 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT3: Test-Time Model Merging in VLMs for Zero-Shot Medical Imaging Analysis
Oct 31, 2025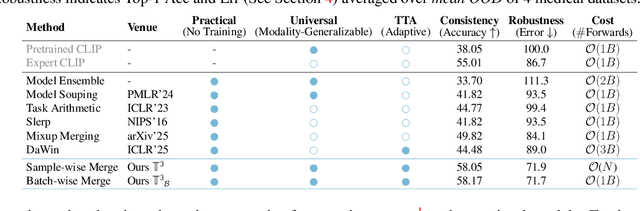
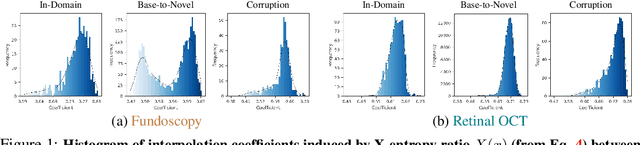
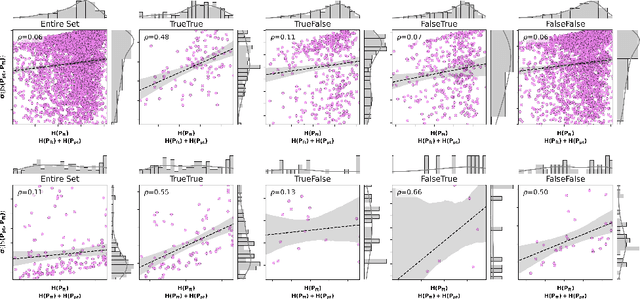
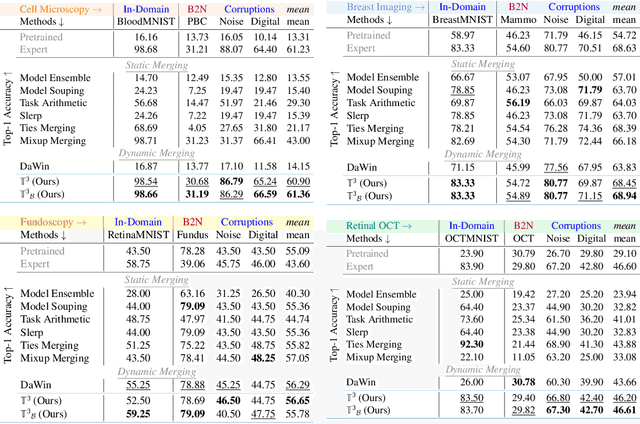
In medical imaging, vision-language models face a critical duality: pretrained networks offer broad robustness but lack subtle, modality-specific characteristics, while fine-tuned expert models achieve high in-distribution accuracy yet falter under modality shift. Existing model-merging techniques, designed for natural-image benchmarks, are simple and efficient but fail to deliver consistent gains across diverse medical modalities; their static interpolation limits reliability in varied clinical tasks. To address this, we introduce Test-Time Task adaptive merging (T^3), a backpropagation-free framework that computes per-sample interpolation coefficients via the Jensen-Shannon divergence between the two models' output distributions. T^3 dynamically preserves local precision when models agree and defers to generalist robustness under drift. To overcome the inference costs of sample-wise merging, we further propose a batch-wise extension, T^3_B, that computes a merging coefficient across a batch of samples, dramatically reducing computational bottleneck. Recognizing the lack of a standardized medical-merging benchmark, we present a rigorous cross-evaluation protocol spanning in-domain, base-to-novel, and corruptions across four modalities. Empirically, T^3 sets new state-of-the-art in Top-1 accuracy and error reduction, outperforming strong baselines while maintaining efficiency, paving the way for adaptive MVLM deployment in clinical settings. Our code is available at https://github.com/Razaimam45/TCube.
Decoupling Clinical and Class-Agnostic Features for Reliable Few-Shot Adaptation under Shift
Sep 11, 2025Medical vision-language models (VLMs) offer promise for clinical decision support, yet their reliability under distribution shifts remains a major concern for safe deployment. These models often learn task-agnostic correlations due to variability in imaging protocols and free-text reports, limiting their generalizability and increasing the risk of failure in real-world settings. We propose DRiFt, a structured feature decoupling framework that explicitly separates clinically relevant signals from task-agnostic noise using parameter-efficient tuning (LoRA) and learnable prompt tokens. To enhance cross-modal alignment and reduce uncertainty, we curate high-quality, clinically grounded image-text pairs by generating captions for a diverse medical dataset. Our approach improves in-distribution performance by +11.4% Top-1 accuracy and +3.3% Macro-F1 over prior prompt-based methods, while maintaining strong robustness across unseen datasets. Ablation studies reveal that disentangling task-relevant features and careful alignment significantly enhance model generalization and reduce unpredictable behavior under domain shift. These insights contribute toward building safer, more trustworthy VLMs for clinical use. The code is available at https://github.com/rumaima/DRiFt.
On the Robustness of Medical Vision-Language Models: Are they Truly Generalizable?
May 21, 2025Medical Vision-Language Models (MVLMs) have achieved par excellence generalization in medical image analysis, yet their performance under noisy, corrupted conditions remains largely untested. Clinical imaging is inherently susceptible to acquisition artifacts and noise; however, existing evaluations predominantly assess generally clean datasets, overlooking robustness -- i.e., the model's ability to perform under real-world distortions. To address this gap, we first introduce MediMeta-C, a corruption benchmark that systematically applies several perturbations across multiple medical imaging datasets. Combined with MedMNIST-C, this establishes a comprehensive robustness evaluation framework for MVLMs. We further propose RobustMedCLIP, a visual encoder adaptation of a pretrained MVLM that incorporates few-shot tuning to enhance resilience against corruptions. Through extensive experiments, we benchmark 5 major MVLMs across 5 medical imaging modalities, revealing that existing models exhibit severe degradation under corruption and struggle with domain-modality tradeoffs. Our findings highlight the necessity of diverse training and robust adaptation strategies, demonstrating that efficient low-rank adaptation when paired with few-shot tuning, improves robustness while preserving generalization across modalities.
Noise is an Efficient Learner for Zero-Shot Vision-Language Models
Feb 09, 2025Recently, test-time adaptation has garnered attention as a method for tuning models without labeled data. The conventional modus operandi for adapting pre-trained vision-language models (VLMs) during test-time primarily focuses on tuning learnable prompts; however, this approach overlooks potential distribution shifts in the visual representations themselves. In this work, we address this limitation by introducing Test-Time Noise Tuning (TNT), a novel method for handling unpredictable shifts in the visual space. TNT leverages, for the first time, a noise adaptation strategy that optimizes learnable noise directly in the visual input space, enabling adaptive feature learning from a single test sample. We further introduce a novel approach for inter-view representation alignment by explicitly enforcing coherence in embedding distances, ensuring consistent feature representations across views. Combined with scaled logits and confident view selection at inference, TNT substantially enhances VLM generalization and calibration, achieving average gains of +7.38% on natural distributions benchmark and +0.80% on cross-dataset evaluations over zero-shot CLIP. These improvements lay a strong foundation for adaptive out-of-distribution handling.
Introducing SDICE: An Index for Assessing Diversity of Synthetic Medical Datasets
Sep 28, 2024



Advancements in generative modeling are pushing the state-of-the-art in synthetic medical image generation. These synthetic images can serve as an effective data augmentation method to aid the development of more accurate machine learning models for medical image analysis. While the fidelity of these synthetic images has progressively increased, the diversity of these images is an understudied phenomenon. In this work, we propose the SDICE index, which is based on the characterization of similarity distributions induced by a contrastive encoder. Given a synthetic dataset and a reference dataset of real images, the SDICE index measures the distance between the similarity score distributions of original and synthetic images, where the similarity scores are estimated using a pre-trained contrastive encoder. This distance is then normalized using an exponential function to provide a consistent metric that can be easily compared across domains. Experiments conducted on the MIMIC-chest X-ray and ImageNet datasets demonstrate the effectiveness of SDICE index in assessing synthetic medical dataset diversity.
MedUnA: Language guided Unsupervised Adaptation of Vision-Language Models for Medical Image Classification
Sep 03, 2024In medical image classification, supervised learning is challenging due to the lack of labeled medical images. Contrary to the traditional \textit{modus operandi} of pre-training followed by fine-tuning, this work leverages the visual-textual alignment within Vision-Language models (\texttt{VLMs}) to facilitate the unsupervised learning. Specifically, we propose \underline{Med}ical \underline{Un}supervised \underline{A}daptation (\texttt{MedUnA}), constituting two-stage training: Adapter Pre-training, and Unsupervised Learning. In the first stage, we use descriptions generated by a Large Language Model (\texttt{LLM}) corresponding to class labels, which are passed through the text encoder \texttt{BioBERT}. The resulting text embeddings are then aligned with the class labels by training a lightweight \texttt{adapter}. We choose \texttt{\texttt{LLMs}} because of their capability to generate detailed, contextually relevant descriptions to obtain enhanced text embeddings. In the second stage, the trained \texttt{adapter} is integrated with the visual encoder of \texttt{MedCLIP}. This stage employs a contrastive entropy-based loss and prompt tuning to align visual embeddings. We incorporate self-entropy minimization into the overall training objective to ensure more confident embeddings, which are crucial for effective unsupervised learning and alignment. We evaluate the performance of \texttt{MedUnA} on three different kinds of data modalities - chest X-rays, eye fundus and skin lesion images. The results demonstrate significant accuracy gain on average compared to the baselines across different datasets, highlighting the efficacy of our approach.
Test-Time Low Rank Adaptation via Confidence Maximization for Zero-Shot Generalization of Vision-Language Models
Jul 22, 2024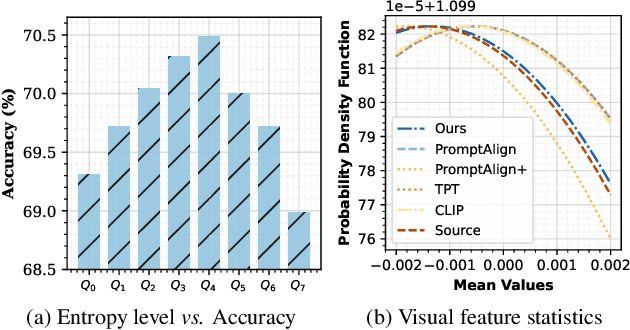

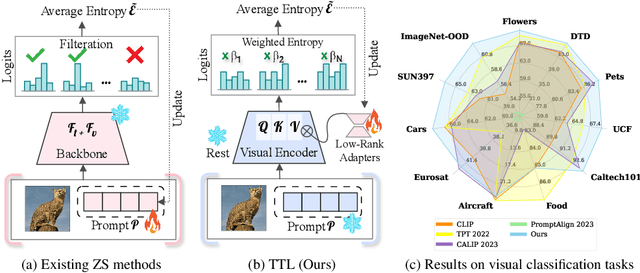
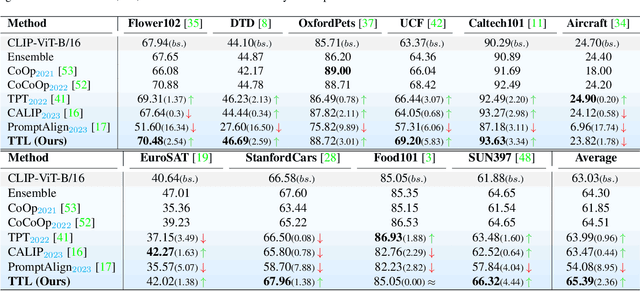
The conventional modus operandi for adapting pre-trained vision-language models (VLMs) during test-time involves tuning learnable prompts, ie, test-time prompt tuning. This paper introduces Test-Time Low-rank adaptation (TTL) as an alternative to prompt tuning for zero-shot generalization of large-scale VLMs. Taking inspiration from recent advancements in efficiently fine-tuning large language models, TTL offers a test-time parameter-efficient adaptation approach that updates the attention weights of the transformer encoder by maximizing prediction confidence. The self-supervised confidence maximization objective is specified using a weighted entropy loss that enforces consistency among predictions of augmented samples. TTL introduces only a small amount of trainable parameters for low-rank adapters in the model space while keeping the prompts and backbone frozen. Extensive experiments on a variety of natural distribution and cross-domain tasks show that TTL can outperform other techniques for test-time optimization of VLMs in strict zero-shot settings. Specifically, TTL outperforms test-time prompt tuning baselines with a significant improvement on average. Our code is available at at https://github.com/Razaimam45/TTL-Test-Time-Low-Rank-Adaptation.
CosmoCLIP: Generalizing Large Vision-Language Models for Astronomical Imaging
Jul 10, 2024



Existing vision-text contrastive learning models enhance representation transferability and support zero-shot prediction by matching paired image and caption embeddings while pushing unrelated pairs apart. However, astronomical image-label datasets are significantly smaller compared to general image and label datasets available from the internet. We introduce CosmoCLIP, an astronomical image-text contrastive learning framework precisely fine-tuned on the pre-trained CLIP model using SpaceNet and BLIP-based captions. SpaceNet, attained via FLARE, constitutes ~13k optimally distributed images, while BLIP acts as a rich knowledge extractor. The rich semantics derived from this SpaceNet and BLIP descriptions, when learned contrastively, enable CosmoCLIP to achieve superior generalization across various in-domain and out-of-domain tasks. Our results demonstrate that CosmoCLIP is a straightforward yet powerful framework, significantly outperforming CLIP in zero-shot classification and image-text retrieval tasks.
AstroSpy: On detecting Fake Images in Astronomy via Joint Image-Spectral Representations
Jul 09, 2024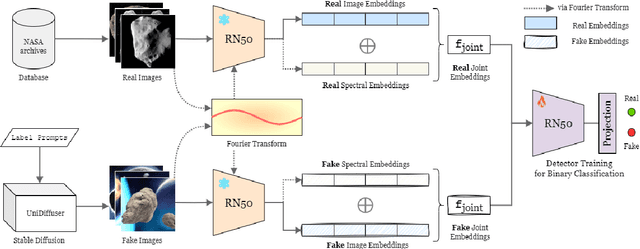
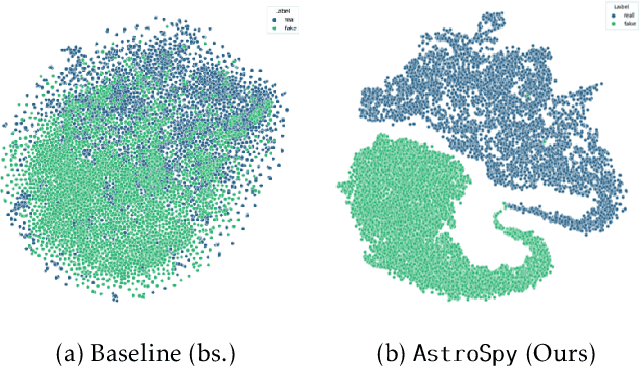
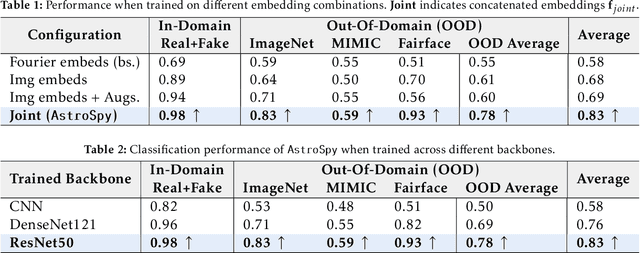

The prevalence of AI-generated imagery has raised concerns about the authenticity of astronomical images, especially with advanced text-to-image models like Stable Diffusion producing highly realistic synthetic samples. Existing detection methods, primarily based on convolutional neural networks (CNNs) or spectral analysis, have limitations when used independently. We present AstroSpy, a hybrid model that integrates both spectral and image features to distinguish real from synthetic astronomical images. Trained on a unique dataset of real NASA images and AI-generated fakes (approximately 18k samples), AstroSpy utilizes a dual-pathway architecture to fuse spatial and spectral information. This approach enables AstroSpy to achieve superior performance in identifying authentic astronomical images. Extensive evaluations demonstrate AstroSpy's effectiveness and robustness, significantly outperforming baseline models in both in-domain and cross-domain tasks, highlighting its potential to combat misinformation in astronomy.
FLARE up your data: Diffusion-based Augmentation Method in Astronomical Imaging
May 22, 2024The intersection of Astronomy and AI encounters significant challenges related to issues such as noisy backgrounds, lower resolution (LR), and the intricate process of filtering and archiving images from advanced telescopes like the James Webb. Given the dispersion of raw images in feature space, we have proposed a \textit{two-stage augmentation framework} entitled as \textbf{FLARE} based on \underline{f}eature \underline{l}earning and \underline{a}ugmented \underline{r}esolution \underline{e}nhancement. We first apply lower (LR) to higher resolution (HR) conversion followed by standard augmentations. Secondly, we integrate a diffusion approach to synthetically generate samples using class-concatenated prompts. By merging these two stages using weighted percentiles, we realign the feature space distribution, enabling a classification model to establish a distinct decision boundary and achieve superior generalization on various in-domain and out-of-domain tasks. We conducted experiments on several downstream cosmos datasets and on our optimally distributed \textbf{SpaceNet} dataset across 8-class fine-grained and 4-class macro classification tasks. FLARE attains the highest performance gain of 20.78\% for fine-grained tasks compared to similar baselines, while across different classification models, FLARE shows a consistent increment of an average of +15\%. This outcome underscores the effectiveness of the FLARE method in enhancing the precision of image classification, ultimately bolstering the reliability of astronomical research outcomes. % Our code and SpaceNet dataset will be released to the public soon. Our code and SpaceNet dataset is available at \href{https://github.com/Razaimam45/PlanetX_Dxb}{\textit{https://github.com/Razaimam45/PlanetX\_Dxb}}.