 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech-based Age and Gender Prediction with Transformers
Jun 29, 2023



We report on the curation of several publicly available datasets for age and gender prediction. Furthermore, we present experiments to predict age and gender with models based on a pre-trained wav2vec 2.0. Depending on the dataset, we achieve an MAE between 7.1 years and 10.8 years for age, and at least 91.1% ACC for gender (female, male, child). Compared to a modelling approach built on handcrafted features, our proposed system shows an improvement of 9% UAR for age and 4% UAR for gender. To make our findings reproducible, we release the best performing model to the community as well as the sample lists of the data splits.
audb -- Sharing and Versioning of Audio and Annotation Data in Python
Mar 04, 2023


Driven by the need for larger and more diverse datasets to pre-train and fine-tune increasingly complex machine learning models, the number of datasets is rapidly growing. audb is an open-source Python library that supports versioning and documentation of audio datasets. It aims to provide a standardized and simple user-interface to publish, maintain, and access the annotations and audio files of a dataset. To efficiently store the data on a server, audb automatically resolves dependencies between versions of a dataset and only uploads newly added or altered files when a new version is published. The library supports partial loading of a dataset and local caching for fast access. audb is a lightweight library and can be interfaced from any machine learning library. It supports the management of datasets on a single PC, within a university or company, or within a whole research community. audb is available at https://github.com/audeering/audb.
Probing Speech Emotion Recognition Transformers for Linguistic Knowledge
Apr 01, 2022
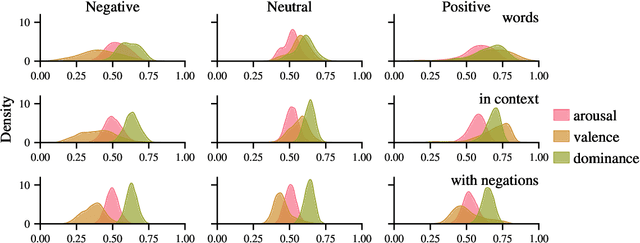
Large, pre-trained neural networks consisting of self-attention layers (transformers) have recently achieved state-of-the-art results on several speech emotion recognition (SER) datasets. These models are typically pre-trained in self-supervised manner with the goal to improve automatic speech recognition performance -- and thus, to understand linguistic information. In this work, we investigate the extent in which this information is exploited during SER fine-tuning. Using a reproducible methodology based on open-source tools, we synthesise prosodically neutral speech utterances while varying the sentiment of the text. Valence predictions of the transformer model are very reactive to positive and negative sentiment content, as well as negations, but not to intensifiers or reducers, while none of those linguistic features impact arousal or dominance. These findings show that transformers can successfully leverage linguistic information to improve their valence predictions, and that linguistic analysis should be included in their testing.
Dawn of the transformer era in speech emotion recognition: closing the valence gap
Mar 16, 2022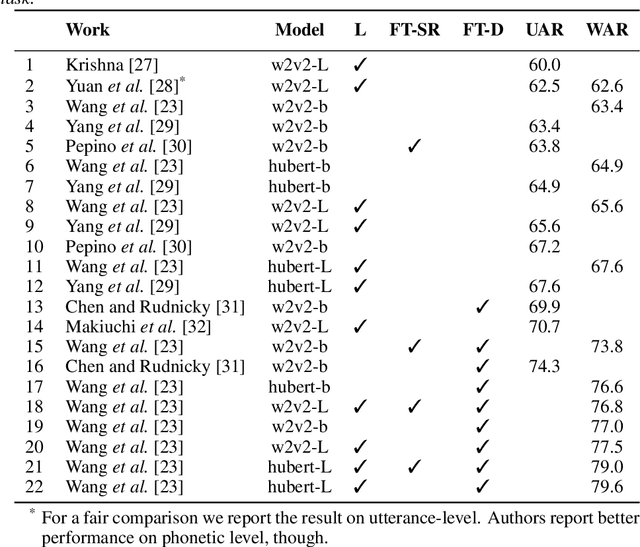
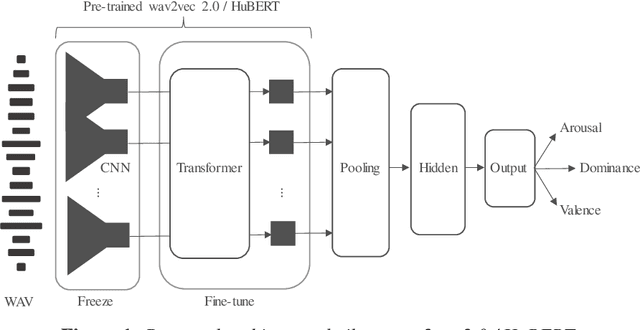
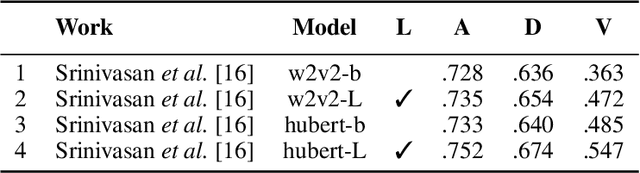
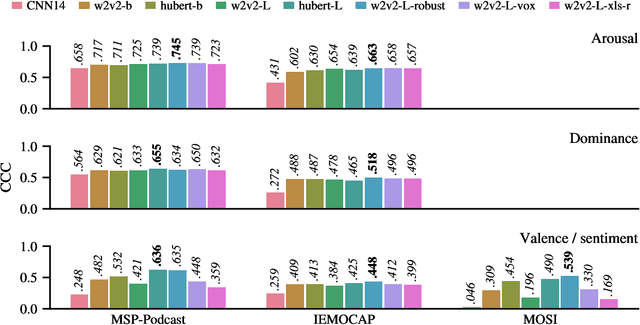
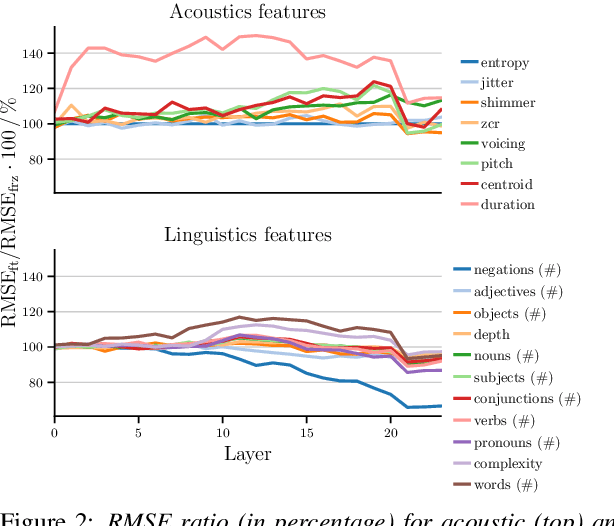
Recent advances in transformer-based architectures which are pre-trained in self-supervised manner have shown great promise in several machine learning tasks. In the audio domain, such architectures have also been successfully utilised in the field of speech emotion recognition (SER). However, existing works have not evaluated the influence of model size and pre-training data on downstream performance, and have shown limited attention to generalisation, robustness, fairness, and efficiency. The present contribution conducts a thorough analysis of these aspects on several pre-trained variants of wav2vec 2.0 and HuBERT that we fine-tuned on the dimensions arousal, dominance, and valence of MSP-Podcast, while additionally using IEMOCAP and MOSI to test cross-corpus generalisation. To the best of our knowledge, we obtain the top performance for valence prediction without use of explicit linguistic information, with a concordance correlation coefficient (CCC) of .638 on MSP-Podcast. Furthermore, our investigations reveal that transformer-based architectures are more robust to small perturbations compared to a CNN-based baseline and fair with respect to biological sex groups, but not towards individual speakers. Finally, we are the first to show that their extraordinary success on valence is based on implicit linguistic information learnt during fine-tuning of the transformer layers, which explains why they perform on-par with recent multimodal approaches that explicitly utilise textual information. Our findings collectively paint the following picture: transformer-based architectures constitute the new state-of-the-art in SER, but further advances are needed to mitigate remaining robustness and individual speaker issues. To make our findings reproducible, we release the best performing model to the community.
Applying Cooperative Machine Learning to Speed Up the Annotation of Social Signals in Large Multi-modal Corpora
Feb 07, 2018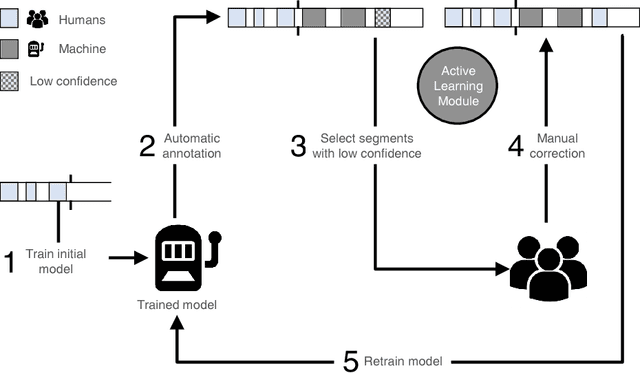

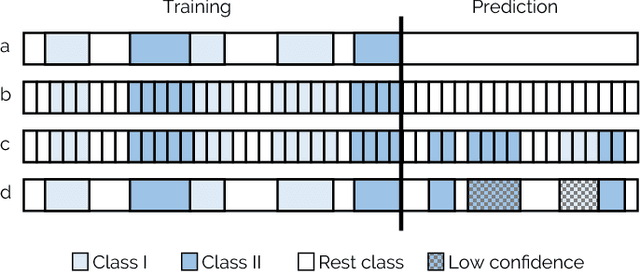
Scientific disciplines, such as Behavioural Psychology, Anthropology and recently Social Signal Processing are concerned with the systematic exploration of human behaviour. A typical work-flow includes the manual annotation (also called coding) of social signals in multi-modal corpora of considerable size. For the involved annotators this defines an exhausting and time-consuming task. In the article at hand we present a novel method and also provide the tools to speed up the coding procedure. To this end, we suggest and evaluate the use of Cooperative Machine Learning (CML) techniques to reduce manual labelling efforts by combining the power of computational capabilities and human intelligence. The proposed CML strategy starts with a small number of labelled instances and concentrates on predicting local parts first. Afterwards, a session-independent classification model is created to finish the remaining parts of the database. Confidence values are computed to guide the manual inspection and correction of the predictions. To bring the proposed approach into application we introduce NOVA - an open-source tool for collaborative and machine-aided annotations. In particular, it gives labellers immediate access to CML strategies and directly provides visual feedback on the results. Our experiments show that the proposed method has the potential to significantly reduce human labelling efforts.