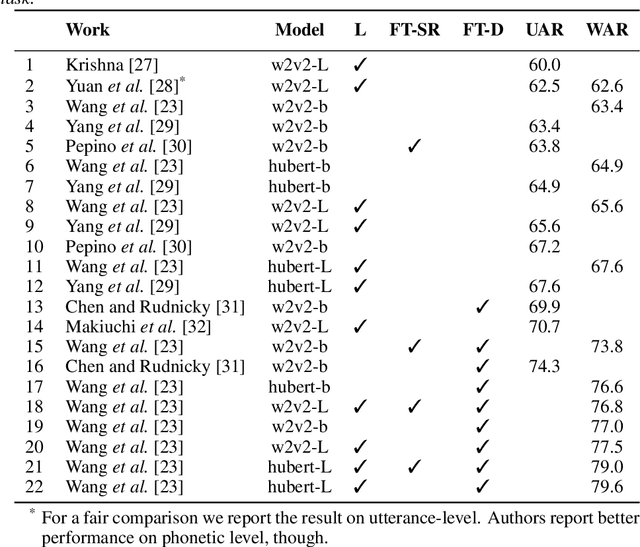
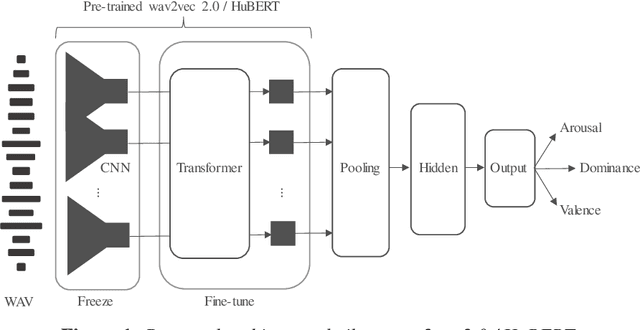
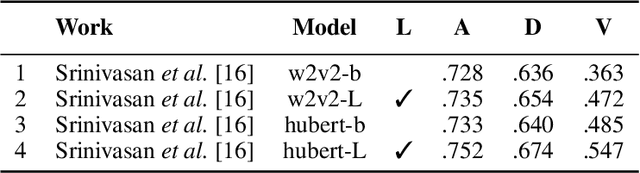
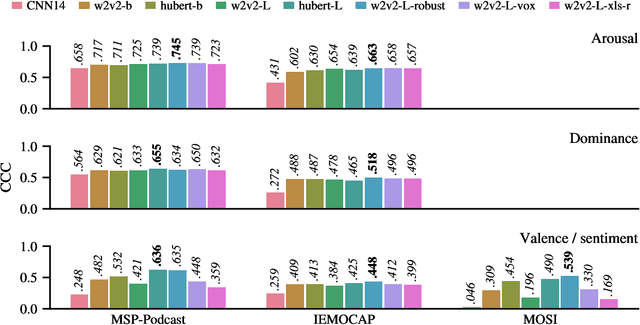
Recent advances in transformer-based architectures which are pre-trained in self-supervised manner have shown great promise in several machine learning tasks. In the audio domain, such architectures have also been successfully utilised in the field of speech emotion recognition (SER). However, existing works have not evaluated the influence of model size and pre-training data on downstream performance, and have shown limited attention to generalisation, robustness, fairness, and efficiency. The present contribution conducts a thorough analysis of these aspects on several pre-trained variants of wav2vec 2.0 and HuBERT that we fine-tuned on the dimensions arousal, dominance, and valence of MSP-Podcast, while additionally using IEMOCAP and MOSI to test cross-corpus generalisation. To the best of our knowledge, we obtain the top performance for valence prediction without use of explicit linguistic information, with a concordance correlation coefficient (CCC) of .638 on MSP-Podcast. Furthermore, our investigations reveal that transformer-based architectures are more robust to small perturbations compared to a CNN-based baseline and fair with respect to biological sex groups, but not towards individual speakers. Finally, we are the first to show that their extraordinary success on valence is based on implicit linguistic information learnt during fine-tuning of the transformer layers, which explains why they perform on-par with recent multimodal approaches that explicitly utilise textual information. Our findings collectively paint the following picture: transformer-based architectures constitute the new state-of-the-art in SER, but further advances are needed to mitigate remaining robustness and individual speaker issues. To make our findings reproducible, we release the best performing model to the community.