 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssistive Robots and Reasonable Work Assignment Reduce Perceived Stigma toward Persons with Disabilities
Jan 30, 2026Robots are becoming more prominent in assisting persons with disabilities (PwD). Whilst there is broad consensus that robots can assist in mitigating physical impairments, the extent to which they can facilitate social inclusion remains equivocal. In fact, the exposed status of assisted workers could likewise lead to reduced or increased perceived stigma by other workers. We present a vignette study on the perceived cognitive and behavioral stigma toward PwD in the workplace. We designed four experimental conditions depicting a coworker with an impairment in work scenarios: overburdened work, suitable work, and robot-assisted work only for the coworker, and an offer of robot-assisted work for everyone. Our results show that cognitive stigma is significantly reduced when the work task is adapted to the person's abilities or augmented by an assistive robot. In addition, offering robot-assisted work for everyone, in the sense of universal design, further reduces perceived cognitive stigma. Thus, we conclude that assistive robots reduce perceived cognitive stigma, thereby supporting the use of collaborative robots in work scenarios involving PwDs.
CAR-bench: Evaluating the Consistency and Limit-Awareness of LLM Agents under Real-World Uncertainty
Jan 29, 2026Existing benchmarks for Large Language Model (LLM) agents focus on task completion under idealistic settings but overlook reliability in real-world, user-facing applications. In domains, such as in-car voice assistants, users often issue incomplete or ambiguous requests, creating intrinsic uncertainty that agents must manage through dialogue, tool use, and policy adherence. We introduce CAR-bench, a benchmark for evaluating consistency, uncertainty handling, and capability awareness in multi-turn, tool-using LLM agents in an in-car assistant domain. The environment features an LLM-simulated user, domain policies, and 58 interconnected tools spanning navigation, productivity, charging, and vehicle control. Beyond standard task completion, CAR-bench introduces Hallucination tasks that test agents' limit-awareness under missing tools or information, and Disambiguation tasks that require resolving uncertainty through clarification or internal information gathering. Baseline results reveal large gaps between occasional and consistent success on all task types. Even frontier reasoning LLMs achieve less than 50% consistent pass rate on Disambiguation tasks due to premature actions, and frequently violate policies or fabricate information to satisfy user requests in Hallucination tasks, underscoring the need for more reliable and self-aware LLM agents in real-world settings.
Video Joint-Embedding Predictive Architectures for Facial Expression Recognition
Jan 14, 2026This paper introduces a novel application of Video Joint-Embedding Predictive Architectures (V-JEPAs) for Facial Expression Recognition (FER). Departing from conventional pre-training methods for video understanding that rely on pixel-level reconstructions, V-JEPAs learn by predicting embeddings of masked regions from the embeddings of unmasked regions. This enables the trained encoder to not capture irrelevant information about a given video like the color of a region of pixels in the background. Using a pre-trained V-JEPA video encoder, we train shallow classifiers using the RAVDESS and CREMA-D datasets, achieving state-of-the-art performance on RAVDESS and outperforming all other vision-based methods on CREMA-D (+1.48 WAR). Furthermore, cross-dataset evaluations reveal strong generalization capabilities, demonstrating the potential of purely embedding-based pre-training approaches to advance FER. We release our code at https://github.com/lennarteingunia/vjepa-for-fer.
Communicating Through Avatars in Industry 5.0: A Focus Group Study on Human-Robot Collaboration
Jun 10, 2025The integration of collaborative robots (cobots) in industrial settings raises concerns about worker well-being, particularly due to reduced social interactions. Avatars - designed to facilitate worker interactions and engagement - are promising solutions to enhance the human-robot collaboration (HRC) experience. However, real-world perspectives on avatar-supported HRC remain unexplored. To address this gap, we conducted a focus group study with employees from a German manufacturing company that uses cobots. Before the discussion, participants engaged with a scripted, industry-like HRC demo in a lab setting. This qualitative approach provided valuable insights into the avatar's potential roles, improvements to its behavior, and practical considerations for deploying them in industrial workcells. Our findings also emphasize the importance of personalized communication and task assistance. Although our study's limitations restrict its generalizability, it serves as an initial step in recognizing the potential of adaptive, context-aware avatar interactions in real-world industrial environments.
CarMem: Enhancing Long-Term Memory in LLM Voice Assistants through Category-Bounding
Jan 16, 2025



In today's assistant landscape, personalisation enhances interactions, fosters long-term relationships, and deepens engagement. However, many systems struggle with retaining user preferences, leading to repetitive user requests and disengagement. Furthermore, the unregulated and opaque extraction of user preferences in industry applications raises significant concerns about privacy and trust, especially in regions with stringent regulations like Europe. In response to these challenges, we propose a long-term memory system for voice assistants, structured around predefined categories. This approach leverages Large Language Models to efficiently extract, store, and retrieve preferences within these categories, ensuring both personalisation and transparency. We also introduce a synthetic multi-turn, multi-session conversation dataset (CarMem), grounded in real industry data, tailored to an in-car voice assistant setting. Benchmarked on the dataset, our system achieves an F1-score of .78 to .95 in preference extraction, depending on category granularity. Our maintenance strategy reduces redundant preferences by 95% and contradictory ones by 92%, while the accuracy of optimal retrieval is at .87. Collectively, the results demonstrate the system's suitability for industrial applications.
A Pre-Trained Graph-Based Model for Adaptive Sequencing of Educational Documents
Nov 18, 2024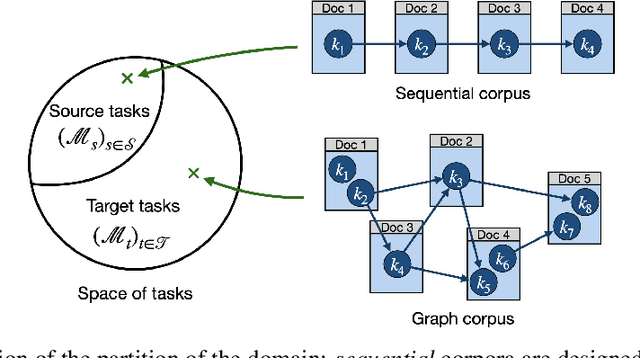

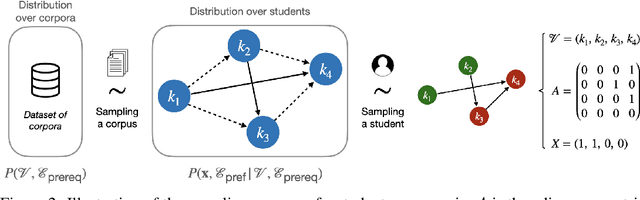

Massive Open Online Courses (MOOCs) have greatly contributed to making education more accessible. However, many MOOCs maintain a rigid, one-size-fits-all structure that fails to address the diverse needs and backgrounds of individual learners. Learning path personalization aims to address this limitation, by tailoring sequences of educational content to optimize individual student learning outcomes. Existing approaches, however, often require either massive student interaction data or extensive expert annotation, limiting their broad application. In this study, we introduce a novel data-efficient framework for learning path personalization that operates without expert annotation. Our method employs a flexible recommender system pre-trained with reinforcement learning on a dataset of raw course materials. Through experiments on semi-synthetic data, we show that this pre-training stage substantially improves data-efficiency in a range of adaptive learning scenarios featuring new educational materials. This opens up new perspectives for the design of foundation models for adaptive learning.
VoiceX: A Text-To-Speech Framework for Custom Voices
Aug 22, 2024Modern TTS systems are capable of creating highly realistic and natural-sounding speech. Despite these developments, the process of customizing TTS voices remains a complex task, mostly requiring the expertise of specialists within the field. One reason for this is the utilization of deep learning models, which are characterized by their expansive, non-interpretable parameter spaces, restricting the feasibility of manual customization. In this paper, we present a novel human-in-the-loop paradigm based on an evolutionary algorithm for directly interacting with the parameter space of a neural TTS model. We integrated our approach into a user-friendly graphical user interface that allows users to efficiently create original voices. Those voices can then be used with the backbone TTS model, for which we provide a Python API. Further, we present the results of a user study exploring the capabilities of VoiceX. We show that VoiceX is an appropriate tool for creating individual, custom voices.
Recognizing Emotion Regulation Strategies from Human Behavior with Large Language Models
Aug 08, 2024



Human emotions are often not expressed directly, but regulated according to internal processes and social display rules. For affective computing systems, an understanding of how users regulate their emotions can be highly useful, for example to provide feedback in job interview training, or in psychotherapeutic scenarios. However, at present no method to automatically classify different emotion regulation strategies in a cross-user scenario exists. At the same time, recent studies showed that instruction-tuned Large Language Models (LLMs) can reach impressive performance across a variety of affect recognition tasks such as categorical emotion recognition or sentiment analysis. While these results are promising, it remains unclear to what extent the representational power of LLMs can be utilized in the more subtle task of classifying users' internal emotion regulation strategy. To close this gap, we make use of the recently introduced \textsc{Deep} corpus for modeling the social display of the emotion shame, where each point in time is annotated with one of seven different emotion regulation classes. We fine-tune Llama2-7B as well as the recently introduced Gemma model using Low-rank Optimization on prompts generated from different sources of information on the \textsc{Deep} corpus. These include verbal and nonverbal behavior, person factors, as well as the results of an in-depth interview after the interaction. Our results show, that a fine-tuned Llama2-7B LLM is able to classify the utilized emotion regulation strategy with high accuracy (0.84) without needing access to data from post-interaction interviews. This represents a significant improvement over previous approaches based on Bayesian Networks and highlights the importance of modeling verbal behavior in emotion regulation.
DISCOVER: A Data-driven Interactive System for Comprehensive Observation, Visualization, and ExploRation of Human Behaviour
Jul 18, 2024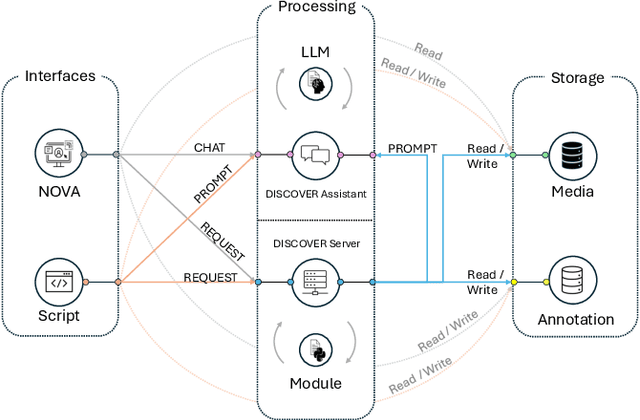
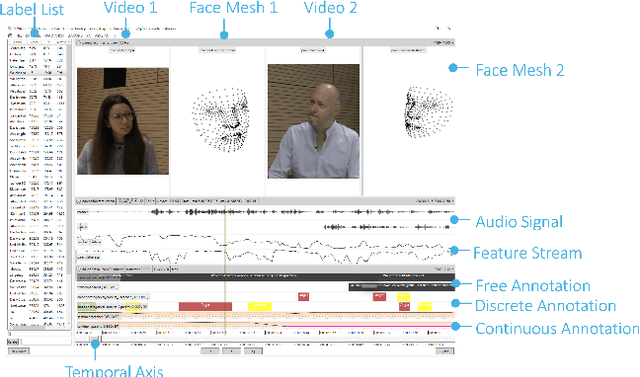
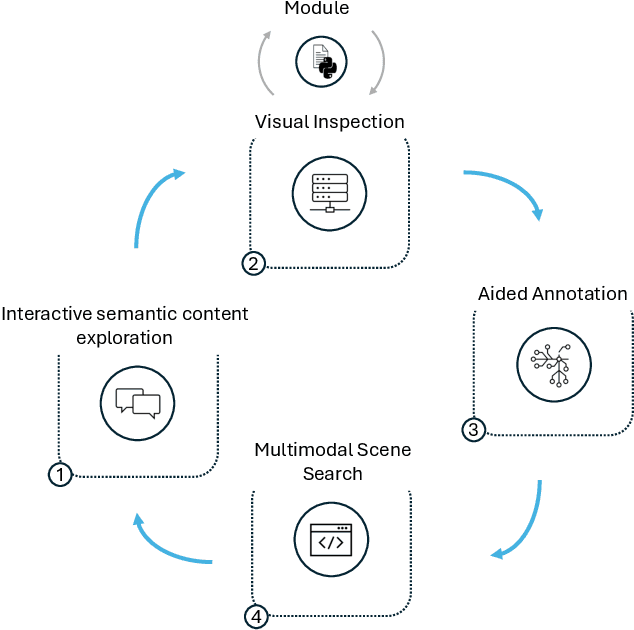
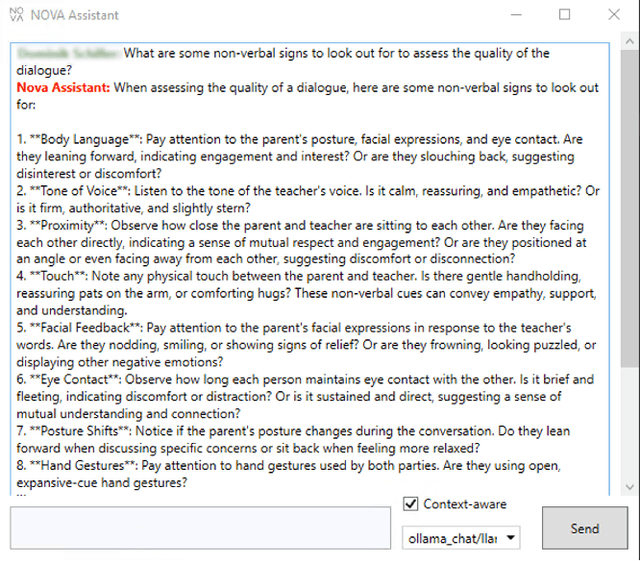
Understanding human behavior is a fundamental goal of social sciences, yet its analysis presents significant challenges. Conventional methodologies employed for the study of behavior, characterized by labor-intensive data collection processes and intricate analyses, frequently hinder comprehensive exploration due to their time and resource demands. In response to these challenges, computational models have proven to be promising tools that help researchers analyze large amounts of data by automatically identifying important behavioral indicators, such as social signals. However, the widespread adoption of such state-of-the-art computational models is impeded by their inherent complexity and the substantial computational resources necessary to run them, thereby constraining accessibility for researchers without technical expertise and adequate equipment. To address these barriers, we introduce DISCOVER -- a modular and flexible, yet user-friendly software framework specifically developed to streamline computational-driven data exploration for human behavior analysis. Our primary objective is to democratize access to advanced computational methodologies, thereby enabling researchers across disciplines to engage in detailed behavioral analysis without the need for extensive technical proficiency. In this paper, we demonstrate the capabilities of DISCOVER using four exemplary data exploration workflows that build on each other: Interactive Semantic Content Exploration, Visual Inspection, Aided Annotation, and Multimodal Scene Search. By illustrating these workflows, we aim to emphasize the versatility and accessibility of DISCOVER as a comprehensive framework and propose a set of blueprints that can serve as a general starting point for exploratory data analysis.
Faces of Experimental Pain: Transferability of Deep Learned Heat Pain Features to Electrical Pain
Jun 17, 2024



The limited size of pain datasets are a challenge in developing robust deep learning models for pain recognition. Transfer learning approaches are often employed in these scenarios. In this study, we investigate whether deep learned feature representation for one type of experimentally induced pain can be transferred to another. Participating in the AI4Pain challenge, our goal is to classify three levels of pain (No-Pain, Low-Pain, High-Pain). The challenge dataset contains data collected from 65 participants undergoing varying intensities of electrical pain. We utilize the video recording from the dataset to investigate the transferability of deep learned heat pain model to electrical pain. In our proposed approach, we leverage an existing heat pain convolutional neural network (CNN) - trained on BioVid dataset - as a feature extractor. The images from the challenge dataset are inputted to the pre-trained heat pain CNN to obtain feature vectors. These feature vectors are used to train two machine learning models: a simple feed-forward neural network and a long short-term memory (LSTM) network. Our approach was tested using the dataset's predefined training, validation, and testing splits. Our models outperformed the baseline of the challenge on both the validation and tests sets, highlighting the potential of models trained on other pain datasets for reliable feature extraction.