 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Low Rank Adaptation via Confidence Maximization for Zero-Shot Generalization of Vision-Language Models
Paper and Code
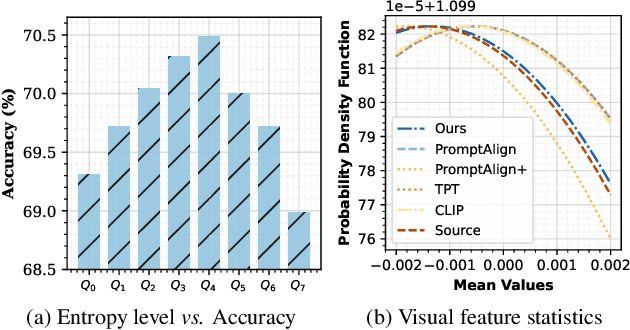

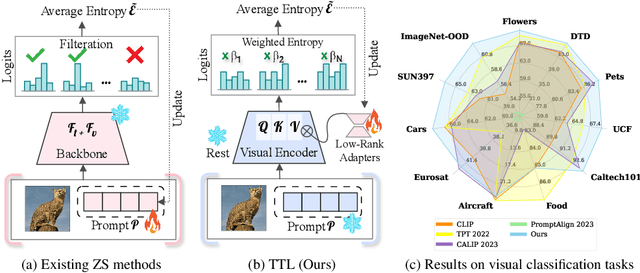
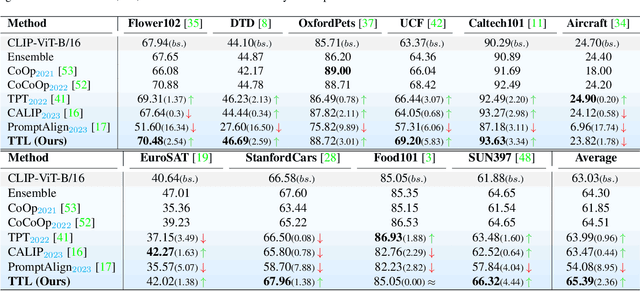
The conventional modus operandi for adapting pre-trained vision-language models (VLMs) during test-time involves tuning learnable prompts, ie, test-time prompt tuning. This paper introduces Test-Time Low-rank adaptation (TTL) as an alternative to prompt tuning for zero-shot generalization of large-scale VLMs. Taking inspiration from recent advancements in efficiently fine-tuning large language models, TTL offers a test-time parameter-efficient adaptation approach that updates the attention weights of the transformer encoder by maximizing prediction confidence. The self-supervised confidence maximization objective is specified using a weighted entropy loss that enforces consistency among predictions of augmented samples. TTL introduces only a small amount of trainable parameters for low-rank adapters in the model space while keeping the prompts and backbone frozen. Extensive experiments on a variety of natural distribution and cross-domain tasks show that TTL can outperform other techniques for test-time optimization of VLMs in strict zero-shot settings. Specifically, TTL outperforms test-time prompt tuning baselines with a significant improvement on average. Our code is available at at https://github.com/Razaimam45/TTL-Test-Time-Low-Rank-Adaptation.