 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISCOVER: A Data-driven Interactive System for Comprehensive Observation, Visualization, and ExploRation of Human Behaviour
Jul 18, 2024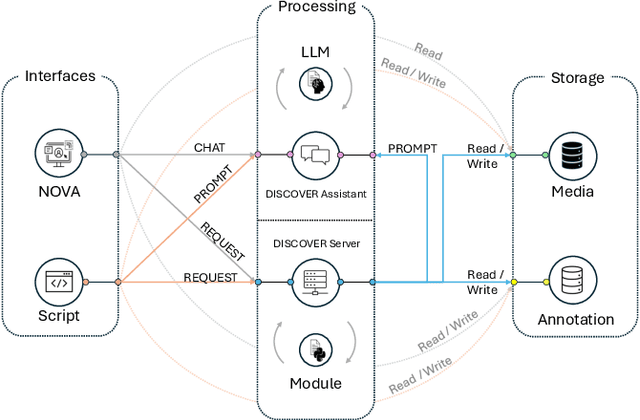
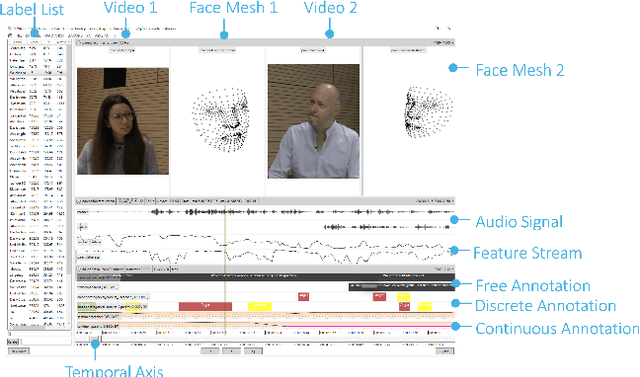
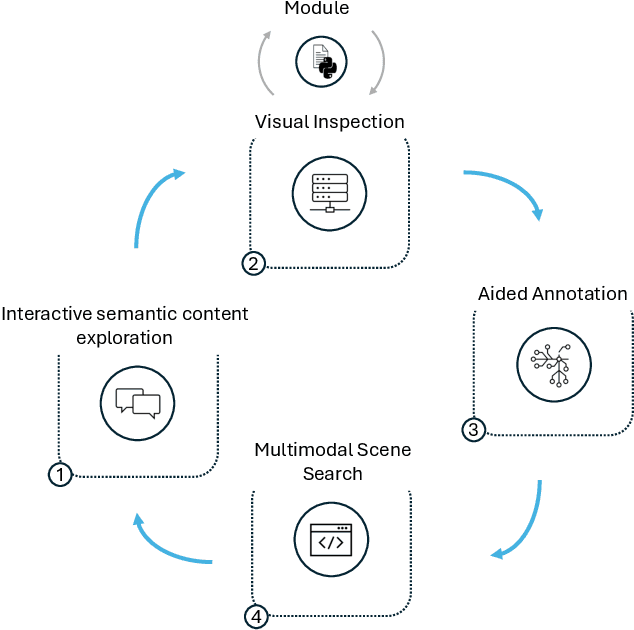
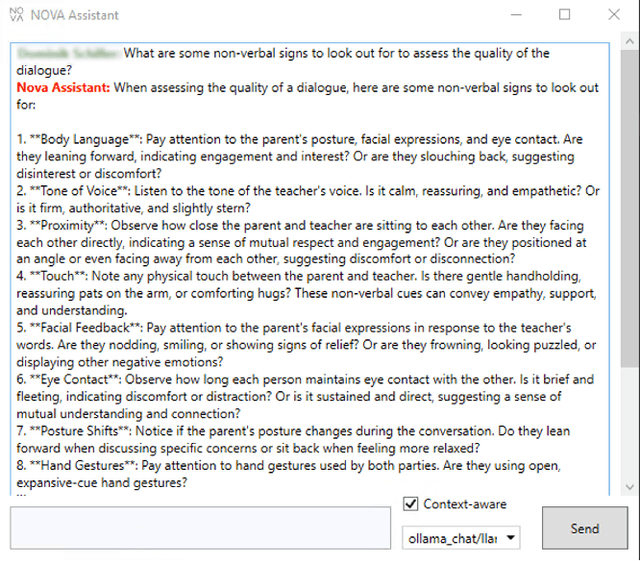
Understanding human behavior is a fundamental goal of social sciences, yet its analysis presents significant challenges. Conventional methodologies employed for the study of behavior, characterized by labor-intensive data collection processes and intricate analyses, frequently hinder comprehensive exploration due to their time and resource demands. In response to these challenges, computational models have proven to be promising tools that help researchers analyze large amounts of data by automatically identifying important behavioral indicators, such as social signals. However, the widespread adoption of such state-of-the-art computational models is impeded by their inherent complexity and the substantial computational resources necessary to run them, thereby constraining accessibility for researchers without technical expertise and adequate equipment. To address these barriers, we introduce DISCOVER -- a modular and flexible, yet user-friendly software framework specifically developed to streamline computational-driven data exploration for human behavior analysis. Our primary objective is to democratize access to advanced computational methodologies, thereby enabling researchers across disciplines to engage in detailed behavioral analysis without the need for extensive technical proficiency. In this paper, we demonstrate the capabilities of DISCOVER using four exemplary data exploration workflows that build on each other: Interactive Semantic Content Exploration, Visual Inspection, Aided Annotation, and Multimodal Scene Search. By illustrating these workflows, we aim to emphasize the versatility and accessibility of DISCOVER as a comprehensive framework and propose a set of blueprints that can serve as a general starting point for exploratory data analysis.
Unimodal Multi-Task Fusion for Emotional Mimicry Prediction
Mar 22, 2024



In this study, we propose a methodology for the Emotional Mimicry Intensity (EMI) Estimation task within the context of the 6th Workshop and Competition on Affective Behavior Analysis in-the-wild. Our approach leverages the Wav2Vec 2.0 framework, pre-trained on a comprehensive podcast dataset, to extract a broad range of audio features encompassing both linguistic and paralinguistic elements. We enhance feature representation through a fusion technique that integrates individual features with a global mean vector, introducing global contextual insights into our analysis. Additionally, we incorporate a pre-trained valence-arousal-dominance (VAD) module from the Wav2Vec 2.0 model. Our fusion employs a Long Short-Term Memory (LSTM) architecture for efficient temporal analysis of audio data. Utilizing only the provided audio data, our approach demonstrates significant improvements over the established baseline.
An Efficient Multitask Learning Architecture for Affective Vocal Burst Analysis
Sep 28, 2022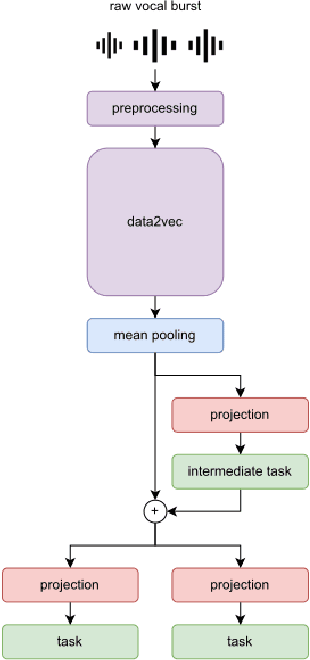
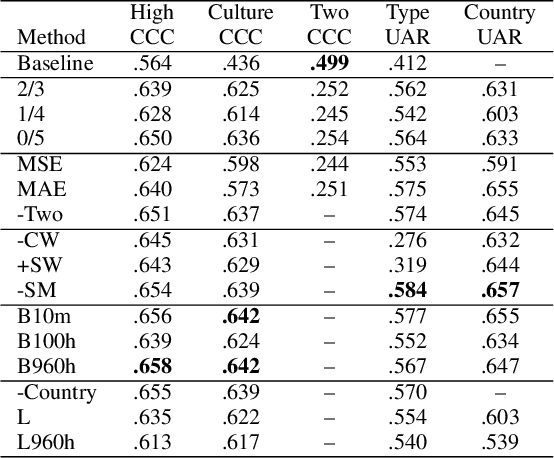
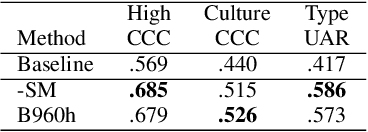
Affective speech analysis is an ongoing topic of research. A relatively new problem in this field is the analysis of vocal bursts, which are nonverbal vocalisations such as laughs or sighs. Current state-of-the-art approaches to address affective vocal burst analysis are mostly based on wav2vec2 or HuBERT features. In this paper, we investigate the use of the wav2vec successor data2vec in combination with a multitask learning pipeline to tackle different analysis problems at once. To assess the performance of our efficient multitask learning architecture, we participate in the 2022 ACII Affective Vocal Burst Challenge, showing that our approach substantially outperforms the baseline established there in three different subtasks.