 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All That Is Fluent Is Factual: Investigating Hallucinations of Large Language Models in Academic Writing
May 05, 2026Large Language models (LLMs) show extraordinary abilities, but they are still prone to hallucinations, especially when we use them for generating Academic content. We have investigated four popular LLMs, ChatGPT, Grok, Gemini, and Copilot for hallucinations specifically for academic writing. We have designed 80 prompts across four categories, namely, reference generation, factual explanation, abstract generation, and writing improvement. We evaluated the model using a 0-5 rubric score, which checks factual accuracy, reference validity, coherence, style consistency, and academic tone. A novel weighted metric, Hallucination Index (HI), was introduced to measure hallucination in the responses generated by the models. Some of the most widely used evaluation metrics often fail to check errors which alter sentiment in machine-translated text. We found that Grok and Copilot perform better on reference generation tasks, but they often struggle with abstract or stylistic prompts, with HI values of 0.67 and 0.70, respectively. Whereas, Gemini and ChatGPT have done well with having stronger tone control, but they lack in writing factual tasks and higher hallucination risk with HI scores of 0.53 and 0.57, respectively. Our study found that hallucination behavior does not depend solely on model architecture but also on the type of task and the prompting conditions we are providing. We propose that our work opens new research dimensions for future researchers.
IndicFairFace: Balanced Indian Face Dataset for Auditing and Mitigating Geographical Bias in Vision-Language Models
Feb 13, 2026Vision-Language Models (VLMs) are known to inherit and amplify societal biases from their web-scale training data with Indian being particularly misrepresented. Existing fairness-aware datasets have significantly improved demographic balance across global race and gender groups, yet they continue to treat Indian as a single monolithic category. The oversimplification ignores the vast intra-national diversity across 28 states and 8 Union Territories of India and leads to representational and geographical bias. To address the limitation, we present IndicFairFace, a novel and balanced face dataset comprising 14,400 images representing geographical diversity of India. Images were sourced ethically from Wikimedia Commons and open-license web repositories and uniformly balanced across states and gender. Using IndicFairFace, we quantify intra-national geographical bias in prominent CLIP-based VLMs and reduce it using post-hoc Iterative Nullspace Projection debiasing approach. We also show that the adopted debiasing approach does not adversely impact the existing embedding space as the average drop in retrieval accuracy on benchmark datasets is less than 1.5 percent. Our work establishes IndicFairFace as the first benchmark to study geographical bias in VLMs for the Indian context.
Beyond Specialization: Benchmarking LLMs for Transliteration of Indian Languages
May 26, 2025Transliteration, the process of mapping text from one script to another, plays a crucial role in multilingual natural language processing, especially within linguistically diverse contexts such as India. Despite significant advancements through specialized models like IndicXlit, recent developments in large language models suggest a potential for general-purpose models to excel at this task without explicit task-specific training. The current work systematically evaluates the performance of prominent LLMs, including GPT-4o, GPT-4.5, GPT-4.1, Gemma-3-27B-it, and Mistral-Large against IndicXlit, a state-of-the-art transliteration model, across ten major Indian languages. Experiments utilized standard benchmarks, including Dakshina and Aksharantar datasets, with performance assessed via Top-1 Accuracy and Character Error Rate. Our findings reveal that while GPT family models generally outperform other LLMs and IndicXlit for most instances. Additionally, fine-tuning GPT-4o improves performance on specific languages notably. An extensive error analysis and robustness testing under noisy conditions further elucidate strengths of LLMs compared to specialized models, highlighting the efficacy of foundational models for a wide spectrum of specialized applications with minimal overhead.
Gender Bias in Text-to-Video Generation Models: A case study of Sora
Dec 30, 2024The advent of text-to-video generation models has revolutionized content creation as it produces high-quality videos from textual prompts. However, concerns regarding inherent biases in such models have prompted scrutiny, particularly regarding gender representation. Our study investigates the presence of gender bias in OpenAI's Sora, a state-of-the-art text-to-video generation model. We uncover significant evidence of bias by analyzing the generated videos from a diverse set of gender-neutral and stereotypical prompts. The results indicate that Sora disproportionately associates specific genders with stereotypical behaviors and professions, which reflects societal prejudices embedded in its training data.
Negation Blindness in Large Language Models: Unveiling the NO Syndrome in Image Generation
Sep 04, 2024



Foundational Large Language Models (LLMs) have changed the way we perceive technology. They have been shown to excel in tasks ranging from poem writing and coding to essay generation and puzzle solving. With the incorporation of image generation capability, they have become more comprehensive and versatile AI tools. At the same time, researchers are striving to identify the limitations of these tools to improve them further. Currently identified flaws include hallucination, biases, and bypassing restricted commands to generate harmful content. In the present work, we have identified a fundamental limitation related to the image generation ability of LLMs, and termed it The NO Syndrome. This negation blindness refers to LLMs inability to correctly comprehend NO related natural language prompts to generate the desired images. Interestingly, all tested LLMs including GPT-4, Gemini, and Copilot were found to be suffering from this syndrome. To demonstrate the generalization of this limitation, we carried out simulation experiments and conducted entropy-based and benchmark statistical analysis tests on various LLMs in multiple languages, including English, Hindi, and French. We conclude that the NO syndrome is a significant flaw in current LLMs that needs to be addressed. A related finding of this study showed a consistent discrepancy between image and textual responses as a result of this NO syndrome. We posit that the introduction of a negation context-aware reinforcement learning based feedback loop between the LLMs textual response and generated image could help ensure the generated text is based on both the LLMs correct contextual understanding of the negation query and the generated visual output.
Advancing 3D Point Cloud Understanding through Deep Transfer Learning: A Comprehensive Survey
Jul 25, 2024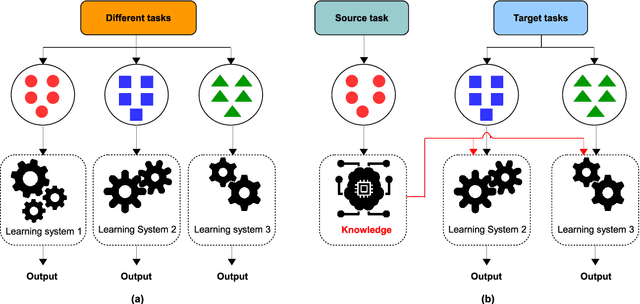
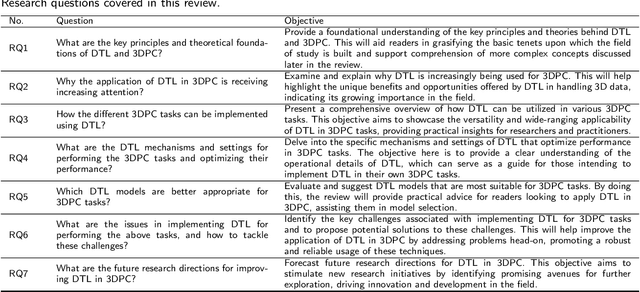
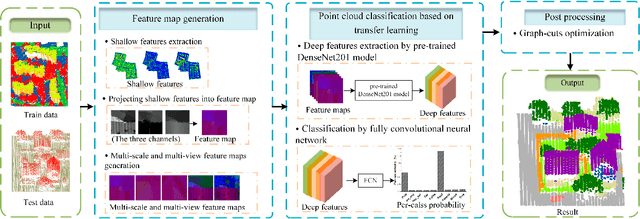
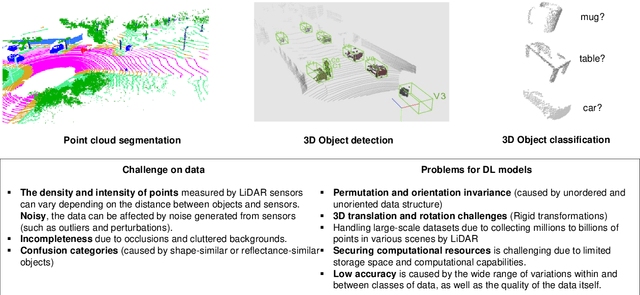
The 3D point cloud (3DPC) has significantly evolved and benefited from the advance of deep learning (DL). However, the latter faces various issues, including the lack of data or annotated data, the existence of a significant gap between training data and test data, and the requirement for high computational resources. To that end, deep transfer learning (DTL), which decreases dependency and costs by utilizing knowledge gained from a source data/task in training a target data/task, has been widely investigated. Numerous DTL frameworks have been suggested for aligning point clouds obtained from several scans of the same scene. Additionally, DA, which is a subset of DTL, has been modified to enhance the point cloud data's quality by dealing with noise and missing points. Ultimately, fine-tuning and DA approaches have demonstrated their effectiveness in addressing the distinct difficulties inherent in point cloud data. This paper presents the first review shedding light on this aspect. it provides a comprehensive overview of the latest techniques for understanding 3DPC using DTL and domain adaptation (DA). Accordingly, DTL's background is first presented along with the datasets and evaluation metrics. A well-defined taxonomy is introduced, and detailed comparisons are presented, considering different aspects such as different knowledge transfer strategies, and performance. The paper covers various applications, such as 3DPC object detection, semantic labeling, segmentation, classification, registration, downsampling/upsampling, and denoising. Furthermore, the article discusses the advantages and limitations of the presented frameworks, identifies open challenges, and suggests potential research directions.
Decoding ChatGPT: A Taxonomy of Existing Research, Current Challenges, and Possible Future Directions
Jul 26, 2023Chat Generative Pre-trained Transformer (ChatGPT) has gained significant interest and attention since its launch in November 2022. It has shown impressive performance in various domains, including passing exams and creative writing. However, challenges and concerns related to biases and trust persist. In this work, we present a comprehensive review of over 100 Scopus-indexed publications on ChatGPT, aiming to provide a taxonomy of ChatGPT research and explore its applications. We critically analyze the existing literature, identifying common approaches employed in the studies. Additionally, we investigate diverse application areas where ChatGPT has found utility, such as healthcare, marketing and financial services, software engineering, academic and scientific writing, research and education, environmental science, and natural language processing. Through examining these applications, we gain valuable insights into the potential of ChatGPT in addressing real-world challenges. We also discuss crucial issues related to ChatGPT, including biases and trustworthiness, emphasizing the need for further research and development in these areas. Furthermore, we identify potential future directions for ChatGPT research, proposing solutions to current challenges and speculating on expected advancements. By fully leveraging the capabilities of ChatGPT, we can unlock its potential across various domains, leading to advancements in conversational AI and transformative impacts in society.
Filter Bubbles in Recommender Systems: Fact or Fallacy -- A Systematic Review
Jul 02, 2023A filter bubble refers to the phenomenon where Internet customization effectively isolates individuals from diverse opinions or materials, resulting in their exposure to only a select set of content. This can lead to the reinforcement of existing attitudes, beliefs, or conditions. In this study, our primary focus is to investigate the impact of filter bubbles in recommender systems. This pioneering research aims to uncover the reasons behind this problem, explore potential solutions, and propose an integrated tool to help users avoid filter bubbles in recommender systems. To achieve this objective, we conduct a systematic literature review on the topic of filter bubbles in recommender systems. The reviewed articles are carefully analyzed and classified, providing valuable insights that inform the development of an integrated approach. Notably, our review reveals evidence of filter bubbles in recommendation systems, highlighting several biases that contribute to their existence. Moreover, we propose mechanisms to mitigate the impact of filter bubbles and demonstrate that incorporating diversity into recommendations can potentially help alleviate this issue. The findings of this timely review will serve as a benchmark for researchers working in interdisciplinary fields such as privacy, artificial intelligence ethics, and recommendation systems. Furthermore, it will open new avenues for future research in related domains, prompting further exploration and advancement in this critical area.
Can we aggregate human intelligence? an approach for human centric aggregation using ordered weighted averaging operators
May 01, 2021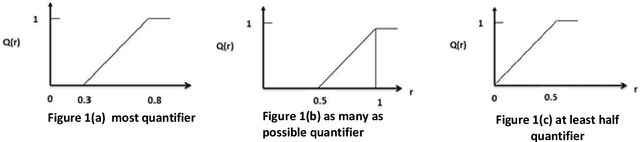
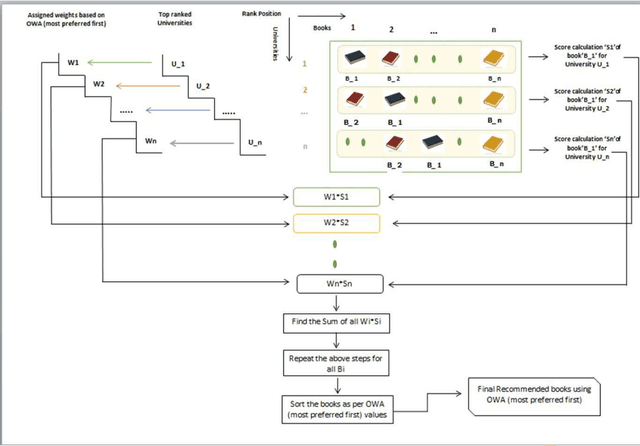
The primary objective of this paper is to present an approach for recommender systems that can assimilate ranking to the voters or rankers so that recommendation can be made by giving priority to experts suggestion over usual recommendation. To accomplish this, we have incorporated the concept of human-centric aggregation via Ordered Weighted Aggregation (OWA). Here, we are advocating ranked recommendation where rankers are assigned weights according to their place in the ranking. Further, the recommendation process which is presented here for the recommendation of books to university students exploits linguistic data summaries and Ordered Weighted Aggregation (OWA) technique. In the suggested approach, the weights are assigned in a way that it associates higher weights to best ranked university. The approach has been evaluated over eight different parameters. The superiority of the proposed approach is evident from the evaluation results. We claim that proposed scheme saves storage spaces required in traditional recommender systems as well as it does not need users prior preferences and hence produce a solution for cold start problem. This envisaged that the proposed scheme can be very useful in decision making problems, especially for recommender systems. In addition, it emphasizes on how human-centric aggregation can be useful in recommendation researches, and also it gives a new direction about how various human specific tasks can be numerically aggregated.