 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoMolmo: Spatio-Temporal Grounding Meets Pointing
Jun 05, 2025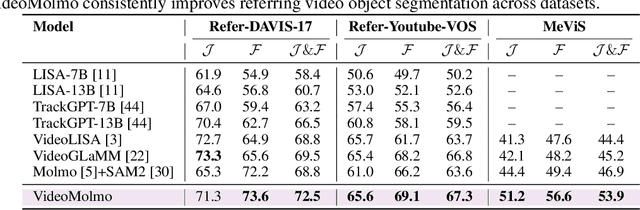
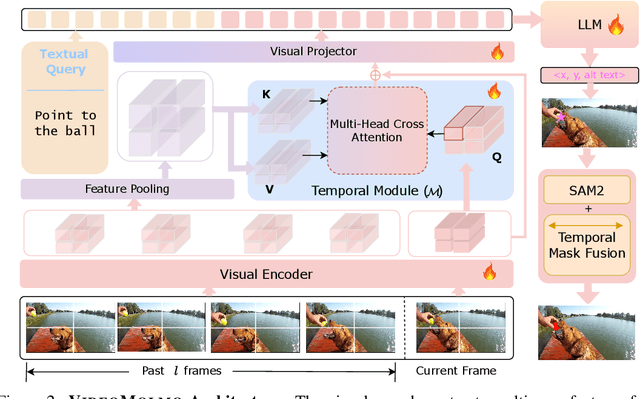

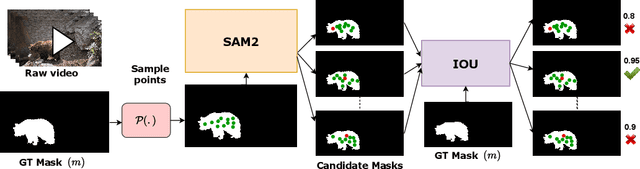
Spatio-temporal localization is vital for precise interactions across diverse domains, from biological research to autonomous navigation and interactive interfaces. Current video-based approaches, while proficient in tracking, lack the sophisticated reasoning capabilities of large language models, limiting their contextual understanding and generalization. We introduce VideoMolmo, a large multimodal model tailored for fine-grained spatio-temporal pointing conditioned on textual descriptions. Building upon the Molmo architecture, VideoMolmo incorporates a temporal module utilizing an attention mechanism to condition each frame on preceding frames, ensuring temporal consistency. Additionally, our novel temporal mask fusion pipeline employs SAM2 for bidirectional point propagation, significantly enhancing coherence across video sequences. This two-step decomposition, i.e., first using the LLM to generate precise pointing coordinates, then relying on a sequential mask-fusion module to produce coherent segmentation, not only simplifies the task for the language model but also enhances interpretability. Due to the lack of suitable datasets, we curate a comprehensive dataset comprising 72k video-caption pairs annotated with 100k object points. To evaluate the generalization of VideoMolmo, we introduce VPoS-Bench, a challenging out-of-distribution benchmark spanning five real-world scenarios: Cell Tracking, Egocentric Vision, Autonomous Driving, Video-GUI Interaction, and Robotics. We also evaluate our model on Referring Video Object Segmentation (Refer-VOS) and Reasoning VOS tasks. In comparison to existing models, VideoMolmo substantially improves spatio-temporal pointing accuracy and reasoning capability. Our code and models are publicly available at https://github.com/mbzuai-oryx/VideoMolmo.
Aurelia: Test-time Reasoning Distillation in Audio-Visual LLMs
Mar 29, 2025Recent advancements in reasoning optimization have greatly enhanced the performance of large language models (LLMs). However, existing work fails to address the complexities of audio-visual scenarios, underscoring the need for further research. In this paper, we introduce AURELIA, a novel actor-critic based audio-visual (AV) reasoning framework that distills structured, step-by-step reasoning into AVLLMs at test time, improving their ability to process complex multi-modal inputs without additional training or fine-tuning. To further advance AVLLM reasoning skills, we present AVReasonBench, a challenging benchmark comprising 4500 audio-visual questions, each paired with detailed step-by-step reasoning. Our benchmark spans six distinct tasks, including AV-GeoIQ, which evaluates AV reasoning combined with geographical and cultural knowledge. Evaluating 18 AVLLMs on AVReasonBench reveals significant limitations in their multi-modal reasoning capabilities. Using AURELIA, we achieve up to a 100% relative improvement, demonstrating its effectiveness. This performance gain highlights the potential of reasoning-enhanced data generation for advancing AVLLMs in real-world applications. Our code and data will be publicly released at: https: //github.com/schowdhury671/aurelia.
VideoGLaMM: A Large Multimodal Model for Pixel-Level Visual Grounding in Videos
Nov 07, 2024



Fine-grained alignment between videos and text is challenging due to complex spatial and temporal dynamics in videos. Existing video-based Large Multimodal Models (LMMs) handle basic conversations but struggle with precise pixel-level grounding in videos. To address this, we introduce VideoGLaMM, a LMM designed for fine-grained pixel-level grounding in videos based on user-provided textual inputs. Our design seamlessly connects three key components: a Large Language Model, a dual vision encoder that emphasizes both spatial and temporal details, and a spatio-temporal decoder for accurate mask generation. This connection is facilitated via tunable V-L and L-V adapters that enable close Vision-Language (VL) alignment. The architecture is trained to synchronize both spatial and temporal elements of video content with textual instructions. To enable fine-grained grounding, we curate a multimodal dataset featuring detailed visually-grounded conversations using a semiautomatic annotation pipeline, resulting in a diverse set of 38k video-QA triplets along with 83k objects and 671k masks. We evaluate VideoGLaMM on three challenging tasks: Grounded Conversation Generation, Visual Grounding, and Referring Video Segmentation. Experimental results show that our model consistently outperforms existing approaches across all three tasks.
AgriCLIP: Adapting CLIP for Agriculture and Livestock via Domain-Specialized Cross-Model Alignment
Oct 02, 2024Capitalizing on vast amount of image-text data, large-scale vision-language pre-training has demonstrated remarkable zero-shot capabilities and has been utilized in several applications. However, models trained on general everyday web-crawled data often exhibit sub-optimal performance for specialized domains, likely due to domain shift. Recent works have tackled this problem for some domains (e.g., healthcare) by constructing domain-specialized image-text data. However, constructing a dedicated large-scale image-text dataset for sustainable area of agriculture and livestock is still open to research. Further, this domain desires fine-grained feature learning due to the subtle nature of the downstream tasks (e.g, nutrient deficiency detection, livestock breed classification). To address this we present AgriCLIP, a vision-language foundational model dedicated to the domain of agriculture and livestock. First, we propose a large-scale dataset, named ALive, that leverages customized prompt generation strategy to overcome the scarcity of expert annotations. Our ALive dataset covers crops, livestock, and fishery, with around 600,000 image-text pairs. Second, we propose a training pipeline that integrates both contrastive and self-supervised learning to learn both global semantic and local fine-grained domain-specialized features. Experiments on diverse set of 20 downstream tasks demonstrate the effectiveness of AgriCLIP framework, achieving an absolute gain of 7.8\% in terms of average zero-shot classification accuracy, over the standard CLIP adaptation via domain-specialized ALive dataset. Our ALive dataset and code can be accessible at \href{https://github.com/umair1221/AgriCLIP/tree/main}{Github}.
Test-Time Low Rank Adaptation via Confidence Maximization for Zero-Shot Generalization of Vision-Language Models
Jul 22, 2024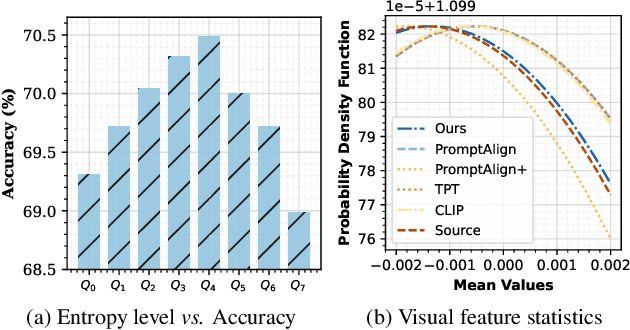

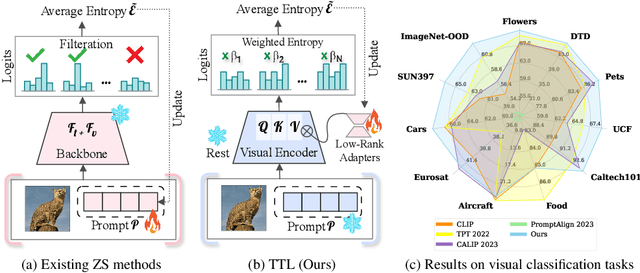
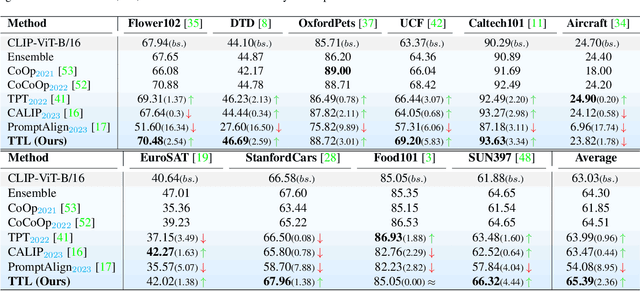
The conventional modus operandi for adapting pre-trained vision-language models (VLMs) during test-time involves tuning learnable prompts, ie, test-time prompt tuning. This paper introduces Test-Time Low-rank adaptation (TTL) as an alternative to prompt tuning for zero-shot generalization of large-scale VLMs. Taking inspiration from recent advancements in efficiently fine-tuning large language models, TTL offers a test-time parameter-efficient adaptation approach that updates the attention weights of the transformer encoder by maximizing prediction confidence. The self-supervised confidence maximization objective is specified using a weighted entropy loss that enforces consistency among predictions of augmented samples. TTL introduces only a small amount of trainable parameters for low-rank adapters in the model space while keeping the prompts and backbone frozen. Extensive experiments on a variety of natural distribution and cross-domain tasks show that TTL can outperform other techniques for test-time optimization of VLMs in strict zero-shot settings. Specifically, TTL outperforms test-time prompt tuning baselines with a significant improvement on average. Our code is available at at https://github.com/Razaimam45/TTL-Test-Time-Low-Rank-Adaptation.
VANE-Bench: Video Anomaly Evaluation Benchmark for Conversational LMMs
Jun 14, 2024



The recent developments in Large Multi-modal Video Models (Video-LMMs) have significantly enhanced our ability to interpret and analyze video data. Despite their impressive capabilities, current Video-LMMs have not been evaluated for anomaly detection tasks, which is critical to their deployment in practical scenarios e.g., towards identifying deepfakes, manipulated video content, traffic accidents and crimes. In this paper, we introduce VANE-Bench, a benchmark designed to assess the proficiency of Video-LMMs in detecting and localizing anomalies and inconsistencies in videos. Our dataset comprises an array of videos synthetically generated using existing state-of-the-art text-to-video generation models, encompassing a variety of subtle anomalies and inconsistencies grouped into five categories: unnatural transformations, unnatural appearance, pass-through, disappearance and sudden appearance. Additionally, our benchmark features real-world samples from existing anomaly detection datasets, focusing on crime-related irregularities, atypical pedestrian behavior, and unusual events. The task is structured as a visual question-answering challenge to gauge the models' ability to accurately detect and localize the anomalies within the videos. We evaluate nine existing Video-LMMs, both open and closed sources, on this benchmarking task and find that most of the models encounter difficulties in effectively identifying the subtle anomalies. In conclusion, our research offers significant insights into the current capabilities of Video-LMMs in the realm of anomaly detection, highlighting the importance of our work in evaluating and improving these models for real-world applications. Our code and data is available at https://hananshafi.github.io/vane-benchmark/
MedContext: Learning Contextual Cues for Efficient Volumetric Medical Segmentation
Feb 27, 2024



Volumetric medical segmentation is a critical component of 3D medical image analysis that delineates different semantic regions. Deep neural networks have significantly improved volumetric medical segmentation, but they generally require large-scale annotated data to achieve better performance, which can be expensive and prohibitive to obtain. To address this limitation, existing works typically perform transfer learning or design dedicated pretraining-finetuning stages to learn representative features. However, the mismatch between the source and target domain can make it challenging to learn optimal representation for volumetric data, while the multi-stage training demands higher compute as well as careful selection of stage-specific design choices. In contrast, we propose a universal training framework called MedContext that is architecture-agnostic and can be incorporated into any existing training framework for 3D medical segmentation. Our approach effectively learns self supervised contextual cues jointly with the supervised voxel segmentation task without requiring large-scale annotated volumetric medical data or dedicated pretraining-finetuning stages. The proposed approach induces contextual knowledge in the network by learning to reconstruct the missing organ or parts of an organ in the output segmentation space. The effectiveness of MedContext is validated across multiple 3D medical datasets and four state-of-the-art model architectures. Our approach demonstrates consistent gains in segmentation performance across datasets and different architectures even in few-shot data scenarios. Our code and pretrained models are available at https://github.com/hananshafi/MedContext
Multi-Attribute Vision Transformers are Efficient and Robust Learners
Feb 12, 2024



Since their inception, Vision Transformers (ViTs) have emerged as a compelling alternative to Convolutional Neural Networks (CNNs) across a wide spectrum of tasks. ViTs exhibit notable characteristics, including global attention, resilience against occlusions, and adaptability to distribution shifts. One underexplored aspect of ViTs is their potential for multi-attribute learning, referring to their ability to simultaneously grasp multiple attribute-related tasks. In this paper, we delve into the multi-attribute learning capability of ViTs, presenting a straightforward yet effective strategy for training various attributes through a single ViT network as distinct tasks. We assess the resilience of multi-attribute ViTs against adversarial attacks and compare their performance against ViTs designed for single attributes. Moreover, we further evaluate the robustness of multi-attribute ViTs against a recent transformer based attack called Patch-Fool. Our empirical findings on the CelebA dataset provide validation for our assertion.
Align Your Prompts: Test-Time Prompting with Distribution Alignment for Zero-Shot Generalization
Nov 02, 2023



The promising zero-shot generalization of vision-language models such as CLIP has led to their adoption using prompt learning for numerous downstream tasks. Previous works have shown test-time prompt tuning using entropy minimization to adapt text prompts for unseen domains. While effective, this overlooks the key cause for performance degradation to unseen domains -- distribution shift. In this work, we explicitly handle this problem by aligning the out-of-distribution (OOD) test sample statistics to those of the source data using prompt tuning. We use a single test sample to adapt multi-modal prompts at test time by minimizing the feature distribution shift to bridge the gap in the test domain. Evaluating against the domain generalization benchmark, our method improves zero-shot top- 1 accuracy beyond existing prompt-learning techniques, with a 3.08% improvement over the baseline MaPLe. In cross-dataset generalization with unseen categories across 10 datasets, our method improves consistently across all datasets compared to the existing state-of-the-art. Our source code and models are available at https://jameelhassan.github.io/promptalign.
LLM Blueprint: Enabling Text-to-Image Generation with Complex and Detailed Prompts
Oct 16, 2023



Diffusion-based generative models have significantly advanced text-to-image generation but encounter challenges when processing lengthy and intricate text prompts describing complex scenes with multiple objects. While excelling in generating images from short, single-object descriptions, these models often struggle to faithfully capture all the nuanced details within longer and more elaborate textual inputs. In response, we present a novel approach leveraging Large Language Models (LLMs) to extract critical components from text prompts, including bounding box coordinates for foreground objects, detailed textual descriptions for individual objects, and a succinct background context. These components form the foundation of our layout-to-image generation model, which operates in two phases. The initial Global Scene Generation utilizes object layouts and background context to create an initial scene but often falls short in faithfully representing object characteristics as specified in the prompts. To address this limitation, we introduce an Iterative Refinement Scheme that iteratively evaluates and refines box-level content to align them with their textual descriptions, recomposing objects as needed to ensure consistency. Our evaluation on complex prompts featuring multiple objects demonstrates a substantial improvement in recall compared to baseline diffusion models. This is further validated by a user study, underscoring the efficacy of our approach in generating coherent and detailed scenes from intricate textual inputs.