 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Joint-Embedding Predictive Architectures for Facial Expression Recognition
Jan 14, 2026This paper introduces a novel application of Video Joint-Embedding Predictive Architectures (V-JEPAs) for Facial Expression Recognition (FER). Departing from conventional pre-training methods for video understanding that rely on pixel-level reconstructions, V-JEPAs learn by predicting embeddings of masked regions from the embeddings of unmasked regions. This enables the trained encoder to not capture irrelevant information about a given video like the color of a region of pixels in the background. Using a pre-trained V-JEPA video encoder, we train shallow classifiers using the RAVDESS and CREMA-D datasets, achieving state-of-the-art performance on RAVDESS and outperforming all other vision-based methods on CREMA-D (+1.48 WAR). Furthermore, cross-dataset evaluations reveal strong generalization capabilities, demonstrating the potential of purely embedding-based pre-training approaches to advance FER. We release our code at https://github.com/lennarteingunia/vjepa-for-fer.
VoiceX: A Text-To-Speech Framework for Custom Voices
Aug 22, 2024Modern TTS systems are capable of creating highly realistic and natural-sounding speech. Despite these developments, the process of customizing TTS voices remains a complex task, mostly requiring the expertise of specialists within the field. One reason for this is the utilization of deep learning models, which are characterized by their expansive, non-interpretable parameter spaces, restricting the feasibility of manual customization. In this paper, we present a novel human-in-the-loop paradigm based on an evolutionary algorithm for directly interacting with the parameter space of a neural TTS model. We integrated our approach into a user-friendly graphical user interface that allows users to efficiently create original voices. Those voices can then be used with the backbone TTS model, for which we provide a Python API. Further, we present the results of a user study exploring the capabilities of VoiceX. We show that VoiceX is an appropriate tool for creating individual, custom voices.
Relevant Irrelevance: Generating Alterfactual Explanations for Image Classifiers
May 08, 2024

In this paper, we demonstrate the feasibility of alterfactual explanations for black box image classifiers. Traditional explanation mechanisms from the field of Counterfactual Thinking are a widely-used paradigm for Explainable Artificial Intelligence (XAI), as they follow a natural way of reasoning that humans are familiar with. However, most common approaches from this field are based on communicating information about features or characteristics that are especially important for an AI's decision. However, to fully understand a decision, not only knowledge about relevant features is needed, but the awareness of irrelevant information also highly contributes to the creation of a user's mental model of an AI system. To this end, a novel approach for explaining AI systems called alterfactual explanations was recently proposed on a conceptual level. It is based on showing an alternative reality where irrelevant features of an AI's input are altered. By doing so, the user directly sees which input data characteristics can change arbitrarily without influencing the AI's decision. In this paper, we show for the first time that it is possible to apply this idea to black box models based on neural networks. To this end, we present a GAN-based approach to generate these alterfactual explanations for binary image classifiers. Further, we present a user study that gives interesting insights on how alterfactual explanations can complement counterfactual explanations.
The AffectToolbox: Affect Analysis for Everyone
Feb 23, 2024



In the field of affective computing, where research continually advances at a rapid pace, the demand for user-friendly tools has become increasingly apparent. In this paper, we present the AffectToolbox, a novel software system that aims to support researchers in developing affect-sensitive studies and prototypes. The proposed system addresses the challenges posed by existing frameworks, which often require profound programming knowledge and cater primarily to power-users or skilled developers. Aiming to facilitate ease of use, the AffectToolbox requires no programming knowledge and offers its functionality to reliably analyze the affective state of users through an accessible graphical user interface. The architecture encompasses a variety of models for emotion recognition on multiple affective channels and modalities, as well as an elaborate fusion system to merge multi-modal assessments into a unified result. The entire system is open-sourced and will be publicly available to ensure easy integration into more complex applications through a well-structured, Python-based code base - therefore marking a substantial contribution toward advancing affective computing research and fostering a more collaborative and inclusive environment within this interdisciplinary field.
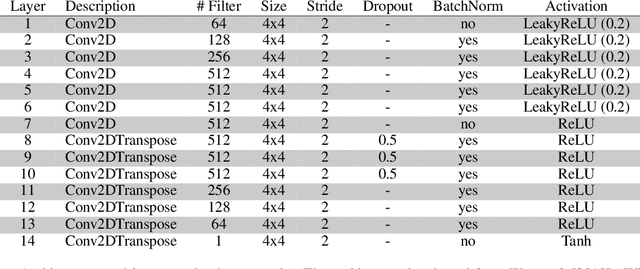
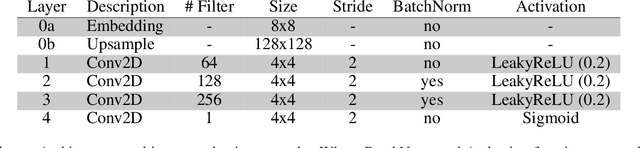
Giving Robots a Voice: Human-in-the-Loop Voice Creation and open-ended Labeling
Feb 07, 2024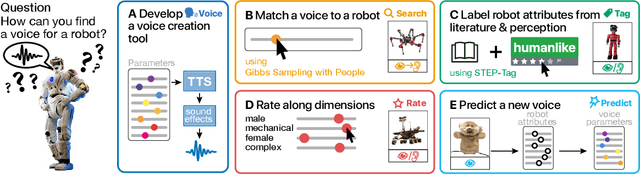
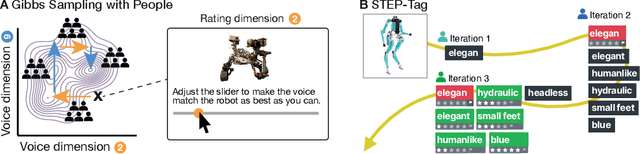
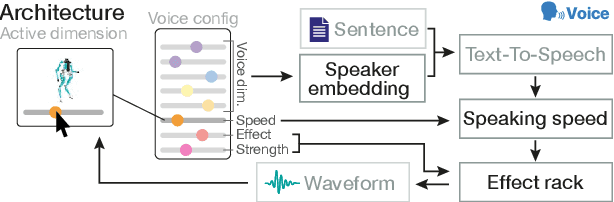
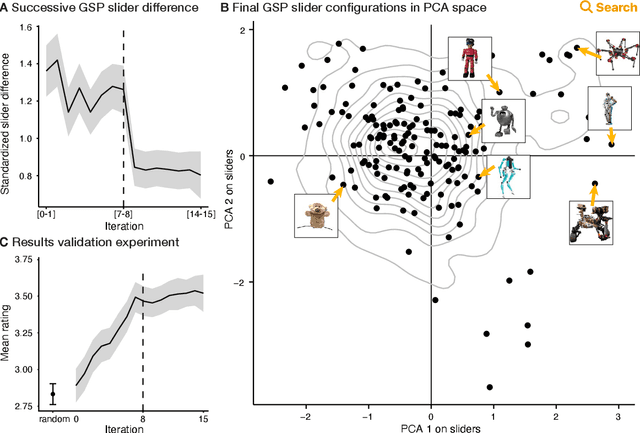
Speech is a natural interface for humans to interact with robots. Yet, aligning a robot's voice to its appearance is challenging due to the rich vocabulary of both modalities. Previous research has explored a few labels to describe robots and tested them on a limited number of robots and existing voices. Here, we develop a robot-voice creation tool followed by large-scale behavioral human experiments (N=2,505). First, participants collectively tune robotic voices to match 175 robot images using an adaptive human-in-the-loop pipeline. Then, participants describe their impression of the robot or their matched voice using another human-in-the-loop paradigm for open-ended labeling. The elicited taxonomy is then used to rate robot attributes and to predict the best voice for an unseen robot. We offer a web interface to aid engineers in customizing robot voices, demonstrating the synergy between cognitive science and machine learning for engineering tools.
The STOIC2021 COVID-19 AI challenge: applying reusable training methodologies to private data
Jun 25, 2023Challenges drive the state-of-the-art of automated medical image analysis. The quantity of public training data that they provide can limit the performance of their solutions. Public access to the training methodology for these solutions remains absent. This study implements the Type Three (T3) challenge format, which allows for training solutions on private data and guarantees reusable training methodologies. With T3, challenge organizers train a codebase provided by the participants on sequestered training data. T3 was implemented in the STOIC2021 challenge, with the goal of predicting from a computed tomography (CT) scan whether subjects had a severe COVID-19 infection, defined as intubation or death within one month. STOIC2021 consisted of a Qualification phase, where participants developed challenge solutions using 2000 publicly available CT scans, and a Final phase, where participants submitted their training methodologies with which solutions were trained on CT scans of 9724 subjects. The organizers successfully trained six of the eight Final phase submissions. The submitted codebases for training and running inference were released publicly. The winning solution obtained an area under the receiver operating characteristic curve for discerning between severe and non-severe COVID-19 of 0.815. The Final phase solutions of all finalists improved upon their Qualification phase solutions.HSUXJM-TNZF9CHSUXJM-TNZF9C
Towards Automated COVID-19 Presence and Severity Classification
May 15, 2023COVID-19 presence classification and severity prediction via (3D) thorax computed tomography scans have become important tasks in recent times. Especially for capacity planning of intensive care units, predicting the future severity of a COVID-19 patient is crucial. The presented approach follows state-of-theart techniques to aid medical professionals in these situations. It comprises an ensemble learning strategy via 5-fold cross-validation that includes transfer learning and combines pre-trained 3D-versions of ResNet34 and DenseNet121 for COVID19 classification and severity prediction respectively. Further, domain-specific preprocessing was applied to optimize model performance. In addition, medical information like the infection-lung-ratio, patient age, and sex were included. The presented model achieves an AUC of 79.0% to predict COVID-19 severity, and 83.7% AUC to classify the presence of an infection, which is comparable with other currently popular methods. This approach is implemented using the AUCMEDI framework and relies on well-known network architectures to ensure robustness and reproducibility.
GANonymization: A GAN-based Face Anonymization Framework for Preserving Emotional Expressions
May 03, 2023

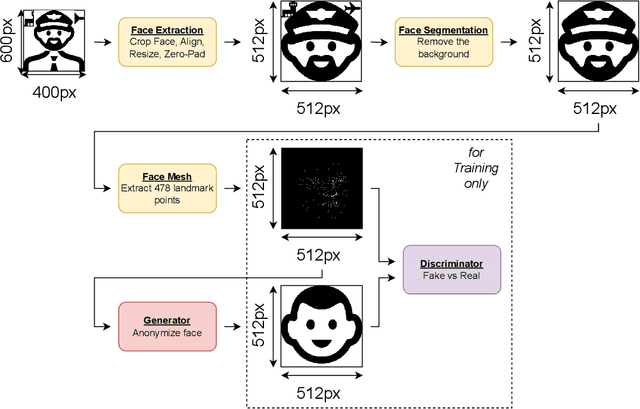

In recent years, the increasing availability of personal data has raised concerns regarding privacy and security. One of the critical processes to address these concerns is data anonymization, which aims to protect individual privacy and prevent the release of sensitive information. This research focuses on the importance of face anonymization. Therefore, we introduce GANonymization, a novel face anonymization framework with facial expression-preserving abilities. Our approach is based on a high-level representation of a face which is synthesized into an anonymized version based on a generative adversarial network (GAN). The effectiveness of the approach was assessed by evaluating its performance in removing identifiable facial attributes to increase the anonymity of the given individual face. Additionally, the performance of preserving facial expressions was evaluated on several affect recognition datasets and outperformed the state-of-the-art method in most categories. Finally, our approach was analyzed for its ability to remove various facial traits, such as jewelry, hair color, and multiple others. Here, it demonstrated reliable performance in removing these attributes. Our results suggest that GANonymization is a promising approach for anonymizing faces while preserving facial expressions.
ForDigitStress: A multi-modal stress dataset employing a digital job interview scenario
Mar 14, 2023


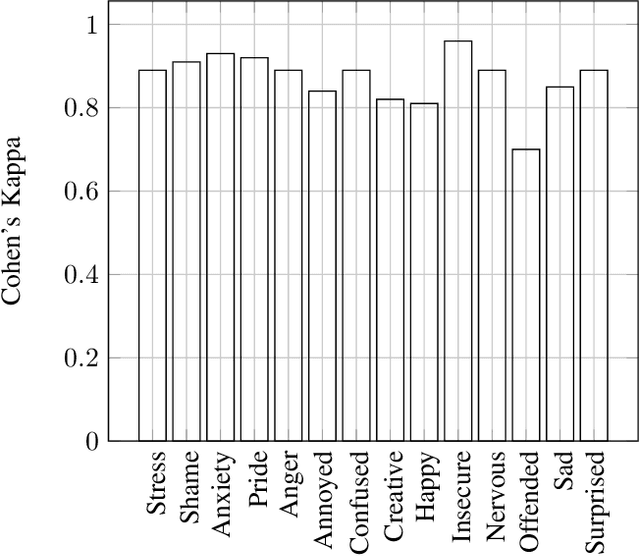
We present a multi-modal stress dataset that uses digital job interviews to induce stress. The dataset provides multi-modal data of 40 participants including audio, video (motion capturing, facial recognition, eye tracking) as well as physiological information (photoplethysmography, electrodermal activity). In addition to that, the dataset contains time-continuous annotations for stress and occurred emotions (e.g. shame, anger, anxiety, surprise). In order to establish a baseline, five different machine learning classifiers (Support Vector Machine, K-Nearest Neighbors, Random Forest, Long-Short-Term Memory Network) have been trained and evaluated on the proposed dataset for a binary stress classification task. The best-performing classifier achieved an accuracy of 88.3% and an F1-score of 87.5%.
GANterfactual-RL: Understanding Reinforcement Learning Agents' Strategies through Visual Counterfactual Explanations
Feb 24, 2023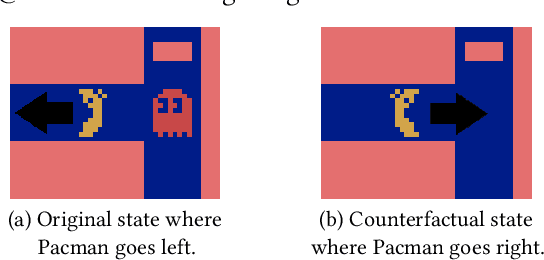

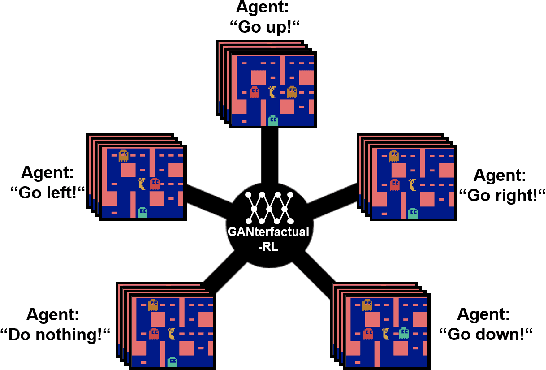

Counterfactual explanations are a common tool to explain artificial intelligence models. For Reinforcement Learning (RL) agents, they answer "Why not?" or "What if?" questions by illustrating what minimal change to a state is needed such that an agent chooses a different action. Generating counterfactual explanations for RL agents with visual input is especially challenging because of their large state spaces and because their decisions are part of an overarching policy, which includes long-term decision-making. However, research focusing on counterfactual explanations, specifically for RL agents with visual input, is scarce and does not go beyond identifying defective agents. It is unclear whether counterfactual explanations are still helpful for more complex tasks like analyzing the learned strategies of different agents or choosing a fitting agent for a specific task. We propose a novel but simple method to generate counterfactual explanations for RL agents by formulating the problem as a domain transfer problem which allows the use of adversarial learning techniques like StarGAN. Our method is fully model-agnostic and we demonstrate that it outperforms the only previous method in several computational metrics. Furthermore, we show in a user study that our method performs best when analyzing which strategies different agents pursue.