 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXAI-Grounded Explanation Generation for Speech Deepfake Detection with Training-Free Multimodal Large Language Models
Jun 15, 2026Speech deepfake detection (SDD) systems require trustworthy explanations for reliable decision-making. Existing explanation ways mainly fall into two categories. Traditional explainable AI (XAI), such as gradient-based attribution, produces low-level attribution signals tightly coupled with model decisions, and harder to be understood by human than natural language explanations. Meanwhile, large language model (LLM)-based explanation generation often produces generic and ungrounded descriptions due to the lack of heuristic evidence and task-specific supervision, stemming from limited grounded explanation datasets for SDD. We therefore propose a training-free explanation framework that integrates XAI evidence with multimodal LLMs to generate grounded and specific explanations. Using the PartialSpoof dataset, we construct a grounded explanation dataset and show that methods with XAI increase inside accuracy by over 45\%, verified through human evaluation and faithfulness checks.
Acoustic Cue Alignment in Audio Language Models for Speech Emotion Recognition
Jun 05, 2026Instruction-following audio language models (ALMs) can be augmented with explicit acoustic cues, yet it remains unclear whether such cues are used in a grounded way when the raw audio is already available. We study this question in speech emotion recognition (SER) by deriving six interpretable acoustic concept tokens from the standardised eGeMAPS paralinguistic feature set. These tokens summarise energy, pitch, dynamics, brightness, formants, and voice quality, and are appended to the textual prompt while the audio input is kept unchanged. Across the widely used FAU-Aibo and IEMOCAP benchmarks, aligned tokens improve unweighted average recall (UAR), whereas shuffled, conflicting, or corrupted tokens reduce performance relative to aligned tokens and shift confusions toward neutral. Importantly, predictions do not collapse under strong token perturbations, suggesting that the models are sensitive to the symbolic cue channel but remain partly anchored to the audio signal. We argue that token-only interventions provide a practical way to probe audio-grounded cue use, robustness, and interpretability in ALM-based affective computing.
A Pilot Study on Curator-Guided Multilingual Art Description for Blind and Low-Vision Audiences with Small Vision-Language Models
May 29, 2026Blind and low-vision (BLV) audiences remain underserved by visual art descriptions, particularly across languages and in museum settings where privacy and intellectual-property constraints may favour small on-premise vision-language models (VLMs). This pilot study investigates curator-guided multilingual art description with Qwen2.5-VL-3B-Instruct for German, Romanian, and Serbian. We construct a parallel BLV-oriented caption corpus from artwork images and metadata, and compare language-specific LoRA adapters with a single multilingual adapter under a fixed backbone and training budget. Evaluation combines automatic lexical and embedding-based metrics with an LLM-as-Judge protocol calibrated against a small Romanian BLV pilot study. Under our pilot setup, language-specific adapters show more stable controllability and visually grounded description quality for Romanian and Serbian, while multilingual adaptation remains competitive in German. We frame these findings as deployment-oriented evidence for small on-premise VLMs, and highlight the need for larger BLV user studies and broader language coverage before drawing general conclusions about multilingual accessibility.
CoarseSoundNet: Building a reliable model for ecological soundscape analysis
May 21, 2026A soundscape is composed of three types of sound: biophony (sounds made by animals), geophony (natural abiotic sounds) and anthropophony (sounds made by humans). A key research question in the field of soundscape ecology is how these components interact with each other, specifically how biophony responds to geophony and anthropophony. Nevertheless, as of today, there are not many analytical instruments that enable the distinct quantification of these elements. Recent machine learning (ML) approaches aim to support automated analysis but often rely on task-specific or clean data, limiting generalisation to noisy passive acoustic monitoring (PAM) recordings. This study presents a clear and reproducible structure to build ML models for coarse soundscape classification and introduces CoarseSoundNet, a deep learning model trained to distinguish biophony, geophony, and anthropophony under realistic PAM conditions. We systematically investigate model architectures, the influence of an additional training class, data composition, and evaluation strategies. Our findings suggest that model performance improves with additional PAM data, especially when similar to the target domain, and by introducing an explicit silence class during training. Class-specific decision thresholds and duration-based constraints further enhance performance, particularly for anthropophony and geophony. Error analyses exhibit challenges for anthropophony due to masking effects and confusions for silence and insect sounds for geophony and biophony. Finally, we conduct an ecological case study which shows that pre-filtering recordings with CoarseSoundNet yields acoustic index trends comparable to ground-truth filtering, supporting its use as an effective preprocessing tool for ecoacoustic analyses.
AffectSpeech: A Large-Scale Emotional Speech Dataset with Fine-Grained Textual Descriptions for Speech Emotion Captioning and Synthesis
Apr 05, 2026Emotion is essential in spoken communication, yet most existing frameworks in speech emotion modeling rely on predefined categories or low-dimensional continuous attributes, which offer limited expressive capacity. Recent advances in speech emotion captioning and synthesis have shown that textual descriptions provide a more flexible and interpretable alternative for representing affective characteristics in speech. However, progress in this direction is hindered by the lack of an emotional speech dataset aligned with reliable and fine-grained natural language annotations. To tackle this, we introduce AffectSpeech, a large-scale corpus of human-recorded speech enriched with structured descriptions for fine-grained emotion analysis and generation. Each utterance is characterized across six complementary dimensions, including sentiment polarity, open-vocabulary emotion captions, intensity level, prosodic attributes, prominent segments, and semantic content, enabling multi-granular modeling of vocal expression. To balance annotation quality and scalability, we adopt a human-LLM collaborative annotation pipeline that integrates algorithmic pre-labeling, multi-LLM description generation, and human-in-the-loop verification. Furthermore, these annotations are reformulated into diverse descriptive styles to enhance linguistic diversity and reduce stylistic bias in downstream modeling. Experimental results on speech emotion captioning and synthesis demonstrate that models trained on AffectSpeech consistently achieve superior performance across multiple evaluation settings.
How Class Ontology and Data Scale Affect Audio Transfer Learning
Mar 26, 2026Transfer learning is a crucial concept within deep learning that allows artificial neural networks to benefit from a large pre-training data basis when confronted with a task of limited data. Despite its ubiquitous use and clear benefits, there are still many open questions regarding the inner workings of transfer learning and, in particular, regarding the understanding of when and how well it works. To that extent, we perform a rigorous study focusing on audio-to-audio transfer learning, in which we pre-train various model states on (ontology-based) subsets of AudioSet and fine-tune them on three computer audition tasks, namely acoustic scene recognition, bird activity recognition, and speech command recognition. We report that increasing the number of samples and classes in the pre-training data both have a positive impact on transfer learning. This is, however, generally surpassed by similarity between pre-training and the downstream task, which can lead the model to learn comparable features.
Affect Decoding in Phonated and Silent Speech Production from Surface EMG
Mar 12, 2026The expression of affect is integral to spoken communication, yet, its link to underlying articulatory execution remains unclear. Measures of articulatory muscle activity such as EMG could reveal how speech production is modulated by emotion alongside acoustic speech analyses. We investigate affect decoding from facial and neck surface electromyography (sEMG) during phonated and silent speech production. For this purpose, we introduce a dataset comprising 2,780 utterances from 12 participants across 3 tasks, on which we evaluate both intra- and inter-subject decoding using a range of features and model embeddings. Our results reveal that EMG representations reliably discriminate frustration with up to 0.845 AUC, and generalize well across articulation modes. Our ablation study further demonstrates that affective signatures are embedded in facial motor activity and persist in the absence of phonation, highlighting the potential of EMG sensing for affect-aware silent speech interfaces.
Quantifying Dimensional Independence in Speech: An Information-Theoretic Framework for Disentangled Representation Learning
Feb 24, 2026Speech signals encode emotional, linguistic, and pathological information within a shared acoustic channel; however, disentanglement is typically assessed indirectly through downstream task performance. We introduce an information-theoretic framework to quantify cross-dimension statistical dependence in handcrafted acoustic features by integrating bounded neural mutual information (MI) estimation with non-parametric validation. Across six corpora, cross-dimension MI remains low, with tight estimation bounds ($< 0.15$ nats), indicating weak statistical coupling in the data considered, whereas Source--Filter MI is substantially higher (0.47 nats). Attribution analysis, defined as the proportion of total MI attributable to source versus filter components, reveals source dominance for emotional dimensions (80\%) and filter dominance for linguistic and pathological dimensions (60\% and 58\%, respectively). These findings provide a principled framework for quantifying dimensional independence in speech.
Cross-Dialect Bird Species Recognition with Dialect-Calibrated Augmentation
Sep 26, 2025Dialect variation hampers automatic recognition of bird calls collected by passive acoustic monitoring. We address the problem on DB3V, a three-region, ten-species corpus of 8-s clips, and propose a deployable framework built on Time-Delay Neural Networks (TDNNs). Frequency-sensitive normalisation (Instance Frequency Normalisation and a gated Relaxed-IFN) is paired with gradient-reversal adversarial training to learn region-invariant embeddings. A multi-level augmentation scheme combines waveform perturbations, Mixup for rare classes, and CycleGAN transfer that synthesises Region 2 (Interior Plains)-style audio, , with Dialect-Calibrated Augmentation (DCA) softly down-weighting synthetic samples to limit artifacts. The complete system lifts cross-dialect accuracy by up to twenty percentage points over baseline TDNNs while preserving in-region performance. Grad-CAM and LIME analyses show that robust models concentrate on stable harmonic bands, providing ecologically meaningful explanations. The study demonstrates that lightweight, transparent, and dialect-resilient bird-sound recognition is attainable.
Affine Modulation-based Audiogram Fusion Network for Joint Noise Reduction and Hearing Loss Compensation
Sep 09, 2025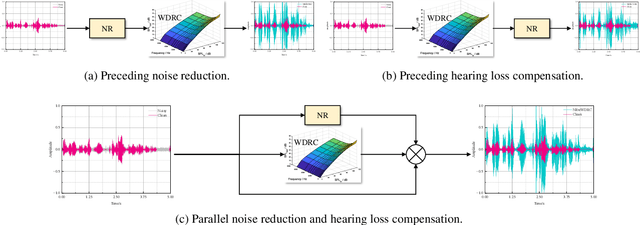
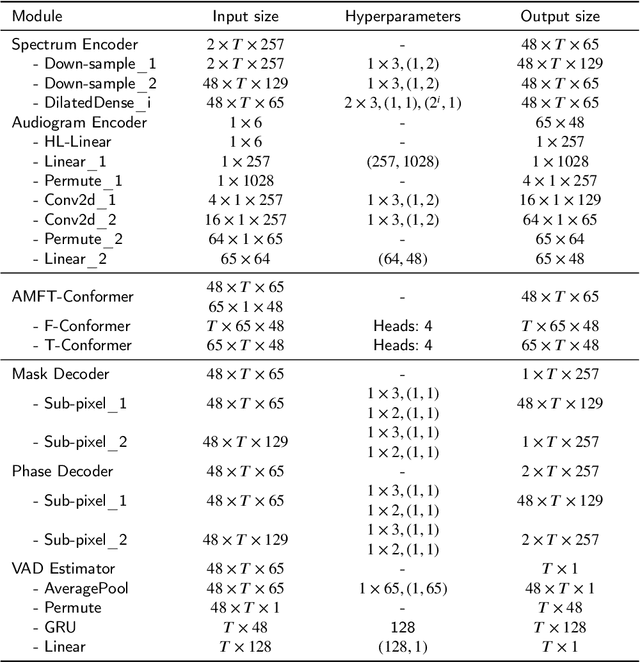
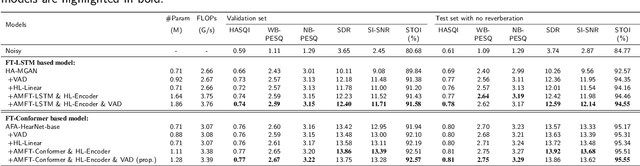
Hearing aids (HAs) are widely used to provide personalized speech enhancement (PSE) services, improving the quality of life for individuals with hearing loss. However, HA performance significantly declines in noisy environments as it treats noise reduction (NR) and hearing loss compensation (HLC) as separate tasks. This separation leads to a lack of systematic optimization, overlooking the interactions between these two critical tasks, and increases the system complexity. To address these challenges, we propose a novel audiogram fusion network, named AFN-HearNet, which simultaneously tackles the NR and HLC tasks by fusing cross-domain audiogram and spectrum features. We propose an audiogram-specific encoder that transforms the sparse audiogram profile into a deep representation, addressing the alignment problem of cross-domain features prior to fusion. To incorporate the interactions between NR and HLC tasks, we propose the affine modulation-based audiogram fusion frequency-temporal Conformer that adaptively fuses these two features into a unified deep representation for speech reconstruction. Furthermore, we introduce a voice activity detection auxiliary training task to embed speech and non-speech patterns into the unified deep representation implicitly. We conduct comprehensive experiments across multiple datasets to validate the effectiveness of each proposed module. The results indicate that the AFN-HearNet significantly outperforms state-of-the-art in-context fusion joint models regarding key metrics such as HASQI and PESQ, achieving a considerable trade-off between performance and efficiency. The source code and data will be released at https://github.com/deepnetni/AFN-HearNet.