 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Deep Feature Extraction and ML for Construction and Demolition Debris Classification
Jan 20, 2026The construction industry produces significant volumes of debris, making effective sorting and classification critical for sustainable waste management and resource recovery. This study presents a hybrid vision-based pipeline that integrates deep feature extraction with classical machine learning (ML) classifiers for automated construction and demolition (C\&D) debris classification. A novel dataset comprising 1,800 balanced, high-quality images representing four material categories, Ceramic/Tile, Concrete, Trash/Waste, and Wood was collected from real construction sites in the UAE, capturing diverse real-world conditions. Deep features were extracted using a pre-trained Xception network, and multiple ML classifiers, including SVM, kNN, Bagged Trees, LDA, and Logistic Regression, were systematically evaluated. The results demonstrate that hybrid pipelines using Xception features with simple classifiers such as Linear SVM, kNN, and Bagged Trees achieve state-of-the-art performance, with up to 99.5\% accuracy and macro-F1 scores, surpassing more complex or end-to-end deep learning approaches. The analysis highlights the operational benefits of this approach for robust, field-deployable debris identification and provides pathways for future integration with robotics and onsite automation systems.
Exploring Image Transforms derived from Eye Gaze Variables for Progressive Autism Diagnosis
Jun 07, 2025The prevalence of Autism Spectrum Disorder (ASD) has surged rapidly over the past decade, posing significant challenges in communication, behavior, and focus for affected individuals. Current diagnostic techniques, though effective, are time-intensive, leading to high social and economic costs. This work introduces an AI-powered assistive technology designed to streamline ASD diagnosis and management, enhancing convenience for individuals with ASD and efficiency for caregivers and therapists. The system integrates transfer learning with image transforms derived from eye gaze variables to diagnose ASD. This facilitates and opens opportunities for in-home periodical diagnosis, reducing stress for individuals and caregivers, while also preserving user privacy through the use of image transforms. The accessibility of the proposed method also offers opportunities for improved communication between guardians and therapists, ensuring regular updates on progress and evolving support needs. Overall, the approach proposed in this work ensures timely, accessible diagnosis while protecting the subjects' privacy, improving outcomes for individuals with ASD.
Hybrid Vision Transformer-Mamba Framework for Autism Diagnosis via Eye-Tracking Analysis
Jun 07, 2025

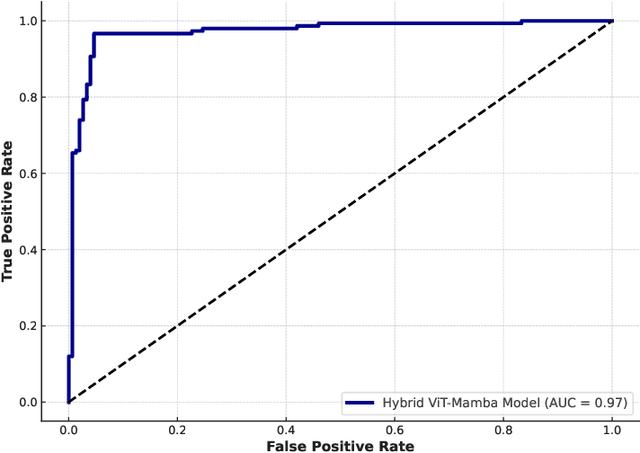

Accurate Autism Spectrum Disorder (ASD) diagnosis is vital for early intervention. This study presents a hybrid deep learning framework combining Vision Transformers (ViT) and Vision Mamba to detect ASD using eye-tracking data. The model uses attention-based fusion to integrate visual, speech, and facial cues, capturing both spatial and temporal dynamics. Unlike traditional handcrafted methods, it applies state-of-the-art deep learning and explainable AI techniques to enhance diagnostic accuracy and transparency. Tested on the Saliency4ASD dataset, the proposed ViT-Mamba model outperformed existing methods, achieving 0.96 accuracy, 0.95 F1-score, 0.97 sensitivity, and 0.94 specificity. These findings show the model's promise for scalable, interpretable ASD screening, especially in resource-constrained or remote clinical settings where access to expert diagnosis is limited.
Advancing 3D Point Cloud Understanding through Deep Transfer Learning: A Comprehensive Survey
Jul 25, 2024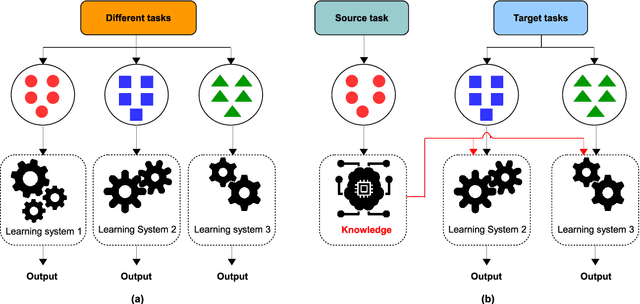
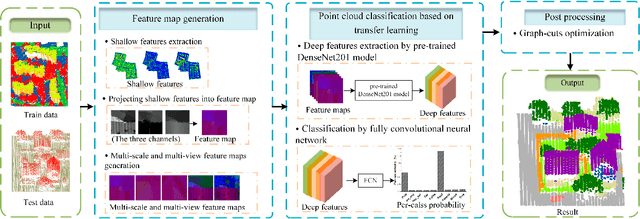
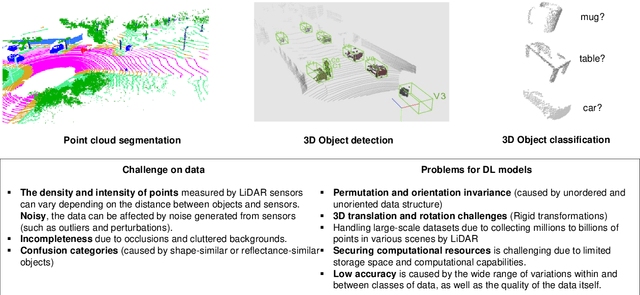
The 3D point cloud (3DPC) has significantly evolved and benefited from the advance of deep learning (DL). However, the latter faces various issues, including the lack of data or annotated data, the existence of a significant gap between training data and test data, and the requirement for high computational resources. To that end, deep transfer learning (DTL), which decreases dependency and costs by utilizing knowledge gained from a source data/task in training a target data/task, has been widely investigated. Numerous DTL frameworks have been suggested for aligning point clouds obtained from several scans of the same scene. Additionally, DA, which is a subset of DTL, has been modified to enhance the point cloud data's quality by dealing with noise and missing points. Ultimately, fine-tuning and DA approaches have demonstrated their effectiveness in addressing the distinct difficulties inherent in point cloud data. This paper presents the first review shedding light on this aspect. it provides a comprehensive overview of the latest techniques for understanding 3DPC using DTL and domain adaptation (DA). Accordingly, DTL's background is first presented along with the datasets and evaluation metrics. A well-defined taxonomy is introduced, and detailed comparisons are presented, considering different aspects such as different knowledge transfer strategies, and performance. The paper covers various applications, such as 3DPC object detection, semantic labeling, segmentation, classification, registration, downsampling/upsampling, and denoising. Furthermore, the article discusses the advantages and limitations of the presented frameworks, identifies open challenges, and suggests potential research directions.
DASEE A Synthetic Database of Domestic Acoustic Scenes and Events in Dementia Patients Environment
May 13, 2021



Access to informative databases is a crucial part of notable research developments. In the field of domestic audio classification, there have been significant advances in recent years. Although several audio databases exist, these can be limited in terms of the amount of information they provide, such as the exact location of the sound sources, and the associated noise levels. In this work, we detail our approach on generating an unbiased synthetic domestic audio database, consisting of sound scenes and events, emulated in both quiet and noisy environments. Data is carefully curated such that it reflects issues commonly faced in a dementia patients environment, and recreate scenarios that could occur in real-world settings. Similarly, the room impulse response generated is based on a typical one-bedroom apartment at Hebrew SeniorLife Facility. As a result, we present an 11-class database containing excerpts of clean and noisy signals at 5-seconds duration each, uniformly sampled at 16 kHz. Using our baseline model using Continues Wavelet Transform Scalograms and AlexNet, this yielded a weighted F1-score of 86.24 percent.